
01.基础概念
元模型
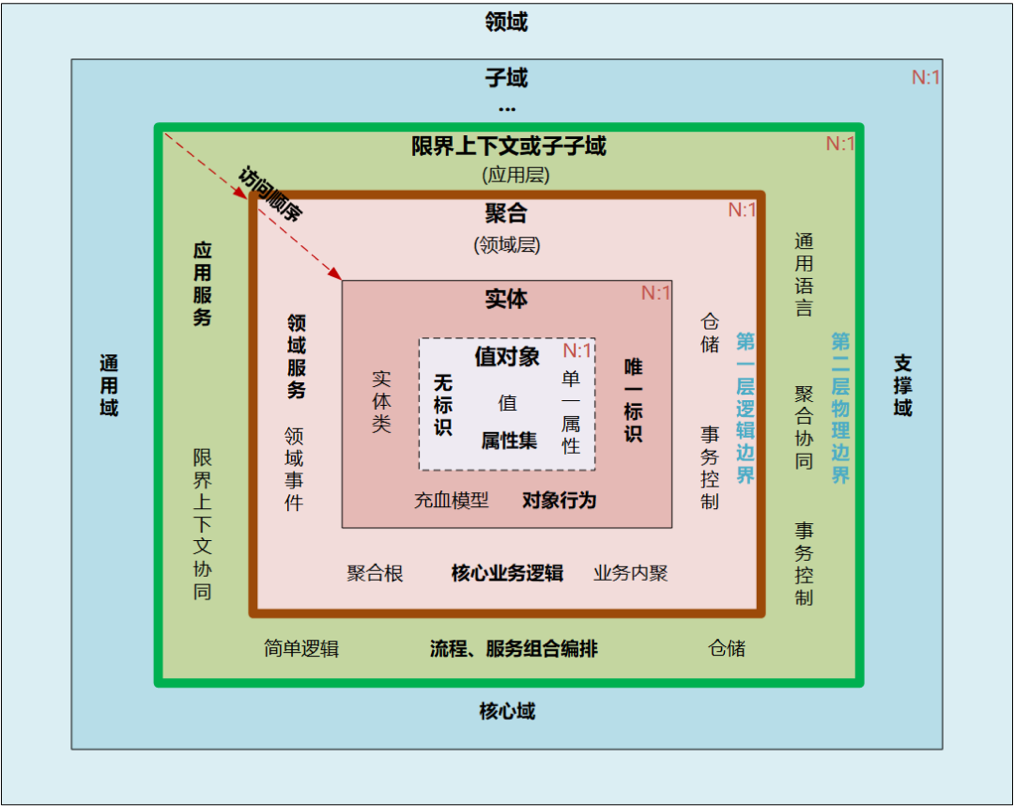
在 DDD 中,我们可以把名词分为战术设计(Tactic DDD)与战略设计(Strategic DDD)两类,战略设计更大一些,偏宏观,你可以理解为公司高层在讨论的业务和技术方向,各个团队或者产品的分工和配合;而战术设计则相对小很多,主要集中在一个 BoundedContext 内部,比如如何设计 DDD 那些 Entity,Service,Repository 等,外加可能的应用开发的技术选型,可以说更关注技术层面。战术设计与战略设计的相关名词划分如下:
-
战术设计(Tactic DDD):Entity, Value Object; Aggregate, Root Entity, Service, Domain Event; Factory, Repository。
-
战略设计(Strategic DDD):Bounded Context, Context Map; Published Language, Shared Kernel, Open Host Service, Customer-Supplier, Conformist, Anti Corruption Layer (context relationship types)。
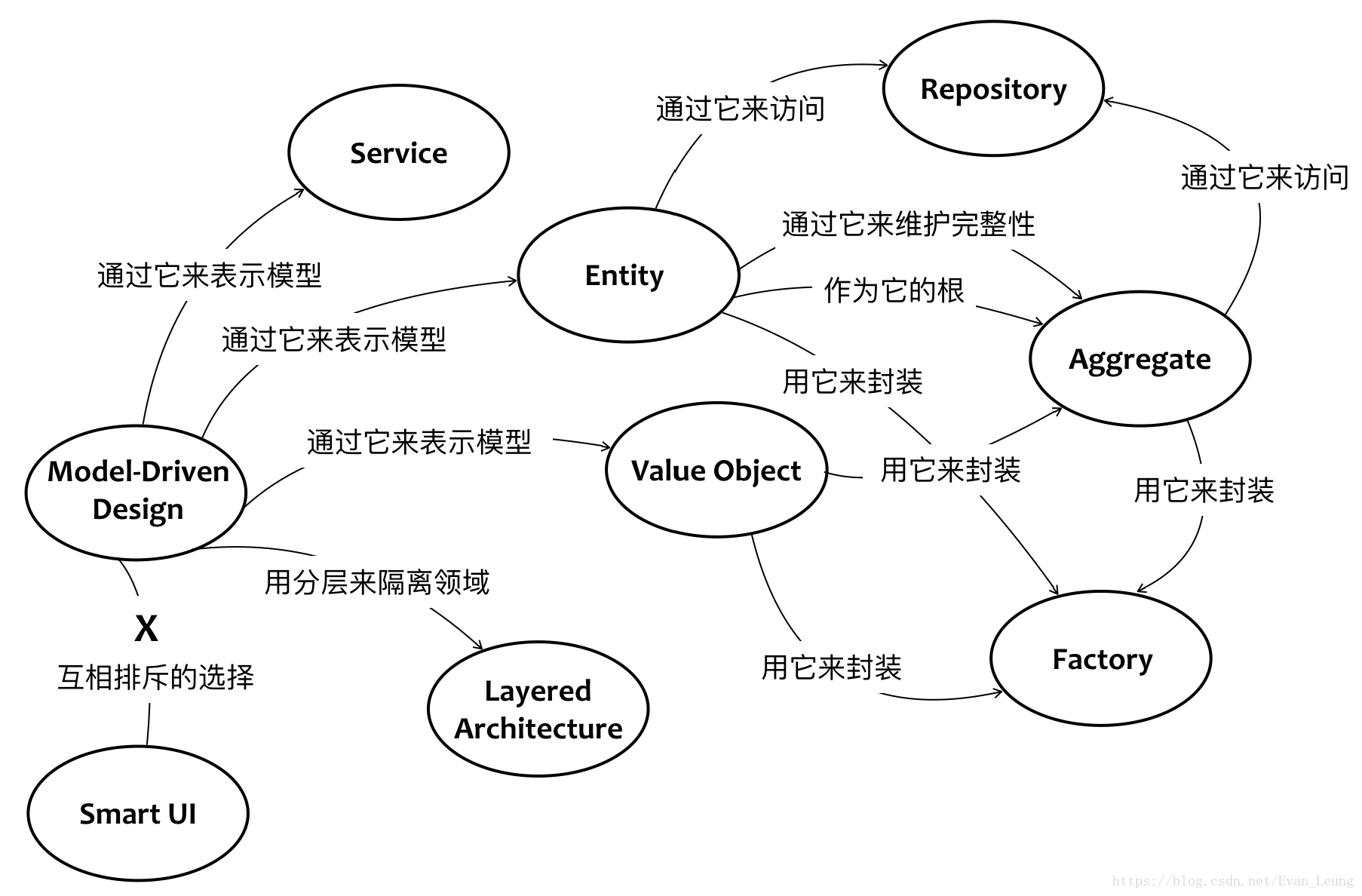
领域驱动设计围绕着领域模型进行设计,通过分层架构(Layered Architecture)将领域独立出来。表示领域模型的对象包括:实体、值对象和领域服务,领域逻辑都应该封装在这些对象中。这一严格的设计原则可以避免业务逻辑渗透到领域层之外,导致技术实现与业务逻辑的混淆。在领域驱动设计的演进中,又引入了领域事件来丰富领域模型。聚合是一种边界,它可以封装一到多个实体与值对象,并维持该边界范围之内的业务完整性。在聚合中,至少包含一个实体,且只有实体才能作为聚合根(Aggregate Root)。注意,在领域驱动设计中,没有任何一个类是单独的聚合,因为聚合代表的是边界概念,而非领域概念。在极端情况下,一个聚合可能有且只有一个实体。
工厂和资源库都是对领域对象生命周期的管理。前者负责领域对象的创建,往往用于封装复杂或者可能变化的创建逻辑;后者则负责从存放资源的位置(数据库、内存或者其他 Web 资源)获取、添加、删除或者修改领域对象。领域模型中的资源库不应该暴露访问领域对象的技术实现细节。
战术设计
实体与值对象
每个实体是具有唯一标识的领域概念,并且可以相当长的一段时间内持续地变化。值对象则是通过对象属性值来识别的对象,它将多个相关属性组合为一个概念整体。在 DDD 中用来描述领域的特定方面,并且是一个没有标识符的对象,叫作值对象。
关于实体与值对象的详细讨论参阅领域对象。
Aggregate(聚合)与 Aggregate Root(聚合根)
