压缩
常用压缩算法

gzip
gzip 是基于 DEFLATE 的算法,它是 LZ77 和 Huffman 编码 的结合。DEFLATE 的目的是为了取代 LZW 和其他受专利保护的数据压缩算法,因为这些算法在当时限制了压缩和其他流行的存档器的可用性(Wikipedia)。我们通常使用 tar -czf 命令来进行打包并且压缩的操作,z 参数正是使用 gzip 的方式来进行压缩。DEFLATE 标准(RFC1951)是一个被广泛使用的无损数据压缩标准。它的压缩数据格式由一系列块构成,对应输入数据的块,每一块通过 LZ77 (基于字典压缩,就是将最高概率出现的字母以最短的编码表示)算法和 Huffman 编码进行压缩,LZ77 算法通过查找并替换重复的字符串来减小数据体积。
文件格式如下:
- 一个 10 字节的报头,包含一个魔数 (1f 8b),压缩方法 (比如 08 用于 DEFLATE),1 字节的 header flags,4 字节的时间戳,compression flags 和操作系统 ID。
- 可选的额外 headers,包括原始文件名、注释字段、“extra” 字段和 header 的 CRC-32 校验码 lower half 。
- DEFLATE 压缩主体。
- 8 字节的 footer,包含 CRC-32 校验以及原始未压缩的数据。
我们可以看到 gzip 是主要基于 CRC 和 Huffman LZ77 的 DEFLATE 算法,这也是后面 ISA-L 库的优化目标。
Brotli
Alakuijala 和 Szabadka 在 2013-2016 年完成了 Brotli 规范,该数据格式旨在进一步提高压缩比,它在优化网站速度上有大量应用。Brotli 规范的正式验证是由 Mark Adler 独立实现的。Brotli 是一个用于数据流压缩的数据格式规范,它使用了通用的 LZ77 无损压缩算法、Huffman 编码和二阶上下文建模(2nd order context modelling)的特定组合。大家可以参考这篇论文 查看其实现原理。
因为语言本身的特性,基于上下文的建模方法 (Context Modeling)可以得到更好的压缩比,但由于它的性能问题很难普及。当前比较流行的突破算法有两种:
- ANS:Zstd, lzfse
- Context Modeling:Brotli, bz2
Zstd
Zstd 全称叫 Zstandard,是一个提供高压缩比的快速压缩算法,主要实现的编程语言为 C,是 Facebook 的 Yann Collet 于 2016 年发布的,Zstd 采用了有限状态熵(Finite State Entropy,缩写为 FSE)编码器。该编码器是由 Jarek Duda 基于 ANS 理论开发的一种新型熵编码器,提供了非常强大的压缩速度/压缩率的折中方案(事实上也的确做到了“鱼”和“熊掌”兼得)。Zstd 在其最大压缩级别上提供的压缩比接近 lzma、lzham 和 ppmx,并且性能优于 lza 或 bzip2。Zstandard 达到了 Pareto frontier(资源分配最佳的理想状态),因为它解压缩速度快于任何其他当前可用的算法,但压缩比类似或更好。
