
01.复杂性定义
复杂性定义
复杂性与软件系统的结构有关,这使它很难理解和修改系统。复杂性可以采取多种形式。例如,可能很难理解一段代码是如何工作的。可能需要花费很多精力才能实现较小的改进,或者可能不清楚必须修改系统的哪些部分才能进行改进;如果不引入其他错误,可能很难修复。如果一个软件系统难以理解和修改,那就很复杂;如果很容易理解和修改,那就很简单。在复杂的系统中,要实施甚至很小的改进都需要大量的工作;在一个简单的系统中,可以用更少的精力实现更大的改进。
值得注意的是,复杂性不一定与系统的整体大小或功能有关;当然,实际上几乎所有大型复杂的软件系统都很难使用,因此它们也符合我对复杂性的定义,但这不一定是事实。小型而不复杂的系统也可能非常复杂。复杂性取决于代码库中最常打交道的那一部分,如果系统中有一些非常复杂的部分,但是几乎不需要触摸这些部分,那么它们对系统的整体复杂性不会有太大影响。可以用粗略的数学方法来表征:
$$ C=\sum_{p} c_{p} t_{p} $$
系统的总体复杂度(C)由每个部分的复杂度(cp)乘以开发人员在该部分上花费的时间(tp)加权。在一个永远不会被看到的地方隔离复杂性几乎和完全消除复杂性一样好。
业务复杂度与技术复杂度
业务复杂度对应了客户的业务需求,因而这种复杂度往往会随着需求规模的增大而增加,这也是本部分讨论复杂性的核心。技术复杂度来自需求的质量属性,诸如安全、高性能、高并发、高可用性等需求,为软件设计带来了极大的挑战,让人痛苦的是这些因素彼此之间可能又互相矛盾、互相影响。技术复杂度与业务复杂度并非完全独立,二者混合在一起产生的化合作用更让系统的复杂度变得不可预期,难以掌控
技术复杂度则来自于对软件系统运行的质量需求,包括安全、高性能、高并发、高可用和高扩展性。系统安全性要求对访问进行控制,无论是加密还是认证和授权,都需要为整个系统架构添加额外的间接层。不仅对访问的低延迟产生影响,还极大提升了系统代码复杂度;为了让后端系统能具备高扩展性和弹性,要求所有系统的设计必须是无状态的;为了提升用户端访问体验,后端需要增添离线任务对数据加工、异构、预热、预缓存,以实现用空间换时间,降低实时接口的逻辑复杂度来降低请求的延迟。然而最让开发者更抓狂的是这些技术需求彼此又是相互影响甚至相互矛盾,在一些复杂流程并要求高响应的业务场景,如下单、秒杀等,会将一个同步的访问请求拆分为多级步骤的异步请求,再通过引入消息中间件对这些请求进行整合和分散处理,这种分离一方面增加了系统架构的复杂性,另一方面也因为引入了更多的资源,使得系统的高可用面临挑战,并增加了维护数据一致性的难度。而且技术复杂度与业务复杂度并非孤立,二者复杂度因子混合在一起产生的负作用更让系统的复杂度变得不可预期,难以掌控,就好比氢气和氯气混合在一起遇到光亮发生爆炸一样。
Complexity Symptoms | 复杂性的症状
复杂性通过以下三种段落中描述的三种一般方式体现出来。这些表现形式中的每一个都使执行开发任务变得更加困难。
变更放大(Change amplification)
复杂性的第一个征兆是,看似简单的变更需要在许多不同地方进行代码修改。例如,考虑一个包含几个页面的网站,每个页面显示带有背景色的横幅。在许多早期的网站中,颜色是在每个页面上明确指定的,如下图(a)所示。为了更改此类网站的背景,开发人员可能必须手动修改每个现有页面;对于拥有数千个页面的大型网站而言,这几乎是不可能的。幸运的是,现代网站使用的方法类似于下图(b),其中横幅颜色一次在中心位置指定,并且所有各个页面均引用该共享值。使用这种方法,可以通过一次修改来更改整个网站的标题颜色。
