
MachineLearning-CheatSheet
Machine Learning CheatSheet | 机器学习概念、基础理论与常用算法速览
对于某给定的任务 T,在合理的性能度量方案 P 的前提下,某计算机程序可以自主学习任务 T 的经验 E;随着提供合适、优质、大量的经验 E,该程序对于任务 T 的性能逐步提高。即随着任务的不断执行,经验的累积会带来计算机性能的提升。

判别式模型(Discriminative Model )是直接对条件概率 p(y|x;θ) 建模。常见的判别式模型有 线性回归模型、线性判别分析、支持向量机 SVM、神经网络等。 生成式模型(Generative Model )则会对 x 和 y 的联合分布 p(x,y) 建模,然后通过贝叶斯公式来求得 p(yi|x),然后选取使得 p(yi|x) 最大的 yi,即:
简单来讲,前者不依赖于数据,能精确的解决问题;后者依赖于数据,目的是找到一个可接受的解。
经典排序或者搜索算法中的快排、堆排、二叉、B 树等等,它们的存在价值不依赖于输入数据:有固定的步骤和解法,对于不同的输入数据都能正常运行(可能对特殊的数据有时候性能会差一些);但是机器学习算法不同,你使用一个算法,做了一个模型,只是为了解决某个特定数据集下的某个需求;换一个数据和场合,这一套东西很可能就没有存在的意义了。
第一个 community,是把机器学习看作人工智能分支的一个群体,这群人的主体是计算机科学家。现在的机器学习研究者可能很少有人读过 1983 年出的 Machine Learning: An Artificial Intelligence Approach 这本书。这本书的出版标志着机器学习成为人工智能中一个独立的领域。它其实是一部集早期机器学习研究之大成的文集,收罗了若干先贤(例 如 Herbert Simon,那位把诺贝尔奖、图灵奖以及各种各样和他相关的奖几乎拿遍了的科学天才)的大作,主编是 Ryszard S. Michalski(此君已去世多年了,他可算是机器学习的奠基人之一)、Jaime G. Carbonell(此君曾是 Springer 的 LNAI 的总编)、Tom Mitchell(此君是 CMU 机器学习系首任系主任、著名教材的作者,机器学习界没人不知道他吧)。Machine Learning 杂志的创刊,正是这群人努力的结果。这本书值得一读。虽然技术手段早就日新月异了,但有一些深刻的思想现在并没有过时。各个学科领域总有不少东西,换了新装之后又粉墨登场,现在热火朝天的 transfer learning,其实就是 learning by analogy 的升级版。
人工智能的研究从以推理为重点到以知识为重点,再到以学习为重点,是有一条自然、清晰的脉络。人工智能出身的机器学习研究者,绝大部分 是把机器学习作为实现人工智能的一个途径,正如 1983 年的书名那样。他们关注的是人工智能中的问题,希望以机器学习为手段,但具体采用什么样的学习手段,是基于统计的、代数的、还是逻辑的、几何的,他们并不 care。这群人可能对统计学习目前 dominating 的地位未必满意。靠统计学习是不可能解决人工智能中大部分问题的,如果统计学习压制了对其他手段的研究,可能不是好事。这群人往往也不 care 在文章里 show 自己的数学水平,甚至可能是以简化表达自己的思想为荣。人工智能问题不是数学问题,甚至未必是依靠数学能够解决的问题。人工智能中许多事情的难处,往往在于我们不知道困难的本质在哪里,不知道问题在哪里。一旦问题清楚了,解决起来可能并不困难。
第二个 community,是把机器学习看作应用统计学的一个群体,这群人的主体是统计学家。和纯数学相比,统计学不太干净,不少数学家甚至拒绝承认统计学是数学。但如果和人工智能相比,统计学就太干净了,统计学研究的问题是清楚的,不象人工智能那样,连问题到底在哪里都不知道。在相当长时间里,统计学家和机器学习一直保持着距离。慢慢地,不少统计学家逐渐意识到,统计学本来就该面向应用,而机器学习天生就是一个很好的切入点。因为机器学习虽然用到各种各样的数学,但要分析大量数据中蕴涵的规律,统计学是必不可少的。统计学出身的机器学习研究者,绝大部分是把机器学习当作应用统计学。他们关注的是如何把统计学中的理论和方法变成可以在计算机上有效实现的算法,至于这样的算法对人工智能中的什么问题有用,他们并不 care。
这群人可能对人工智能毫无兴趣,在他们眼中,机器学习就是统计学习,是统计学比较偏向应用的一个分支,充其量是统计学与计算机科学的交叉。这群人对统计学习之外的学习手段往往是排斥的,这很自然,基于代数的、逻辑的、几何的学习,很难纳入统计学的范畴。