对于小数据,它还特别提供一个载入预置词典的方法优化速度,词典可以通过对目标数据进行训练从而生成。
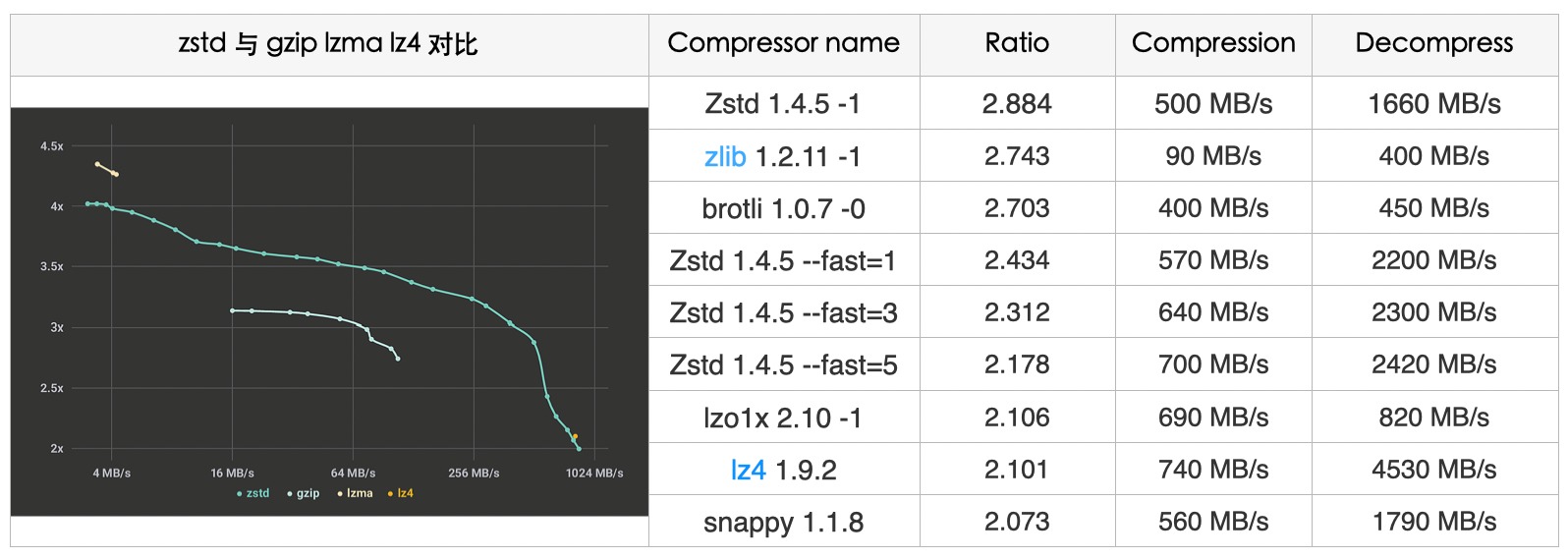
压缩级别可以通过 –fast 指定,提供更快的压缩和解压缩速度,相比级别 1 会导致压缩比率的一些损失,如上表所示。Zstd 可以用压缩速度换取更强的压缩比。它是可配置的小增量,在所有设置下,解压缩速度都保持不变,这是大多数 LZ 压缩算法(如 zlib 或 lzma)共享的特性。
- 我们采用 Zstd 默认的参数进行了测试,压缩时间 8.471s 仅为原来的 11.266%,提升了 88.733%
- 解压时间 3.211 仅为原来的 29.83%,提升约为 70.169%。
- 同时压缩率也从 2.548 提升到了 2.621。
LZ4
LZ4 是一种无损压缩算法,每核提供大于 500 MB/s 的压缩速度(大于 0.15 Bytes/cycle)。它的特点是解码速度极快,每核速度为多 GB/s( 约 1 Bytes/cycle )。从上面的 Zstd 的 Benchmark 对比中,我们看到了 LZ4 算法效果十分出众,因此我们也对 LZ4 进行了对比,LZ4 更加侧重压缩解压速度,尤其是解压缩的速度,压缩比并不是它的强项,它默认支持 1-9 的压缩参数,我们分别进行了测试。
LZ4 使用默认参数压缩速度十分优秀,比 Zstd 快很多,但是压缩比并不高,比 Zstd 压缩后多了 206 MB,足足多了 46%,这就意味着更多的数据传输时间和磁盘空间占用。即使是最大的压缩比也并不高,仅仅从 1.79 提升到了 2.11,但是耗时却从 5s 提升到了 51s。通过对比,LZ4 的确在压缩率上并不是最优秀的方案,在 2.x 级别压缩率上基本上时间优势荡然无存,而且还有一点,就是 LZ4 目前官方并没有对多核 CPU 并行压缩的支持,所以在后续的对比中,LZ4 丧失了压缩解压缩速度的优势。
Pigz
Pigz 的作者 Mark Adler,同时也是 Info-ZIP 的 zip 和 unzip、GNU 的 gzip 和 zlib 压缩库的共同作者,并且是 PNG 图像格式开发工作的参与者。Pigz 是 gzip 的并行实现的缩写,它主要思想就是利用多个处理器和核。它将输入分成 128 KB 的块,每个块都被并行压缩。每个块的单个校验值也是并行计算的。它的实现直接使用了 zlib 和 pthread 库,比较易读,而且重要的是兼容 gzip 的格式。Pigz 使用一个线程(主线程)进行解压缩,但可以创建另外三个线程进行读、写和检查计算,所以在某些情况下可以加速解压缩。
一些博客在 i7 4790K 这样的家用 PC 平台中测试 Pigz 的压缩性能时,并没有十分高的速度,但在我们真机验证的数据中提升要明显很多。通过测试,它的压缩时间执行速度只用了 1.768s,充分发挥了我们平台物理机的性能,User 时间(CPU 时间之和)一共使用了 1m30.569s,这和前面的使用 gzip 单线程的方式速度几乎是一个级别。压缩率 2.5488 和正常使用 tar -czf 几乎相差不多。
