
04.模块应该是深的
第 4 章 模块应该是深的
Chapter 4 Modules Should Be Deep
One of the most important techniques for managing software complexity is to design systems so that developers only need to face a small fraction of the overall complexity at any given time. This approach is called modular design, and this chapter presents its basic principles.
管理软件复杂性最重要的技术之一就是设计系统,以便开发人员在任何给定时间 只需要面对整体复杂性的一小部分。这种方法称为模块化设计,本章介绍其基本原理。
4.1 Modular design 模块化设计
In modular design, a software system is decomposed into a collection of modules that are relatively independent. Modules can take many forms, such as classes, subsystems, or services. In an ideal world, each module would be completely independent of the others: a developer could work in any of the modules without knowing anything about any of the other modules. In this world, the complexity of a system would be the complexity of its worst module.
在模块化设计中,软件系统被分解为相对独立的模块集合。模块可以采用多种形式,例如类,子系统或服务。在理想的世界中,每个模块都将完全独立于其他模块:开发人员可以在任何模块中工作,而无需了解任何其他模块。在这个世界上,系统的复杂性就是最糟糕的模块的复杂性。
Unfortunately, this ideal is not achievable. Modules must work together by calling each others’s functions or methods. As a result, modules must know something about each other. There will be dependencies between the modules: if one module changes, other modules may need to change to match. For example, the arguments for a method create a dependency between the method and any code that invokes the method. If the required arguments change, all invocations of the method must be modified to conform to the new signature. Dependencies can take many other forms, and they can be quite subtle. The goal of modular design is to minimize the dependencies between modules.
不幸的是,这种理想是无法实现的。模块必须通过调用彼此的函数或方法来协同工作。结果,模块必须相互了解。模块之间将存在依赖关系:如果一个模块发生更改,则可能需要更改其他模块以进行匹配。例如,方法的参数在方法与调用该方法的任何代码之间创建依赖关系。如果必需的参数更改,则必须修改该方法的所有调用以符合新的签名。依赖关系可以采用许多其他形式,并且它们可能非常微妙。模块化设计的目标是最大程度地 减少模块之间的依赖性。
In order to manage dependencies, we think of each module in two parts: an interface and an implementation. The interface consists of everything that a developer working in a different module must know in order to use the given module. Typically, the interface describes what the module does but not how it does it. The implementation consists of the code that carries out the promises made by the interface. A developer working in a particular module must understand the interface and implementation of that module, plus the interfaces of any other modules invoked by the given module. A developer should not need to understand the implementations of modules other than the one he or she is working in.
为了管理依赖关系,我们将每个模块分为两个部分:接口和实现。接口包含使用其他模块的开发人员必须知道的所有内容,才能使用给定的模块。通常,接口描述模块做什么,而不描述模块如何做。该实现由执行接口所承诺的代码组成。在特定模块中工作的开发人员必须了解该模块的接口和实现,以及由给定模块调用的任何其他模块的接口。除了正在使用的模块以外,开发人员无需了解其他模块的实现。
Consider a module that implements balanced trees. The module probably contains sophisticated code for ensuring that the tree remains balanced. However, this complexity is not visible to users of the module. Users see a relatively simple interface for invoking operations to insert, remove, and fetch nodes in the tree. To invoke an insert operation, the caller need only provide the key and value for the new node; the mechanisms for traversing the tree and splitting nodes are not visible in the interface.
考虑一个实现平衡树的模块。该模块可能包含复杂的代码,以确保树保持平衡。但是,此复杂性对于模块用户而言是不可见的。用户可以看到一个相对简单的接口,用于调用在树中插入,删除和获取节点的操作。要调用插入操作,调用者只需提供新节点的键和值即可。遍历树和拆分节点的机制在接口中不可见。
For the purposes of this book, a module is any unit of code that has an interface and an implementation. Each class in an object-oriented programming language is a module. Methods within a class, or functions in a language that isn’t object-oriented, can also be thought of as modules: each of these has an interface and an implementation, and modular design techniques can be applied to them. Higher-level subsystems and services are also modules; their interfaces may take different forms, such as kernel calls or HTTP requests. Much of the discussion about modular design in this book focuses on designing classes, but the techniques and concepts apply to other kinds of modules as well.
