
Data-centric AI
Data-centric AI
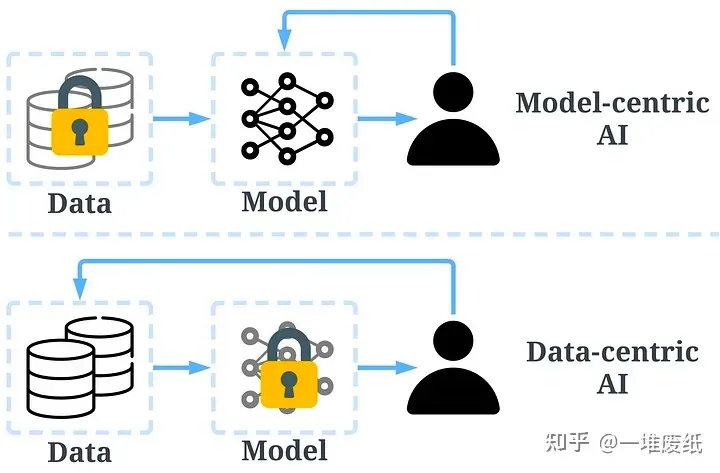
Data-centric AI is the discipline of systematically engineering the data used to build an AI system. — Andrew Ng
传统的搭建 AI 模型的方法主要是去迭代模型,数据相对固定。比如,我们通常会聚焦于几个基准数据集,然后设计各式各样的模型去提高预测准确率。这种方式我们称作以模型为中心(model-centric)。然而,model-centric 没有考虑到实际应用中数据可能出现的各种问题,例如不准确的标签,数据重复和异常数据等。准确率高的模型只能确保很好地「拟合」了数据,并不一定意味着实际应用中会有很好的表现。与 model-centric 不同,Data-centric 更侧重于提高数据的质量和数量。也就是说 Data-centric AI 关注的是数据本身,而模型相对固定。采用 Data-centric AI 的方法在实际场景中会有更大的潜力,因为数据很大程度上决定了模型能力的上限。
需要注意的是,「Data-centric」与「Data-driven」(数据驱动),是两个根本上不同的概念。后者仅强调使用数据去指导 AI 系统的搭建,这仍是聚焦于开发模型而不是去改变数据。
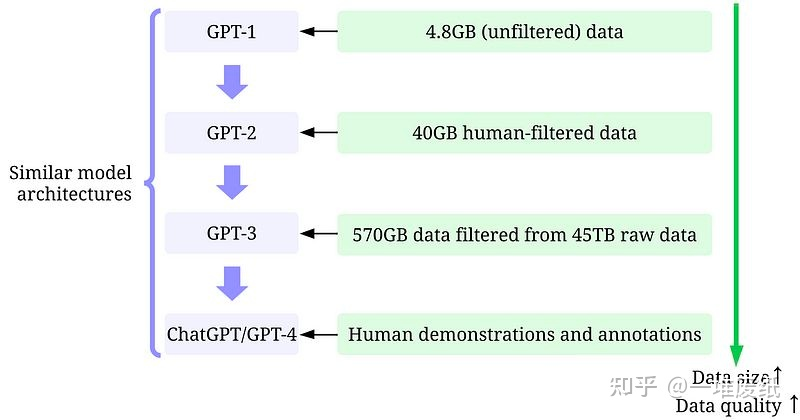
以往大家研究的重点都在模型。但如今,经过了多年的研究,模型设计已经相对比较成熟,特别是在 Transformer 出现之后(目前我们似乎还看不到 Transformer 的上限)。从 GPT-1 到 ChatGPT/GPT-4,所用的训练数据大体经历了以下变化:小数据(小是对于 OpenAI 而言,对普通研究者来说也不小了)->大一点的高质量数据->更大一点的更高质量数据->高质量人类(指能通过考试的标注者)标注的高质量数据。模型设计并没有很显著的变化(除了参数更多以顺应更多的数据),这正符合了 Data-centric AI 的理念。从 ChatGPT/GPT-4 的成功,我们可以发现,高质量的标注数据是至关重要的。OpenAI 对数据和标签质量的重视程度令人发指。

从另一个角度来看,现在的 ChatGPT/GPT-4 模型已经足够强大,强大到我们只需要调整提示(推理数据)来达到各种目的,而模型则保持不变。例如,我们可以提供一段长文本,再加上特定的指令,比方说「summarize it」或者「TL;DR」,模型就能自动生成摘要。在这种新兴模式下,Data-centric AI 变得更为重要,以后很多 AI 打工人可能再也不用训练模型了,只用做提示工程(prompt engineering)。
因此,在大模型时代,Data-centric AI 的理念将越来越重要。