聚合是具有一定关联关系的实体对象的集合,用来划分实体之间的边界,使模型之间更加内聚,边界更加清晰,定义清晰的聚合有助于避免混乱的模型关系划分导致模型之间错综复杂的关系网。抛除概念,可以理解为一组有关联关系的数据单元,聚合的加载、修改、销毁作为一个整体进行。聚合中所包含的对象之间具有密不可分的联系,一个聚合中可以包含多个实体和值对象,因此聚合也被称为根实体。聚合是持久化的基本单位,它和资源库具有一一对应的关系。
而聚合根是聚合的边界,是与外部打交道的唯一入口,聚合内部实体对象或值对象保持被聚合根引用,不可被其他聚合操作引用,也不能单独进行查询。聚合根是一种更大范围的封装,把一组有相同生命周期、在业务上不可分隔的实体和值对象放在一起考虑,只有根实体可以对外暴露引用,也是一种内聚性的表现。聚合内部的实体也有可能引用其他的聚合根。由此特性可得,聚合根的查询,在 DB 层面也应该是一个单元,聚合根被删除,整个聚合也会被删除(基本等于级联删除)。聚合根也是一个事务的边界,如果一次业务操作涉及到了对多个聚合状态的更改,那么应该采用发布领域事件的方式通知相应的聚合,此时的数据一致性便从事务一致性变成了最终一致性(Eventual Consistency)。
比如“公司”、“老板”、“员工” 就是一个聚合,有独立存在的意义,不依赖其他对象存在,能够被独立访问到的从这三个实体来看,公司为聚合根,公司倒闭了,雇佣的员工和老板也就不存在了。另外,快递员会每天往公司投递货物,两者之间并无直接关联,因此快递员是隶属于另外聚合中的一个实体,或独立为只有一个实体的聚合的根。因此聚合和根的设定需要在实际业务角度深入分析。通常在大多领域模型中,多数聚合只有一个实体,即聚合根,该实体内部只包含一部分值对象,另外少数聚合中也只有两三个实体引用。聚合尽可能粒度控制不要太大,否则为在事务级别做到聚合完整性,性能代价较大。
聚合根(Aggregate Root)是 DDD 中的一个概念,是一种更大范围的封装,把一组有相同生命周期、在业务上不可分隔的实体和值对象放在一起考虑,只有根实体可以对外暴露引用,也是一种内聚性的表现。确定聚合边界要满足固定规则(Invariant),是指在数据变化时必须保持的一致性规则,具体规则如下:
- 根实体具有全局标识,最终负责检查规定规则
- 聚合内的实体具有本地标识,这些标识在 Aggregate 内部才是唯一的
- 外部对象不能引用除根 Entity 之外的任何内部对象
- 只有 Aggregate 的根 Entity 才能直接通过数据库查询获取,其他对象必须通过遍历关联来发现
- Aggegate 内部的对象可以保持对其他 Aggregate 根的引用
- Aggregate 边界内的任何对象修改时,整个 Aggregate 的所有固定规则都必须满足
还是看银行的例子,Account(账号)是 CustomerInfo(客户信息)Entity 和 Address(值对象)的聚合根,Tansaction(交易)是流水(Journal)的聚合根,因为流水是因为交易才产生的,具有相同的生命周期。