就本书而言,模块是具有接口和实现的任何代码单元。面向对象编程语言中的每个类都是一个模块。类中的方法或非面向对象语言中的函数也可以视为模块:每个模块都有一个接口和一个实现,并且可以将模块化设计技术应用于它们。更高级别的子系统和服务也是模块。它们的接口可能采用不同的形式,例如内核调用或 HTTP 请求。本书中有关模块化设计的许多讨论都集中在设计类上,但是技术和概念也适用于其他种类的模块。
The best modules are those whose interfaces are much simpler than their implementations. Such modules have two advantages. First, a simple interface minimizes the complexity that a module imposes on the rest of the system. Second, if a module is modified in a way that does not change its interface, then no other module will be affected by the modification. If a module’s interface is much simpler than its implementation, there will be many aspects of the module that can be changed without affecting other modules.
最好的模块是那些其接口比其实现简单得多的模块。这样的模块具有两个优点。首先,一个简单的接口可以将模块强加于系统其余部分的复杂性降至最低。其次,如果以不更改其接口的方式修改了一个模块,则该修改不会影响其他模块。如果模块的接口比其实现简单得多,则可以在不影响其他模块的情况下更改模块的许多方面。
4.2 What’s in an interface? 接口中有什么?
The interface to a module contains two kinds of information: formal and informal. The formal parts of an interface are specified explicitly in the code, and some of these can be checked for correctness by the programming language. For example, the formal interface for a method is its signature, which includes the names and types of its parameters, the type of its return value, and information about exceptions thrown by the method. Most programming languages ensure that each invocation of a method provides the right number and types of arguments to match its signature. The formal interface for a class consists of the signatures for all of its public methods, plus the names and types of any public variables.
模块的接口包含两种信息:正式信息和非正式信息。接口的形式部分在代码中明确指定,并且其中一些可以通过编程语言检查其正确性。例如,方法的形式接口是其签名,其中包括其参数的名称和类型,其返回值的类型以及有关该方法引发的异常的信息。大多数编程语言都确保对方法的每次调用都提供正确数量和类型的参数以匹配其签名。类的形式接口包括其所有公共方法的签名以及任何公共变量的名称和类型。
Each interface also includes informal elements. These are not specified in a way that can be understood or enforced by the programming language. The informal parts of an interface include its high-level behavior, such as the fact that a function deletes the file named by one of its arguments. If there are constraints on the usage of a class (perhaps one method must be called before another), these are also part of the class’s interface. In general, if a developer needs to know a particular piece of information in order to use a module, then that information is part of the module’s interface. The informal aspects of an interface can only be described using comments, and the programming language cannot ensure that the description is complete or accurate1. For most interfaces the informal aspects are larger and more complex than the formal aspects.
每个接口还包括非正式元素。这些没有以编程语言可以理解或执行的方式指定。接口的非正式部分包括其高级行为,例如,函数删除由其参数之一命名的文件的事实。如果对类的使用存在限制(也许必须先调用一种方法),则这些约束也是类接口的一部分。通常,如果开发人员需要了解特定信息才能使用模块,则该信息是模块接口的一部分。接口的非正式方面只能使用注释来描述,而编程语言不能确保描述是完整或准确的 ^1。对于大多数接口,非正式方面比正式方面更大,更复杂。
One of the benefits of a clearly specified interface is that it indicates exactly what developers need to know in order to use the associated module. This helps to eliminate the “unknown unknowns” problem described in Section 2.2.
明确指定接口的好处之一是,它可以准确指示开发人员使用关联模块所需要知道的内容。这有助于消除第 2.2 节中描述的“未知的未知”问题。
4.3 Abstractions 抽象
The term abstraction is closely related to the idea of modular design. An abstraction is a simplified view of an entity, which omits unimportant details. Abstractions are useful because they make it easier for us to think about and manipulate complex things.