两个群体的文化和价值观完全不同。第一个群体认为好的工作,对于第二个群体而言可能觉得没有技术含量,但第一个群体可能恰恰认为,简单的才好,正因为很好地抓住了问题本质,所以问题变得容易解决。第二个群体欣赏的工作,第一个群体可能觉得是故弄玄虚,看不出他想解决什么人工智能问题,根本就不是在搞人工智 能、搞计算机,但别人本来也没说自己是在搞人工智能、搞计算机,本来就不是在为人工智能做研究。两个群体各有其存在的意义,应该宽容一点,不需要去互较什么短长。但是既然顶着 Machine Learning 这个帽子的不是一伙儿,而是两伙儿,那么要跟进的新人就要谨慎了,先搞清楚自己更喜欢哪伙儿。
- 加强概率与统计的基础课程,建议采用莫里斯 · 德格鲁特 (Morris H.DeGroot) 和马克 · 舍维什 (Mark J.Schervish) 合著的第四版《概率论与数理统计》(Probability and Statistics) 为教材。
- 在线性代数课程里,加强矩阵分析的内容。教材建议使用吉尔伯特 · 斯特朗 (Gilbert Strang) 的《线性代数导论》(Introduction to Linear Algebra)。吉尔伯特 · 斯特朗在麻省理工学院一直讲述线性代数,他的网上视频课程堪称经典。后续建议开设矩阵计算,采用特雷费森 · 劳埃德 (Trefethen N.Lloyd) 和戴维 · 鲍 (David Bau lll) 著作的《数值线性代数》(Numerical Linear Algebra) 为教科书。
- 开设机器学习课程。机器学习有许多经典的书籍,但大多不太适宜做本科生的教材。最近,麻省理工学院出版的约翰 · 凯莱赫 (John D.Kelleher) 和布瑞恩 · 麦克 · 纳米 (Brian Mac Namee) 等人著作的《机器学习基础之预测数据分析》(Fundamentals of Machine Learning for Predictive Data Analytics ),或者安得烈 · 韦伯 (Andrew R.Webb) 和基思 · 科普塞 (Keith D.Copsey) 合著的第三版《统计模式识别》(Statistical Pattern Recognition ) 比较适合作为本科生的教科书。同时建议课程设置实践环节,让学生尝试将机器学习方法应用到某些特定问题中。
- 开设数值优化课程,建议参考教材乔治 · 诺塞达尔 (Jorge Nocedal) 和史蒂芬 · 赖特 (Stephen J.Wright) 的第二版《数值优化》(Numerical Optimization ),或者开设数值分析,建议采用蒂莫西 · 索尔的《数值分析》(Numerical Analysis) 为教材。
- 加强算法课程,增加高级算法,比如随机算法,参考教材是迈克尔 · 米曾马克 (Michael Mitzenmacher) 和伊莱 · 阿普法 (Eli Upfal) 的《概率与计算: 随机算法与概率分析》(Probability and Computing: Randomized Algorithms and Probabilistic Analysis)。
- 在程序设计方面,增加或加强并行计算的内容。特别是在深度学习技术的执行中,通常需要 GPU 加速,可以使用戴维 · 柯克 (David B.Kirk) 和胡文美 (Wen-mei W.Hwu) 的教材 《大规模并行处理器编程实战》(第二版)(Programming Massively Parallel Processors:A Hands-on Approach,Second Edition );另外,还可以参考优达学城 (Udacity) 上英伟达 (Nvidia) 讲解 CUDA 计算的公开课。
在机器学习领域称为流形学习(Manifold learning),或降维问题(Dimension reduction)。如图 18 所示,数据是在三维空间给出的(B),每个点是 3 个坐标,看起来是三维数据;但其本质上位于三维空间的一张曲面上,即二维流形曲面上(A),其本征维数是 2。因此,可以将其一一映射到平面上(C)。