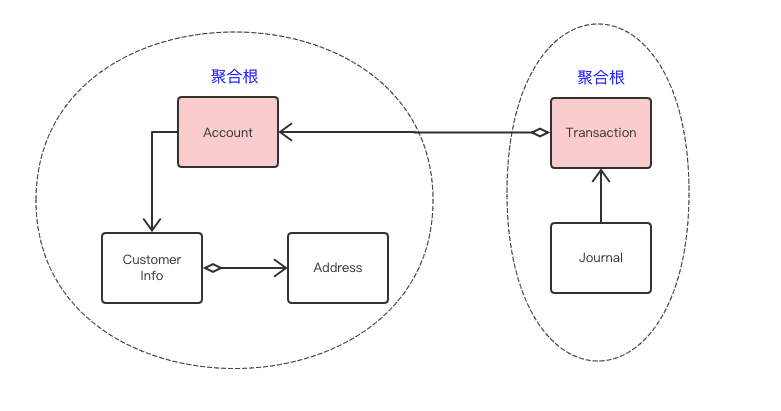
聚合根是一个逻辑概念,主观性很强,所以在建模过程中很容易产生分歧,因此在日常工作中千万不要教条,把握住一条主要原则,我们的最终目的是为了业务语义显现化,如果因为聚合根把模型弄的晦涩难懂那就得不偿失了。
Service(领域服务)
建模一个领域概念,把它放在实体上不合适,它放在值对象上也不合适,或者碰到跨聚合实例业务逻辑,没办法合理放到某个实体中的业务逻辑,领域服务就是应对这些情况的服务。如果勉强地把这些重要的领域功能归为 Entity 或 Value Object 的职责,那么不是歪曲了基于模型的对象的定义,就是人为地增加了一些无意义的对象;领域服务和上文中提到的应用服务是不同的,领域服务是领域模型的一部分,而应用服务不是。应用服务是领域服务的客户,它将领域模型变成对外界可用的软件系统。如果将太多的领域逻辑放在领域服务上,实体和值对象上的业务逻辑会越来越弱,将变成贫血对象。
在分层架构中需要区分什么时候应该定义领域服务,什么时候应该定义应用服务,一个根本的判断依据是看需要封装的职责是否与领域相关。
工厂(Factory)
有时候创建领域对象不仅仅是简单的 new 操作,比如创建是需要一系列初始化工作,对参数进行一些业务规则校验,如果参数无效不能创建期望的对象时抛出一个异常等,而这些规则属于领域层的业务,我们不希望暴露给应用层更多的领域规则,这就需要将这些细节进行一次封装,而在 DDD 中没有其他元素适合这一工作,于是出现了工厂这一概念。隐藏创建对象的好处是即不会污染应用层,又避免泄露领域层规则,只需要对外暴露简单的方法,外部传入创建所需的参数即可。
仓储(Repository)
由于聚合的特性,我们需要一并加载聚合实体到内存,也需将聚合整体持久化到 DB 中,我们又不希望直接在业务编码中直接编入如何获取数据的代码,于是产生出这一元素,负责聚合的加载与持久,对外提供简单的接口调用。仓储内部持有的一定是聚合,原因是在 DDD 中模型是以聚合划分的,实体的组建与持久依赖于所在聚合,模型不能够脱离聚合单独创建,因此仓储的设计也应该从聚合角度出发,我理解的仓储就是聚合的管理器,它的定义仅是一个接口,实现方式任意替换而不影响上层调用者。
抛除概念,从实际开发角度,仓储是领域模型与 ORM 工具中间的协调器。例如传统贫血模型中,DAO 通过 ORM 工具将表映射为对应的 DO(数值对象),而 DDD 中模型以聚合为边界划分,而碍于历史原因或性能需要,表结构往往与聚合结构有较大区别,仓储就是为了协调这种 DB 于模型之间转换而提出的概念。
如果系统并非用 DDD 方式建立模型, 而对象的加载使用 Repository 方式查询,则有些不伦不类,这样与 DAO 无任何分别,因为模型是贫血模型而非聚合。包的划分,仓储接口定义在领域层,实现在基础设施层。在传统 DDD 中一般由应用层引用仓储,而在 CQRS(DDD 针对因系统中存在大量复杂查询导致不得不跨聚合查询的一种优化模式)中一般由 Command 引用。