术语抽象与模块化设计的思想紧密相关。抽象是实体的简化视图,其中省略了不重要的细节。抽象是有用的,因为它们使我们更容易思考和操纵复杂的事物。
In modular programming, each module provides an abstraction in form of its interface. The interface presents a simplified view of the module’s functionality; the details of the implementation are unimportant from the standpoint of the module’s abstraction, so they are omitted from the interface.
在模块化编程中,每个模块以其接口的形式提供抽象。该接口提供了模块功能的简化视图;从模块抽象的角度来看,实现的细节并不重要,因此在接口中将其省略。
In the definition of abstraction, the word “unimportant” is crucial. The more unimportant details that are omitted from an abstraction, the better. However, a detail can only be omitted from an abstraction if it is unimportant. An abstraction can go wrong in two ways. First, it can include details that are not really important; when this happens, it makes the abstraction more complicated than necessary, which increases the cognitive load on developers using the abstraction. The second error is when an abstraction omits details that really are important. This results in obscurity: developers looking only at the abstraction will not have all the information they need to use the abstraction correctly. An abstraction that omits important details is a false abstraction: it might appear simple, but in reality it isn’t. The key to designing abstractions is to understand what is important, and to look for designs that minimize the amount of information that is important.
在抽象的定义中,“无关紧要”一词至关重要。从抽象中忽略的不重要的细节越多越好。但是,如果细节不重要,则只能将其从抽象中省略。抽象可以通过两种方式出错。首先,它可以包含并非真正重要的细节。当这种情况发生时,它会使抽象变得不必要的复杂,从而增加了使用抽象的开发人员的认知负担。第二个错误是抽象忽略了真正重要的细节。这导致模糊不清:仅查看抽象的开发人员将不会获得正确使用抽象所需的全部信息。忽略重要细节的抽象是错误的抽象:它可能看起来很简单,但实际上并非如此。(设计抽象的重要一点就是识别重要性,并在设计过程中,将重要信息的数量尽量减到最少)
As an example, consider a file system. The abstraction provided by a file system omits many details, such as the mechanism for choosing which blocks on a storage device to use for the data in a given file. These details are unimportant to users of the file system (as long as the system provides adequate performance). However, some of the details of a file system’s implementation are important to users. Most file systems cache data in main memory, and they may delay writing new data to the storage device in order to improve performance. Some applications, such as databases, need to know exactly when data is written through to storage, so they can ensure that data will be preserved after system crashes. Thus, the rules for flushing data to secondary storage must be visible in the file system’s interface.
例如,考虑一个文件系统。文件系统提供的抽象省略了许多细节,例如用于选择存储设备上的哪些块用于给定文件中的数据的机制。这些详细信息对于文件系统的用户而言并不重要(只要系统提供足够的性能即可)。但是,文件系统实现的一些细节对用户很重要。大多数文件系统将数据缓存在主内存中,并且它们可能会延迟将新数据写入存储设备以提高性能。一些应用程序(例如数据库)需要确切地知道何时将数据写入存储设备,因此它们可以确保在系统崩溃后将保留数据。因此,将数据刷新到辅助存储的规则必须在文件系统的接口中可见。
We depend on abstractions to manage complexity not just in programming, but pervasively in our everyday lives. A microwave oven contains complex electronics to convert alternating current into microwave radiation and distribute that radiation throughout the cooking cavity. Fortunately, users see a much simpler abstraction, consisting of a few buttons to control the timing and intensity of the microwaves. Cars provide a simple abstraction that allows us to drive them without understanding the mechanisms for electrical motors, battery power management, anti-lock brakes, cruise control, and so on.
我们不仅依靠抽象来管理复杂性,而且不仅在编程中,而且在日常生活中无处不在。微波炉包含复杂的电子设备,可将交流电转换为微波辐射并将该辐射分布到整个烹饪腔中。幸运的是,用户看到了一个简单得多的抽象,它由几个按钮控制微波的定时和强度。汽车提供了一种简单的抽象概念,使我们可以在不了解电动机,电池电源管理,防抱死制动,巡航控制等机制的情况下驾驶它们。
4.4 Deep modules 深度模块
The best modules are those that provide powerful functionality yet have simple interfaces. I use the term deep to describe such modules. To visualize the notion of depth, imagine that each module is represented by a rectangle, as shown in Figure 4.1. The area of each rectangle is proportional to the functionality implemented by the module. The top edge of a rectangle represents the module’s interface; the length of that edge indicates the complexity of the interface. The best modules are deep: they have a lot of functionality hidden behind a simple interface. A deep module is a good abstraction because only a small fraction of its internal complexity is visible to its users.