传统机器学习的流程一般由两个主要的模块组成。第一个模块称为特征工程,将原始输入数据(高维向量)变换为一个低维向量,即,用这个低维向量来作为表达输入数据的特征(或描述子,feature or descriptor)。不同的人有不同的方法来计算这个低维特征,称为特征抽取(Feature extraction),如图 19 显示了不同的图像特征抽取方法。各种计算的特征都有一定的实用范围,因此,有人就提出如何选择或组合各种特征得到更好的特征,这是特征工程的另一个子问题,称为特征选择(Feature selection)。针对三维形状分割,我们发现对三维局部块的众多描述子并不是串联起来一起使用更好,而是针对不同的形状的部位使用不同的描述子会更好,于是我们使用稀疏选择的方法来选择形状描述子用于形状分割,详细可见如下论文。
由于这种特征是通过人为设计的算法来得到的,因此这种特征称为人工特征(Hand-crafted features)。人工特征的抽取需要人们对输入数据的认知或者领域知识(Domain knowledge),因此在很多情况下会局限于人的经验和认知。
第二个模块称为预测模型,即选用什么样的预测方法来拟合给定的数据,我们前面所讲的拟合就是指这个过程。预测模型的目标就是希望学习到的模型在预测未知目标时越精确越好。一般要考虑模型的复杂度及精确度等因素。在机器学习领域有非常多的方法,这里不一一介绍。
拟合函数所带的参数的个数与样本数据的个数之间的差代表着这个拟合函数的“自由度”。网络越来越“深”后,拟合模型中的可调整参数的数量就非常大,通常能达到百万计甚至几十亿级。因此,层数很大的深度网络(模型过于复杂)能够表达一个自由度非常大的函数空间,甚至远高于目标函数空间(过完备空间),即自由度远大于 0。这样就很容易导致过拟合(Overfitting),
模型评估与正则化
机器学习的算法或者模型的分类有很多种,其中有一种分法把模型分为 Discriminative Modeling (判别模型)和 Generative Modeling (生成模型)两种。为了写起来方便我们以下简称 DM 和 GM。在一个基本的机器学习问题中,我们通常有输入 $x \in X$和输出 $y \in Y$两个部分,简单地来说,DM 关注于 $x$和 $y$的关系,或者说在给定某个 $x$的情况下所对应的 $y$应该满足的规律或分布,即评估对象是最大化条件概率$p(y|x)$并直接对其建模;而 GM 则试图描述 $x$和 $y$的联合分布,即模型评估对象是最大化联合概率$p(x,y)$并对其建模。其实两者的评估目标都是要得到最终的类别标签$Y$,而$Y=argmax p(y|x)$,不同的是判别式模型直接通过解在满足训练样本分布下的最优化问题得到模型参数,主要用到拉格朗日乘算法、梯度下降法,常见的判别式模型如最大熵模型、CRF、LR、SVM 等;而生成式模型先经过贝叶斯转换成$Y = argmax p(y|x) = argmax p(x|y)*p(y)$,然后分别学习$p(y)$和$p(x|y)$的概率分布,主要通过极大似然估计的方法学习参数,如 NGram、HMM、Naive Bayes。比较而言,判别式模型会更加灵活,而生成式模型一般需要将特征加入马尔科夫链。但是判别式模型需要有指导训练,而生成式模型可以无指导训练。
给定某系统的若干样本,求取该系统的参数,主要分为频率学派与贝叶斯学派。
频率学派
假定参数是某个或者某些未知的定值,求这些参数如何取值,能够使得某目标函数取得极大或者极小值,典型的代表有矩估计、MLE、MaxEnt 以及 EM。
贝叶斯学派
基于贝叶斯模型,假设参数本身是变化的,服从某个分布。求在这个分布约束下使得某目标函数极大/极小。大数据下是频率学派对于贝叶斯学派的一次有效逆袭。
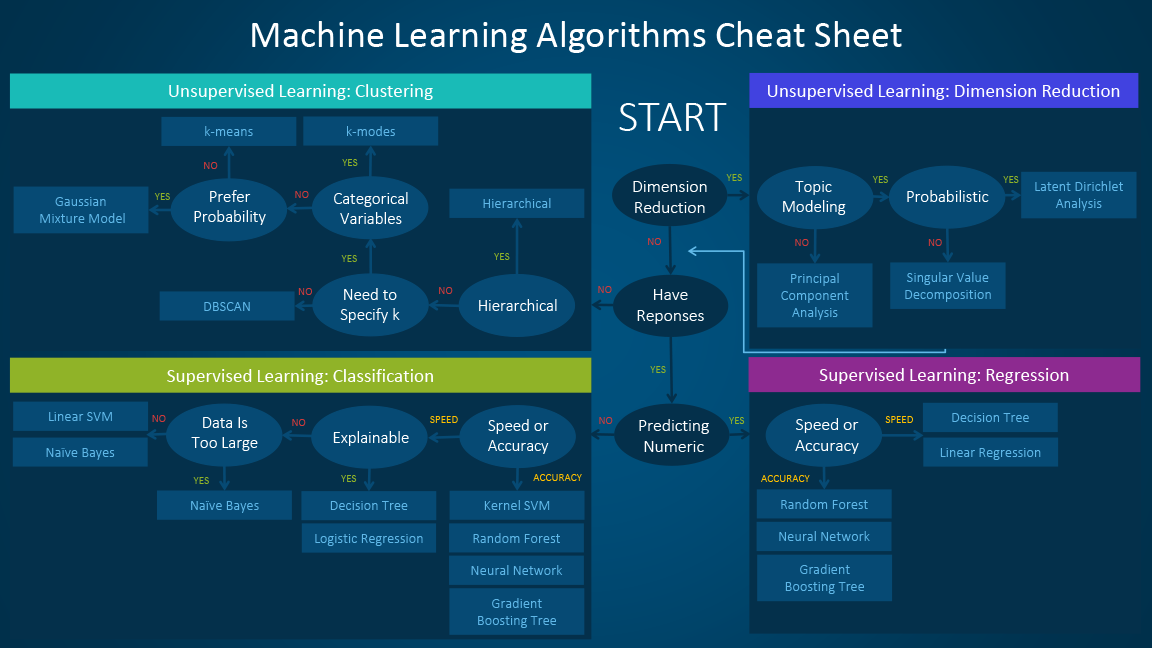
算法模型
判别式模型与生成式模型
有监督模型与无监督模型
数据拟合
在科学技术的各领域中,我们所研究的事件一般都是有规律(因果关系)的,即自变量集合 X 与应变量集合 Y 之间存在的对应关系通常用映射来描述(特殊情况:实数集合 R1 到实数集合 R2 之间的映射称为函数)。这样能根据映射(函数)规律作出预测并用于实际应用。
但是,很多工程问题难以直接推导出变量之间的函数表达式;或者即使能得出表达式,公式也十分复杂,不利于进一步的分析与计算。这时可以通过诸如采样、实验等方法获得若干离散的数据(称为样本数据点),然后根据这些数据,希望能得到这些变量之间的函数关系,这个过程称为数据拟合(Data fitting),在数理统计中也称为回归分析(Regression analysis)。
根据 Lagrange 插值定理,一定能找到一个次多项式来插值给定的个样本点。但如果较大,则这样得到的高次多项式很容易造成“过拟合”(Overfitting)。