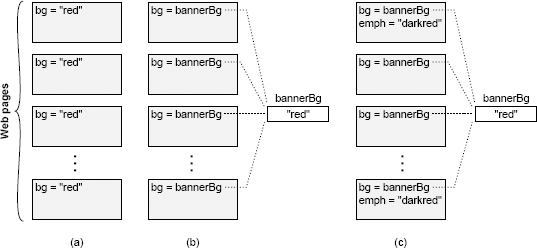
上图中网站中的每个页面都显示一个彩色横幅。在(a)中,横幅的背景色在每页中都明确指定。在(b)中,共享变量保留背景色,并且每个页面都引用该变量。在(c)中,某些页面会显示其他用于强调的颜色,即横幅背景颜色的暗色;如果背景颜色改变,则强调颜色也必须改变。
认知负荷(Cognitive load)
复杂性的第二个症状是认知负荷,这是指开发人员需要多少知识才能完成一项任务。较高的认知负担意味着开发人员必须花更多的时间来学习所需的信息,并且由于错过了重要的东西而导致错误的风险也更大。例如,假设 C 中的一个函数分配了内存,返回了指向该内存的指针,并假定调用者将释放该内存。这增加了使用该功能的开发人员的认知负担。如果开发人员无法释放内存,则会发生内存泄漏。如果可以对系统进行重组,以使调用者不必担心释放内存(分配内存的同一模块也负责释放内存),它将减少认知负担。
系统设计人员有时会假设可以通过代码行来衡量复杂性。他们认为,如果一个实现比另一个实现短,那么它必须更简单;如果只需要几行代码就可以进行更改,那么更改必须很容易。但是,这种观点忽略了与认知负荷相关的成本。我已经看到了仅允许使用几行代码编写应用程序的框架,但是要弄清楚这些行是什么极其困难。有时,需要更多代码行的方法实际上更简单,因为它减少了认知负担。
未知的未知(Unknown unknowns)
复杂性的第三个症状是,必须修改哪些代码才能完成任务,或者开发人员必须获得哪些信息才能成功地执行任务,这些都是不明显的。上图(c)说明了这个问题。网站使用一个中心变量来确定横幅的背景颜色,所以它看起来很容易改变。但是,一些 Web 页面使用较暗的背景色来强调,并且在各个页面中明确指定了较暗的颜色。如果背景颜色改变,那么强调的颜色必须改变以匹配。不幸的是,开发人员不太可能意识到这一点,所以他们可能会更改中央 bannerBg 变量而不更新强调颜色。即使开发人员意识到这个问题,也不清楚哪些页面使用了强调色,因此开发人员可能必须搜索 Web 站点中的每个页面。
总结
在复杂性的三种表现形式中,未知的未知是最糟糕的。一个未知的未知意味着你需要知道一些事情,但是你没有办法找到它是什么,甚至是否有一个问题。你不会发现它,直到错误出现后,你做了一个改变。更改放大是令人恼火的,但是只要清楚哪些代码需要修改,一旦更改完成,系统就会工作。同样,高的认知负荷会增加改变的成本,但如果明确要阅读哪些信息,改变仍然可能是正确的。对于未知的未知,不清楚该做什么,或者提出的解决方案是否有效。唯一确定的方法是读取系统中的每一行代码,这对于任何大小的系统都是不可能的。甚至这可能还不够,因为更改可能依赖于一个从未记录的细微设计决策。
良好设计的最重要目标之一就是使系统显而易见。这与高认知负荷和未知未知数相反。在一个显而易见的系统中,开发人员可以快速了解现有代码的工作方式以及进行更改所需的内容。一个显而易见的系统是,开发人员可以在不费力地思考的情况下快速猜测要做什么,同时又可以确信该猜测是正确的。