最好的模块是那些提供强大功能但具有简单接口的模块。我用“深入”一词来描述这样的模块。为了形象化深度的概念,假设每个模块都由一个矩形表示,如图 4.1 所示。每个矩形的面积与模块实现的功能成比例。矩形的顶部边缘代表模块的接口;边缘的长度表示接口的复杂性。最好的模块很深:它们在简单的接口后隐藏了许多功能。深度模块是一个很好的抽象,因为其内部复杂性的很小一部分对其用户可见。
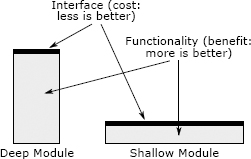
Figure 4.1: Deep and shallow modules. The best modules are deep: they allow a lot of functionality to be accessed through a simple interface. A shallow module is one with a relatively complex interface, but not much functionality: it doesn’t hide much complexity.
图 4.1:深浅模块。最好的模块很深:它们允许通过简单的接口访问许多功能。浅层模块是具有相对复杂的接口的模块,但功能不多:它不会掩盖太多的复杂性。
Module depth is a way of thinking about cost versus benefit. The benefit provided by a module is its functionality. The cost of a module (in terms of system complexity) is its interface. A module’s interface represents the complexity that the module imposes on the rest of the system: the smaller and simpler the interface, the less complexity that it introduces. The best modules are those with the greatest benefit and the least cost. Interfaces are good, but more, or larger, interfaces are not necessarily better!
模块深度是考虑成本与收益的一种方式。模块提供的好处是其功能。模块的成本(就系统复杂性而言)是其接口。模块的接口代表了模块强加给系统其余部分的复杂性:接口越小越简单,引入的复杂性就越小。最好的模块是那些收益最大,成本最低的模块。接口不错,但更多或更大的接口不一定更好!
The mechanism for file I/O provided by the Unix operating system and its descendants, such as Linux, is a beautiful example of a deep interface. There are only five basic system calls for I/O, with simple signatures:
Unix 操作系统及其后代(例如 Linux)提供的文件 I/O 机制是深层接口的一个很好的例子。I/O 只有五个基本系统调用,带有简单签名:
int open(const char* path, int flags, mode_t permissions);
ssize_t read(int fd, void* buffer, size_t count);
ssize_t write(int fd, const void* buffer, size_t count);
off_t lseek(int fd, off_t offset, int referencePosition);
int close(int fd);
The open system call takes a hierarchical file name such as
/a/b/cand returns an integer file descriptor, which is used to reference the open file. The other arguments for open provide optional information such as whether the file is being opened for reading or writing, whether a new file should be created if there is no existing file, and access permissions for the file, if a new file is created. The read and write system calls transfer information between buffer areas in the application’s memory and the file; close ends the access to the file. Most files are accessed sequentially, so that is the default; however, random access can be achieved by invoking the lseek system call to change the current access position.
开放系统调用采用分层文件名,例如 /a/b/c,并返回一个整数 文件描述符,该描述符用于引用打开文件。open 的其他自变量提供可选信息,例如是否正在打开文件以进行读取或写入,如果不存在现有文件则是否应创建新文件,以及如果创建新文件则具有文件的访问权限。读写系统调用在应用程序内存和文件的缓冲区之间传输信息。close 结束对文件的访问。大多数文件是按顺序访问的,因此这是默认设置。但是,可以通过调用 lseek 系统调用来更改当前访问位置来实现随机访问。
A modern implementation of the Unix I/O interface requires hundreds of thousands of lines of code, which address complex issues such as:
Unix I/O 接口的现代实现需要成千上万行代码,这些代码可以解决诸如以下的复杂问题:
- How are files represented on disk in order to allow efficient access?