Loss Function | 损失函数
Model Evaluation | 模型评估
Overfitting & Regularization | 过拟合与正则化
Classification: 分类
分类问题的核心即是希望能够在特征空间内寻找一条决策边界线或者是一条曲线,来将特征空间里区分为我们想要的类别。在分类算法领域,最常见的即是 Logistic 回归、决策树以及 SVM。
Condition: A Not A
Test says “A” True positive (TP) | False positive (FP)
----------------------------------
Test says “Not A” False negative (FN) | True negative (TN)
-
TP– 将正类预测为正类数;
-
FN– 将正类预测为负类数;
-
FP– 将负类预测为正类数;
-
TN– 将负类预测为负类数;
-
准确率(Precision,$P$)定义为被正确预测为正例的数目占所有被预测为正例的数目的比重: $$ P = \frac{T_p}{T_p + F_p} $$
-
召回率(Recall,$R$)定义为被正确预测为正例的数目占所有实际正例数目的比重: $$ R = \frac{T_p}{T_p + F_n} $$
-
F1 则是相对综合的评价值,定义为了准确率与召回率的调和平均数: $$ F1 = 2 \frac{P * R}{P + R} $$
当量化算法的好坏时,首先需要看以下几个指标:
- True Positives(TP):即实际为正例且被分类器划分为正例的样本数;
- False Positives(FP):即实际为负例但被分类器划分为正例的样本数;
- True Negatives(TN):即实际为负例且被分类器划分为负例的样本数;
- False Negatives(FN):即实际为负例但被分类器划分为负例的样本数;
一般进行评价时,有两个指标:(1)准确率
$$ accuracy = \frac{TP+TN}{P+N} $$
就是被分队的样本除以所有的样本数,通常来说,准确率越高,分类器越好。(2)召回率
$$ recall = \frac{TP}{TP+FN} $$
召回率是覆盖面的度量,度量有多少个正例被分为正例。
Regression: 回归模型
$$ \begin{align*} & h*{\theta}(x) = \theta_0 + \theta_1 x_1 + \theta_2 x_2 \ & h*{\theta}(x) = \sum_{i=0}^n \theta_i x_i = \theta^Tx \end{align*} $$
Algorithms: 算法
算法基本上从功能或者形式上来分类。比如,基于树的算法,神经网络算法。这是一个很有用的分类方式,但并不完美。因为有许多算法可以轻易地被分到两类中去,比如说 Learning Vector Quantization 就同时是神经网络类的算法和基于实例的方法。正如机器学习算法本身没有完美的模型一样,算法的分类方法也没有完美的。
Grouped By Learning Style(根据学习风格分类)
Supervised Learning
输入数据被称为训练数据,并且有已知的结果或被标记。比如说一封邮件是否是垃圾邮件,或者说一段时间内的股价。模型做出预测,如果错了就会被修正,这个过程一直持续到对于训练数据它能够达到一定的正确标准。问题例子包括分类和回归问题,算法例子包括逻辑回归和反向神经网络。