Domain Event(领域事件)
在 Eric 的《领域驱动设计》中并没有提到领域事件,领域事件是最近几年才加入 DDD 生态系统的。在传统的软件系统中,对数据一致性的处理都是通过事务完成的,其中包括本地事务和全局事务。DDD 的一个重要原则便是一次事务只能更新一个聚合实例,但存在一个业务流程涉及修改多个聚合的事务,怎么实现整个业务流程的数据一致性呢?在 DDD 中,领域事件便可以用于处理上述问题,此时最终一致性取代了事务一致性,通过领域事件的方式达到各个组件之间的数据一致性。既然是领域事件,他们便应该从领域模型中发布,一个领域事件是指一个在领域中“有意义”的事件。领域事件的最终接收者可以是本限界上下文中的组件,也可以是另一个限界上下文。再进一步发展,事件驱动架构可以演变成事件源(Event Sourcing),即对聚合的获取并不是通过加载数据库中的瞬时状态,而是通过重放发生在聚合生命周期中的所有领域事件完成。
战略设计
领域驱动设计的战略设计阶段是从以下两个方面来考虑的:
- 问题域方面:针对问题域,引入限界上下文(Bounded Context)和上下文映射(Context Map)对问题域进行合理的分解,识别出核心领域(Core Domain)与子领域(SubDomain),并确定领域的边界以及它们之间的关系,维持模型的完整性。
- 架构方面:通过分层架构来隔离关注点,尤其是将领域实现独立出来,能够更利于领域模型的单一性与稳定性;引入六边形架构可以清晰地表达领域与技术基础设施的边界;CQRS 模式则分离了查询场景和命令场景,针对不同场景选择使用同步或异步操作,来提高架构的低延迟性与高并发能力
Bounded Context(限界上下文)
用来封装通用语言和领域对象,为领域提供上下文语境,保证在领域之内的一些术语、业务相关对象等(通用语言)有一个确切的含义,没有二义性。使团队所有成员能够明确地知道什么必须保持一致,什么必须独立开发。
领域实体是有边界上下文的,比如 Apple 这个实体不同的上下文,表达的含义就完全不一样,在水果店它就是水果,在苹果专卖店它就是手机。
所以边界上下文(Bounded Context)在 DDD 里面是一个非常重要的概念,Bounded Context 明确地限定了模型的应用范围,在 Context 中,要保证模型在逻辑上统一,而不用考虑它是不是适用于边界之外的情况。在其他 Context 中,会使用其他模型,这些模型具有不同的术语、概念、规则和 Ubiquitous Language 的行话。
上下文映射(Context Mapping)
不同 Context 下的业务要互相通信就涉及跨边界的 Context Mapping(上下文映射),首先不同上下文之间的通信可以是同步的,也可以是异步的,同步的话一般是 RPC 或者 RESTFul,异步的话会推荐 Domain Event。
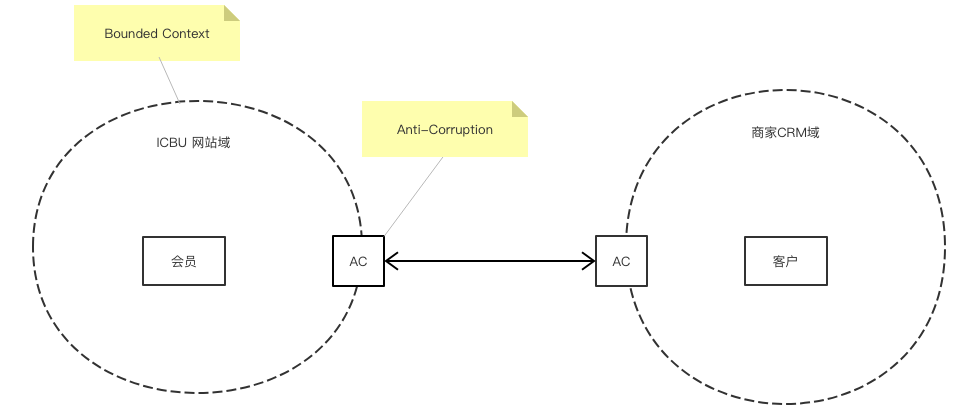
Mapping 的方式有很多种,有 Shared Kernal(共享内核),Conformist(追随者),以及 Anti-Corruption(防腐层)等等。比如会员这个概念在 ICBU 网站是指网站上的 Buyer,但是在 CRM 领域是指 Customer,虽然很多的属性都是一样的,但是二者在不同的 Context 下其语义和概念是有差别的,我们需要用 AC 做一下转换:
事件风暴(Event Storming)
事件风暴是一项团队活动,旨在通过领域事件识别出聚合根,进而划分微服务的限界上下文。在活动中,团队先通过头脑风暴的形式罗列出领域中所有的领域事件,整合之后形成最终的领域事件集合,然后对于每一个事件,标注出导致该事件的命令(Command),再然后为每个事件标注出命令发起方的角色,命令可以是用户发起,也可以是第三方系统调用或者是定时器触发等。最后对事件进行分类整理出聚合根以及限界上下文。
领域状态
在软件设计领域经常会提到状态(State)这个词,而服务之间的状态本质上体现的还是一种数据关系。如果一个数据需要在多个服务之间共享才能完成一项业务功能,那么这项业务功能就被称为有状态。基于这项业务功能所设计和实现的一系列服务之间就形成了一种状态性,这一系列服务就是有状态服务。
很多服务都会把自己的状态下沉到一个庞大的共享数据库中,这也是一些传统 Web 框架的做法。这种做法就会造成在扩展性、可用性以及数据集成上很难做好把控。而在本质上,一个使用共享数据库的微服务架构本质还是一个单体应用。一个服务既然具有单一职责,那么合理的方式就应该是该服务拥有自己的状态和持久化机制,建模成一个边界上下文。这里就需要充分应用领域驱动设计(Domain Driven Design,DDD)中的相关策略设计和技术设计方面的方法和工程实践。
共享内核(Shared Kernel)
如何实现不同域之间的协作,同时又要保证各自领域的概念的完整性是有一套方法论的。总体来说,大概有两种方式:共享内核(Shared Kernel)和防腐层(ACL,Anti-Corruption Layer)。
It’s possible that only one of the teams will maintain the code, build, and test for what is shared. A Shared Kernel is often very difficult to conceive in the first place, and difficult to maintain, because you must have open communication between teams and constant agreement on what constitutes the model to be shared.
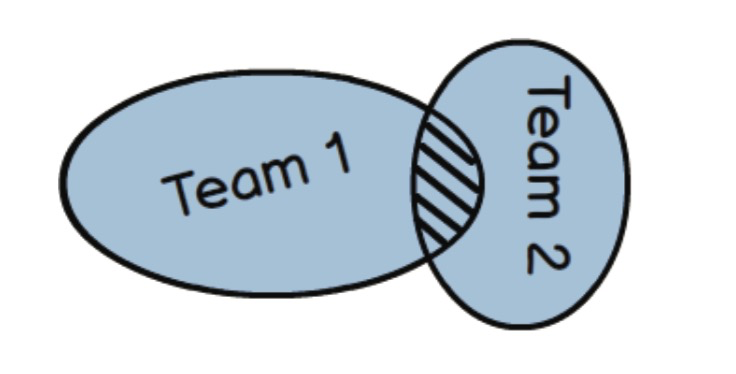
其优点是 Share(减少重复建设),其缺点也是 Share(团队之间紧耦合)。
防腐层(ACL,Anti-Corruption Layer)
An Anticorruption Layer is the most defensive Context Mapping relationship, where the downstream team creates a translation layer between its Ubiquitous Language (model) and the Ubiquitous Language (model) that is upstream to it.
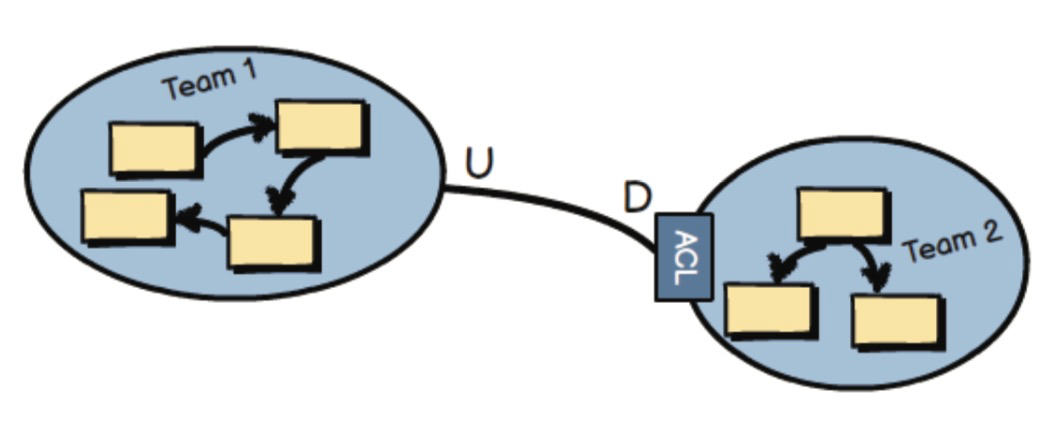
防腐层是隔离最彻底的做法,其优点是没有 Share(完全解耦,各自独立),其缺点也是没有 Share(有一定的转换成本)。笔者比较赞成防腐层的做法,因为增加的语义转换陈本,相较于系统的可维护性和可理解性而言,是完全值得的。
Whenever possible, you should try to create an Anticorruption Layer between your downstream model and an upstream integration model, so that you can produce model concepts on your side of the integration that specifically fit your business needs and that keep you completely isolated from foreign concepts.
Links
- https://zhuanlan.zhihu.com/p/381540329 深入理解领域驱动设计中的聚合