- How are directories stored, and how are hierarchical path names processed to find the files they refer to?
- How are permissions enforced, so that one user cannot modify or delete another user’s files?
- How are file accesses implemented? For example, how is functionality divided between interrupt handlers and background code, and how do these two elements communicate safely?
- What scheduling policies are used when there are concurrent accesses to multiple files?
- How can recently accessed file data be cached in memory in order to reduce the number of disk accesses?
- How can a variety of different secondary storage devices, such as disks and flash drives, be incorporated into a single file system?
- 如何在磁盘上表示文件以便有效访问?
- 如何存储目录,以及如何处理分层路径名以查找它们所引用的文件?
- 如何强制执行权限,以使一个用户无法修改或删除另一用户的文件?
- 如何实现文件访问?例如,如何在中断处理程序和后台代码之间划分功能,以及这两个元素如何安全通信?
- 在同时访问多个文件时使用什么调度策略?
- 如何将最近访问的文件数据缓存在内存中以减少磁盘访问次数?
- 如何将各种不同的辅助存储设备(例如磁盘和闪存驱动器)合并到单个文件系统中?
All of these issues, and many more, are handled by the Unix file system implementation; they are invisible to programmers who invoke the system calls. Implementations of the Unix I/O interface have evolved radically over the years, but the five basic kernel calls have not changed.
所有这些问题,以及更多的问题,都由 Unix 文件系统实现来解决。对于调用系统调用的程序员来说,它们是不可见的。多年来,Unix I/O 接口的实现已经发生了根本的发展,但是五个基本内核调用并没有改变。
Another example of a deep module is the garbage collector in a language such as Go or Java. This module has no interface at all; it works invisibly behind the scenes to reclaim unused memory. Adding garbage collection to a system actually shrinks its overall interface, since it eliminates the interface for freeing objects. The implementation of a garbage collector is quite complex, but that complexity is hidden from programmers using the language.
深度模块的另一个示例是诸如 Go 或 Java 之类的语言中的垃圾收集器。这个模块根本没有接口。它在后台进行隐形操作以回收未使用的内存。由于将垃圾收集消除了用于释放对象的接口,因此向系统中添加垃圾回收实际上会缩小其总体接口。垃圾收集器的实现非常复杂,但是使用该语言的程序员无法发现这种复杂性。
Deep modules such as Unix I/O and garbage collectors provide powerful abstractions because they are easy to use, yet they hide significant implementation complexity.
诸如 Unix I/O 和垃圾收集器之类的深层模块提供了强大的抽象,因为它们易于使用,但隐藏了巨大的实现复杂性。
4.5 Shallow modules 浅模块
On the other hand, a shallow module is one whose interface is relatively complex in comparison to the functionality that it provides. For example, a class that implements linked lists is shallow. It doesn’t take much code to manipulate a linked list (inserting or deleting an element takes only a few lines), so the linked list abstraction doesn’t hide very many details. The complexity of a linked list interface is nearly as great as the complexity of its implementation. Shallow classes are sometimes unavoidable, but they don’t provide help much in managing complexity.
另一方面,浅层模块是其接口与其提供的功能相比相对复杂的模块。例如,实现链表的类很浅。操作链表不需要太多代码(插入或删除元素仅需几行),因此链表抽象不会隐藏很多细节。链表接口的复杂度几乎与其实现的复杂度一样高。浅类有时是不可避免的,但是它们在管理复杂性方面没有提供太多帮助。
Here is an extreme example of a shallow method, taken from a project in a software design class:
这是一个浅层方法的极端示例,该浅层方法来自软件设计类的项目:
private void addNullValueForAttribute(String attribute) {
data.put(attribute, null);
}
From the standpoint of managing complexity, this method makes things worse, not better. The method offers no abstraction, since all of its functionality is visible through its interface. For example, callers probably need to know that the attribute will be stored in the data variable. It is no simpler to think about the interface than to think about the full implementation. If the method is documented properly, the documentation will be longer than the method’s code. It even takes more keystrokes to invoke the method than it would take for a caller to manipulate the data variable directly. The method adds complexity (in the form of a new interface for developers to learn) but provides no compensating benefit.
从管理复杂性的角度来看,此方法会使情况变得更糟,而不是更好。该方法不提供任何抽象,因为其所有功能都可以通过其接口看到。例如,调用者可能需要知道该属性将存储在 data 变量中。考虑接口并不比考虑完整实现简单。如果正确记录了该方法,则文档将比该方法的代码长。与调用方直接操作数据变量相比,调用该方法所花费的击键甚至更多。该方法增加了复杂性(以供开发人员学习的新接口的形式),但没有提供任何补偿。
img Red Flag: Shallow Module img
A shallow module is one whose interface is complicated relative to the functionality it provides. Shallow modules don’t help much in the battle against complexity, because the benefit they provide (not having to learn about how they work internally) is negated by the cost of learning and using their interfaces. Small modules tend to be shallow.
浅层模块是一个接口相对于其提供的功能而言复杂的模块。浅层模块在对抗复杂性方面无济于事,因为它们提供的好处(不必了解它们在内部如何工作)被学习和使用其接口的成本所抵消。小模块往往很浅。
4.6 Classitis
Unfortunately, the value of deep classes is not widely appreciated today. The conventional wisdom in programming is that classes should be small, not deep. Students are often taught that the most important thing in class design is to break up larger classes into smaller ones. The same advice is often given about methods: “Any method longer than N lines should be divided into multiple methods” (N can be as low as 10). This approach results in large numbers of shallow classes and methods, which add to overall system complexity.
不幸的是,深度类的价值在今天并未得到广泛认可。编程中的传统观点是,类应该小而不是深。经常告诉学生,类设计中最重要的事情是将较大的类分成较小的类。对于方法,通常会给出相同的建议:“任何长于 N 行的方法都应分为多种方法”(N 可以低至 10)。这种方法导致了大量的浅类和方法,这增加了整体系统的复杂性。
The extreme of the “classes should be small” approach is a syndrome I call classitis, which stems from the mistaken view that “classes are good, so more classes are better.” In systems suffering from classitis, developers are encouraged to minimize the amount of functionality in each new class: if you want more functionality, introduce more classes. Classitis may result in classes that are individually simple, but it increases the complexity of the overall system. Small classes don’t contribute much functionality, so there have to be a lot of them, each with its own interface. These interfaces accumulate to create tremendous complexity at the system level. Small classes also result in a verbose programming style, due to the boilerplate required for each class.
“类应该小”的极端做法是我称之为“类炎”的综合症,这是由于错误地认为“类是好的,所以类越多越好”。在遭受类炎的系统中,鼓励开发人员最小化每个新类的功能:如果您想要更多的功能,请引入更多的类。分类炎可能导致个别地简单的分类,但是却增加了整个系统的复杂性。小类不会贡献太多功能,因此必须有很多小类,每个小类都有自己的接口。这些接口的累积会在系统级别产生巨大的复杂性。小类也导致冗长的编程风格,这是由于每个类都需要样板。
4.7 Examples: Java and Unix I/O 示例:Java 和 Unix I/O
One of the most visible examples of classitis today is the Java class library. The Java language doesn’t require lots of small classes, but a culture of classitis seems to have taken root in the Java programming community. For example, to open a file in order to read serialized objects from it, you must create three different objects:
如今,最常见的分类病实例之一是 Java 类库。Java 语言不需要很多小类,但是分类文化似乎已在 Java 编程社区中扎根。例如,要打开文件以便从文件中读取序列化的对象,必须创建三个不同的对象:
FileInputStream fileStream = new FileInputStream(fileName);
BufferedInputStream bufferedStream = new BufferedInputStream(fileStream);
ObjectInputStream objectStream = new ObjectInputStream(bufferedStream);
A FileInputStream object provides only rudimentary I/O: it is not capable of performing buffered I/O, nor can it read or write serialized objects. The BufferedInputStream object adds buffering to a FileInputStream, and the ObjectInputStream adds the ability to read and write serialized objects. The first two objects in the code above, fileStream and bufferedStream, are never used once the file has been opened; all future operations use objectStream.
FileInputStream 对象仅提供基本的 I/O:它不能执行缓冲的 I/O,也不能读取或写入序列化的对象。BufferedInputStream 对象将缓冲添加到 FileInputStream,而 ObjectInputStream 添加了读取和写入序列化对象的功能。一旦文件被打开,上面代码中的前两个对象 fileStream 和 bufferedStream 将永远不会被使用。以后的所有操作都使用 objectStream。
It is particularly annoying (and error-prone) that buffering must be requested explicitly by creating a separate BufferedInputStream object; if a developer forgets to create this object, there will be no buffering and I/O will be slow. Perhaps the Java developers would argue that not everyone wants to use buffering for file I/O, so it shouldn’t be built into the base mechanism. They might argue that it’s better to keep buffering separate, so people can choose whether or not to use it. Providing choice is good, but interfaces should be designed to make the common case as simple as possible (see the formula on page 6). Almost every user of file I/O will want buffering, so it should be provided by default. For those few situations where buffering is not desirable, the library can provide a mechanism to disable it. Any mechanism for disabling buffering should be cleanly separated in the interface (for example, by providing a different constructor for FileInputStream, or through a method that disables or replaces the buffering mechanism), so that most developers do not even need to be aware of its existence.
特别令人烦恼(并且容易出错)的是,必须通过创建一个单独的 BufferedInputStream 对象来显式请求缓冲。如果开发人员忘记创建该对象,将没有缓冲,并且 I/O 将变慢。也许 Java 开发人员会争辩说,并不是每个人都希望对文件 I/O 使用缓冲,因此不应将其内置到基本机制中。他们可能会争辩说,最好分开保持缓冲,以便人们可以选择是否使用它。提供选择是好的,但是 应该设计接口以使常见情况尽可能简单 (请参阅第 6 页的公式)。几乎每个文件 I/O 用户都希望缓冲,因此默认情况下应提供缓冲。对于不需要缓冲的少数情况,该库可以提供一种禁用它的机制。
In contrast, the designers of the Unix system calls made the common case simple. For example, they recognized that sequential I/O is most common, so they made that the default behavior. Random access is still relatively easy to do, using the lseek system call, but a developer doing only sequential access need not be aware of that mechanism. If an interface has many features, but most developers only need to be aware of a few of them, the effective complexity of that interface is just the complexity of the commonly used features.
相反,Unix 系统调用的设计者使常见情况变得简单。例如,他们认识到顺序 I/O 是最常见的,因此他们将其作为默认行为。使用 lseek 系统调用,随机访问仍然相对容易实现,但是仅执行顺序访问的开发人员无需了解该机制。如果一个接口具有许多功能,但是大多数开发人员只需要了解其中的一些功能,那么该接口的有效复杂性就是常用功能的复杂性。
4.8 Conclusion 结论
By separating the interface of a module from its implementation, we can hide the complexity of the implementation from the rest of the system. Users of a module need only understand the abstraction provided by its interface. The most important issue in designing classes and other modules is to make them deep, so that they have simple interfaces for the common use cases, yet still provide significant functionality. This maximizes the amount of complexity that is concealed.
通过将模块的接口与其实现分开,我们可以将实现的复杂性从系统的其余部分中隐藏出来。模块的用户只需要了解其接口提供的抽象。设计类和其他模块时,最重要的问题是使它们更深,以使它们具有适用于常见用例的简单接口,但仍提供重要的功能。这使隐藏的复杂性最大化。
1 There exist languages, mostly in the research community, where the overall behavior of a method or function can be described formally using a specification language. The specification can be checked automatically to ensure that it matches the implementation. An interesting question is whether such a formal specification could replace the informal parts of an interface. My current opinion is that an interface described in English is likely to be more intuitive and understandable for developers than one written in a formal specification language.
^1 存在语言,主要是在研究社区中,在其中可以使用规范语言来正式描述方法或功能的整体行为。可以自动检查该规范以确保它与实现相匹配。一个有趣的问题是,这样的正式规范是否可以代替接口的非正式部分。我目前的观点是,用英语描述的接口比使用正式规范语言编写的接口对开发人员来说更直观和易于理解。