有监督学习的通俗例子可以以人类认知月亮的过程为例,小时候会认为黑夜里天空中明亮的圆盘状物体为月亮,后来随着时间的推移,发现圆盘状这个特点并非一个决定性因素。
Unsupervised Learning
输入数据没有被标记,也没有确定的结果。模型对数据的结构和数值进行归纳。问题例子包括 Association rule learning 和聚类问题,算法例子包括 Apriori 算法和 K-均值算法。

Semi-Supervised Learning

输入数据是被标记的和不被标记的数据的混合,有一些预测问题但是模型也必须学习数据的结构和组成。问题例子包括分类和回归问题,算法例子基本上是无监督学习算法的延伸。
Grouped By Similarity(根据算法相似度分类)
Regression Algorithms

Regression is concerned with modelling the relationship between variables that is iteratively refined using a measure of error in the predictions made by the model.
Regression methods are a workhorse of statistics and have been cooped into statistical machine learning. This may be confusing because we can use regression to refer to the class of problem and the class of algorithm. Really, regression is a process.
The most popular regression algorithms are:
- Ordinary Least Squares Regression (OLSR)
- Linear Regression
- Logistic Regression
- Stepwise Regression
- Multivariate Adaptive Regression Splines (MARS)
- Locally Estimated Scatterplot Smoothing (LOESS)
Instance-based Algorithms

Such methods typically build up a database of example data and compare new data to the database using a similarity measure in order to find the best match and make a prediction. For this reason, instance-based methods are also called winner-take-all methods and memory-based learning. Focus is put on representation of the stored instances and similarity measures used between instances.
The most popular instance-based algorithms are:
- k-Nearest Neighbour (kNN)
- Learning Vector Quantization (LVQ)
- Self-Organizing Map (SOM)
- Locally Weighted Learning (LWL)
Regularization Algorithms

An extension made to another method (typically regression methods) that penalizes models based on their complexity, favoring simpler models that are also better at generalizing.
I have listed regularization algorithms separately here because they are popular, powerful and generally simple modifications made to other methods.
The most popular regularization algorithms are:
- Ridge Regression
- Least Absolute Shrinkage and Selection Operator (LASSO)
- Elastic Net
- Least-Angle Regression (LARS)
Decision Tree Algorithms

Decisions fork in tree structures until a prediction decision is made for a given record. Decision trees are trained on data for classification and regression problems. Decision trees are often fast and accurate and a big favorite in machine learning.
The most popular decision tree algorithms are:
- Classification and Regression Tree (CART)
- Iterative Dichotomiser 3 (ID3)
- C4.5 and C5.0 (different versions of a powerful approach)
- Chi-squared Automatic Interaction Detection (CHAID)
- Decision Stump
- M5
- Conditional Decision Trees
Bayesian Algorithms

The most popular Bayesian algorithms are:
- Naive Bayes
- Gaussian Naive Bayes
- Multinomial Naive Bayes
- Averaged One-Dependence Estimators (AODE)
- Bayesian Belief Network (BBN)
- Bayesian Network (BN)
Clustering Algorithms

Clustering methods are typically organized by the modelling approaches such as centroid-based and hierarchal. All methods are concerned with using the inherent structures in the data to best organize the data into groups of maximum commonality.
The most popular clustering algorithms are:
- k-Means
- k-Medians
- Expectation Maximisation (EM)
- Hierarchical Clustering
Artificial Neural Network Algorithms

Artificial Neural Networks are models that are inspired by the structure and/or function of biological neural networks.
They are a class of pattern matching that are commonly used for regression and classification problems but are really an enormous subfield comprised of hundreds of algorithms and variations for all manner of problem types.
Note that I have separated out Deep Learning from neural networks because of the massive growth and popularity in the field. Here we are concerned with the more classical methods.
The most popular artificial neural network algorithms are:
- Perceptron
- Back-Propagation
- Hopfield Network
- Radial Basis Function Network (RBFN)
Deep Learning Algorithms

They are concerned with building much larger and more complex neural networks, and as commented above, many methods are concerned with semi-supervised learning problems where large datasets contain very little labelled data.
The most popular deep learning algorithms are:
- Deep Boltzmann Machine (DBM)
- Deep Belief Networks (DBN)
- Convolutional Neural Network (CNN)
- Stacked Auto-Encoders
Support Vector Machines
Ensemble Algorithms

Ensemble methods are models composed of multiple weaker models that are independently trained and whose predictions are combined in some way to make the overall prediction.
Much effort is put into what types of weak learners to combine and the ways in which to combine them. This is a very powerful class of techniques and as such is very popular.
- Boosting
- Bootstrapped Aggregation (Bagging)
- AdaBoost
- Stacked Generalization (blending)
- Gradient Boosting Machines (GBM)
- Gradient Boosted Regression Trees (GBRT)
- Random Forest
Markov

Links
模型评估与正则化
VC 维
VC 维是一类函数,描述的是这类函数能够把多少个样本的所有组合都划分开来。当你选定了一个模型以及它对应的特征之后,你是大概可以知道这组模型和特征的选择能够对多大的数据集进行分类的。此外,一类函数的 VC 维的大小,还可以反应出这类函数过拟合的可能性。
最优化理论
绝大多数机器学习问题的解决,都可以划分为两个阶段:建模和优化。所谓建模就是后面我们会提到的各种用模型来描述问题的方法,而优化就是建模完成之后求得模型的最优参数的过程。机器学习中常用的模型有很多,但背后用到的优化方法却并没有那么多。换句话说,很多模型都是用的同一套优化方法,而同一个优化方法也可以用来优化很多不同模型。对各种常用优化方法的和思想有所有了解非常有必要,对于理解模型训练的过程,以及解释各种情况下模型训练的效果都很有帮助。这里面包括最大似然、最大后验、梯度下降、拟牛顿法、L-BFGS 等。
有/无监督学习
在目前的工业实践中,有监督学习的应用面仍然是最广泛的,这是因为我们现实中遇到的很多问题都是希望对某个事物的某个属性做出预测,而这些问题通过合理的抽象和变换,都可以转化为有监督学习的问题。
贝叶斯模型
朴素贝叶斯有很强的假设,这个假设很多问题都不满足,模型结构也很简单,所以其优化效果并不是最好的。
分类与回归
在掌握了机器学习模型的基础流程之后,需要学习两种最基础的模型形式:线性模型和树形模型,分别对应着线性回归/逻辑回归和决策回归/分类树。