
聚合与聚合根的设计
如何设计聚合
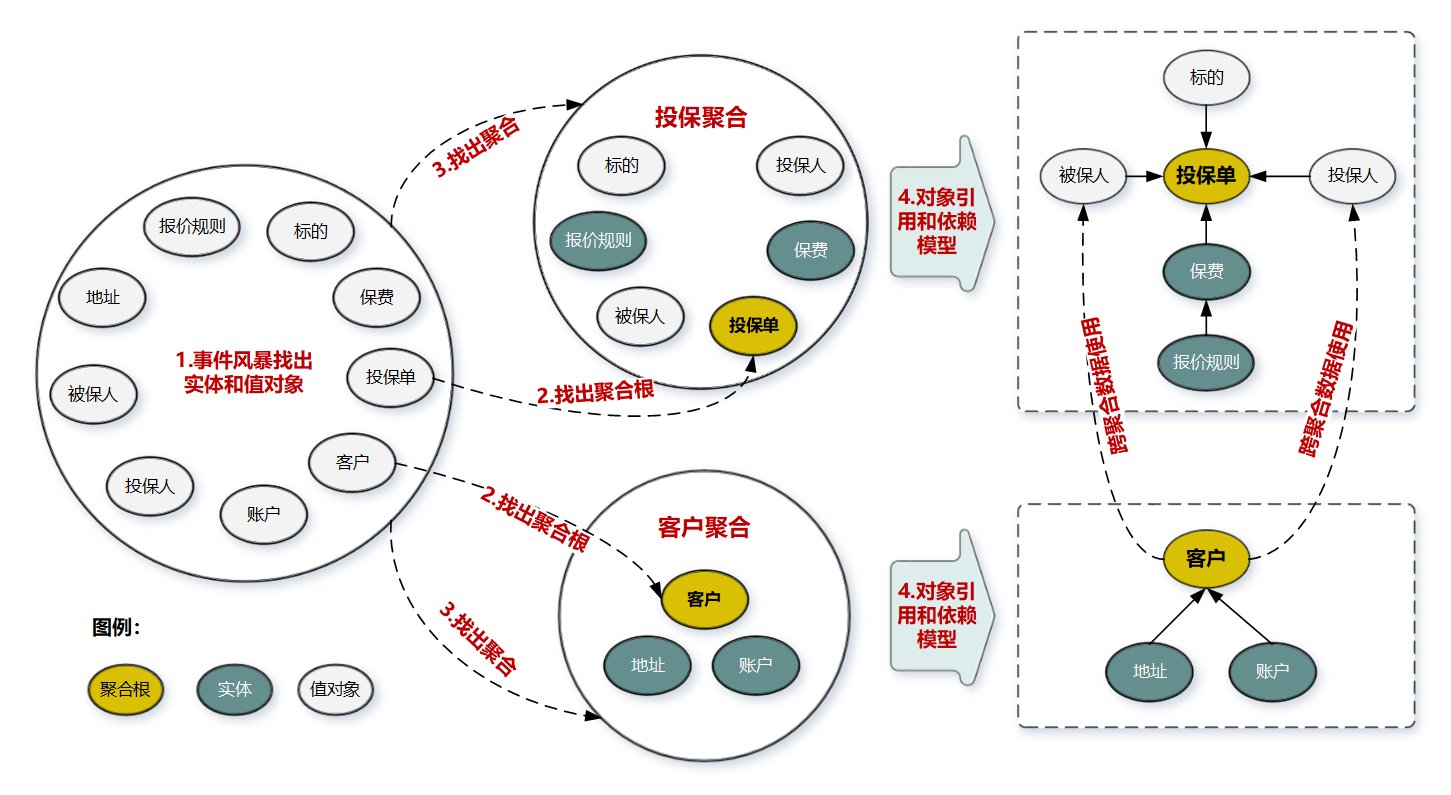
DDD 领域建模通常采用事件风暴,它通常采用用例分析、场景分析和用户旅程分析等方法,通过头脑风暴列出所有可能的业务行为和事件,然后找出产生这些行为的领域对象,并梳理领域对象之间的关系,找出聚合根,找出与聚合根业务紧密关联的实体和值对象,再将聚合根、实体和值对象组合,构建聚合。
-
采用事件风暴,根据业务行为,梳理出在投保过程中发生这些行为的所有的实体和值对象,比如投保单、标的、客户、被保人等等。
-
从众多实体中选出适合作为对象管理者的根实体,也就是聚合根。判断一个实体是否是聚合根,你可以结合以下场景分析:是否有独立的生命周期?是否有全局唯一 ID?是否可以创建或修改其它对象?是否有专门的模块来管这个实体。图中的聚合根分别是投保单和客户实体。
-
根据业务单一职责和高内聚原则,找出与聚合根关联的所有紧密依赖的实体和值对象。构建出 1 个包含聚合根(唯一)、多个实体和值对象的对象集合,这个集合就是聚合。在图中我们构建了客户和投保这两个聚合。
-
在聚合内根据聚合根、实体和值对象的依赖关系,画出对象的引用和依赖模型。这里我需要说明一下:投保人和被保人的数据,是通过关联客户 ID 从客户聚合中获取的,在投保聚合里它们是投保单的值对象,这些值对象的数据是客户的冗余数据,即使未来客户聚合的数据发生了变更,也不会影响投保单的值对象数据。从图中我们还可以看出实体之间的引用关系,比如在投保聚合里投保单聚合根引用了报价单实体,报价单实体则引用了报价规则子实体。
-
多个聚合根据业务语义和上下文一起划分到同一个限界上下文内。
聚合设计原则
-
在一致性边界内建模真正的不变条件。聚合用来封装真正的不变性,而不是简单地将对象组合在一起。聚合内有一套不变的业务规则,各实体和值对象按照统一的业务规则运行,实现对象数据的一致性,边界之外的任何东西都与该聚合无关,这就是聚合能实现业务高内聚的原因。
-
设计小聚合。如果聚合设计得过大,聚合会因为包含过多的实体,导致实体之间的管理过于复杂,高频操作时会出现并发冲突或者数据库锁,最终导致系统可用性变差。而小聚合设计则可以降低由于业务过大导致聚合重构的可能性,让领域模型更能适应业务的变化。
-
通过唯一标识引用其它聚合。聚合之间是通过关联外部聚合根 ID 的方式引用,而不是直接对象引用的方式。外部聚合的对象放在聚合边界内管理,容易导致聚合的边界不清晰,也会增加聚合之间的耦合度。
-
在边界之外使用最终一致性。聚合内数据强一致性,而聚合之间数据最终一致性。在一次事务中,最多只能更改一个聚合的状态。如果一次业务操作涉及多个聚合状态的更改,应采用领域事件的方式异步修改相关的聚合,实现聚合之间的解耦(相关内容我会在领域事件部分详解)。
-
通过应用层实现跨聚合的服务调用。为实现微服务内聚合之间的解耦,以及未来以聚合为单位的微服务组合和拆分,应避免跨聚合的领域服务调用和跨聚合的数据库表关联。