ISA-L Acceleration Version
ISA-L 是一套在 IA 架构上加速算法执行的开源函数库,目的在于解决存储系统的计算需求。ISA-L 使用的是 BSD-3-Clause License ,因此在商业上同样可以使用。
使用过 SPDK(Storage Performance Development Kit )或者 DPDK(Data Plane Development Kit)应该也听说过 ISA-L ,前者使用了 ISA-L 的 CRC 部分,后者使用了它的压缩优化。ISA-L 通过使用高效的 SIMD (Single Instruction, Multiple Data)指令和专用指令,最大化的利用 CPU 的微架构来加速存储算法的计算过程。ISA-L 底层函数都是使用手工汇编代码编写,并在很多细节上做了调优(现在经常要考虑 ARM 平台,本文中所提及的部分指令在该平台支持度不高甚至是不支持)。
ISA-L 对压缩算法主要做了 CRC、DEFLATE 和 Huffman 编码的优化实现,官方的数据指出 ISA-L 相比 zlib-1 有 5 倍的速度提升。举例来说,不少底层的存储开源软件实现的 CRC 都使用了查表法,代码中存储或者生成了一个 CRC value 的表格,然后计算过程中查询值,ISA-L 的汇编代码中包含了无进位乘法指令 PCLMULQDQ 对两个 64 位数做无进位乘法,最大化 intel PCLMULQDQ 指令的吞吐量来优化 CRC 的性能。更好的情况是 CPU 支持 AVX-512,就可以使用 VPCLMULQDQ(PCLMULQDQ 在 EVEX 编码的 512 bit 版本实现)等其它优化指令集(查看是否支持的方式见“附录”)。
Pzstd
通过 Pigz 的测试,我们就在想,是否 Zstd 这样优秀的算法也可以支持并行呢,在官方的 Repo 中,我们十分惊喜地发现了一个“宝藏”。Pzstd 是 C++11 实现的并行版本的 Zstandard (Zstd 也在这之后加入了多线程的支持),类似于 Pigz 的工具。它提供了与 Zstandard 格式兼容的压缩和解压缩功能,可以利用多个 CPU 核心。它将输入分成相等大小的块,并将每个块独立压缩为 Zstandard 帧。然后将这些帧连接在一起以产生最终的压缩输出。Pzstd 同样支持文件的并行解压缩。解压缩使用 Zstandard 压缩的文件时,PZstandard 在一个线程中执行 IO,而在另一个线程中进行解压缩。
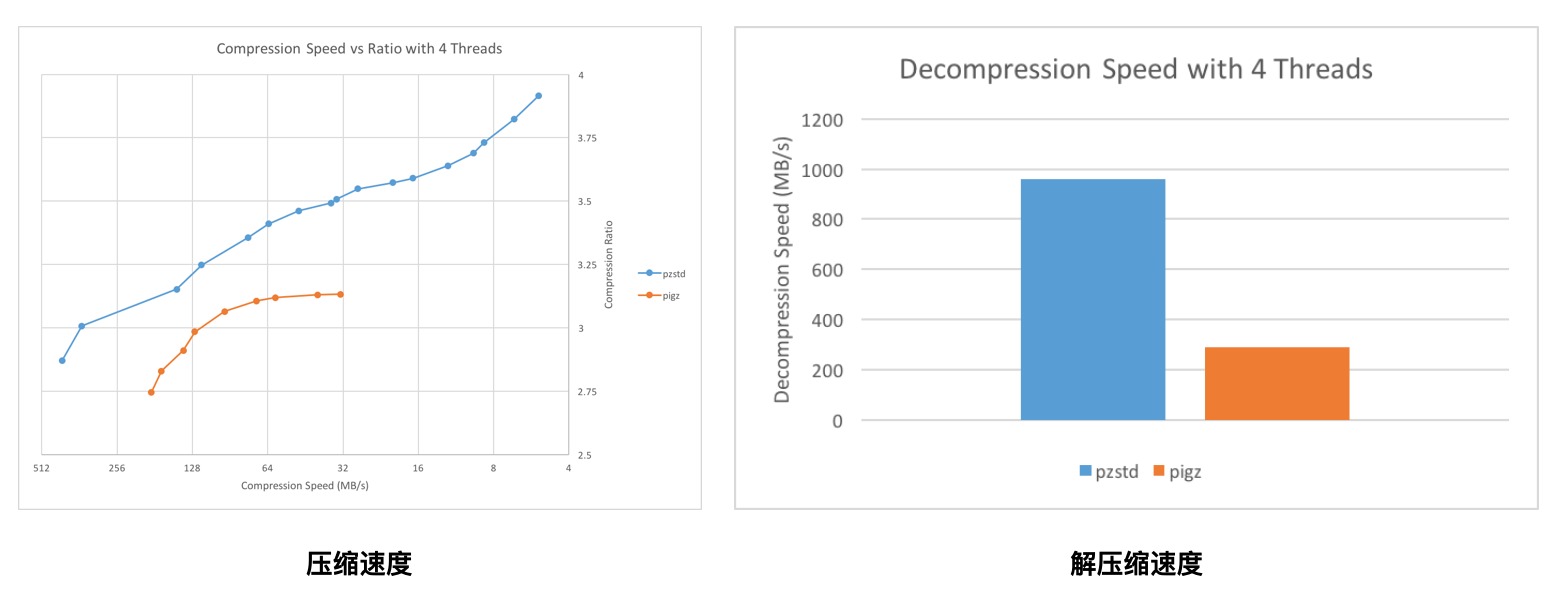
下图是和 Pigz 的压缩和解压缩速度对比,来自官方 Github 仓库(机器配置为:Intel Core i7 @ 3.1 GHz, 4 threads),效果比 Pigz 还要出色,具体对比数据见下文: