
05.信息隐藏和泄露
第 5 章 信息隐藏(和泄漏)
Chapter 5 Information Hiding (and Leakage)
Chapter 4 argued that modules should be deep. This chapter, and the next few that follow, discuss techniques for creating deep modules.
第四章认为模块应该很深。本章及随后的其他章节讨论了创建深层模块的技术。
5.1 Information hiding 信息隐藏
The most important technique for achieving deep modules is information hiding. This technique was first described by David Parnas1. The basic idea is that each module should encapsulate a few pieces of knowledge, which represent design decisions. The knowledge is embedded in the module’s implementation but does not appear in its interface, so it is not visible to other modules.
实现深层模块最重要的技术是信息隐藏。该技术最早由 David Parnas1 描述。基本思想是每个模块应封装一些知识,这些知识代表设计决策。该知识嵌入在模块的实现中,但不会出现在其接口中,因此其他模块不可见。
The information hidden within a module usually consists of details about how to implement some mechanism. Here are some examples of information that might be hidden within a module:
隐藏在模块中的信息通常包含有关如何实现某种机制的详细信息。以下是一些信息可能隐藏在模块中的示例:
- How to store information in a B-tree, and how to access it efficiently.
- How to identify the physical disk block corresponding to each logical block within a file.
- How to implement the TCP network protocol.
- How to schedule threads on a multi-core processor.
- How to parse JSON documents.
- 如何在 B 树中存储信息,以及如何有效地访问它。
- 如何识别文件中每个逻辑块相对应的物理磁盘块。
- 如何实现 TCP 网络协议。
- 如何在多核处理器上调度线程。
- 如何解析 JSON 文档。
The hidden information includes data structures and algorithms related to the mechanism. It can also include lower-level details such as the size of a page, and it can include higher-level concepts that are more abstract, such as an assumption that most files are small.
隐藏的信息包括与该机制有关的数据结构和算法。它还可以包含较低级别的详细信息(例如页面大小),还可以包含更抽象的较高级别的概念,例如大多数文件较小的假设。
Information hiding reduces complexity in two ways. First, it simplifies the interface to a module. The interface reflects a simpler, more abstract view of the module’s functionality and hides the details; this reduces the cognitive load on developers who use the module. For instance, a developer using a B-tree class need not worry about the ideal fanout for nodes in the tree or how to keep the tree balanced. Second, information hiding makes it easier to evolve the system. If a piece of information is hidden, there are no dependencies on that information outside the module containing the information, so a design change related to that information will affect only the one module. For example, if the TCP protocol changes (to introduce a new mechanism for congestion control, for instance), the protocol’s implementation will have to be modified, but no changes should be needed in higher-level code that uses TCP to send and receive data.
信息隐藏在两个方面降低了复杂性。首先,它简化了模块的接口。接口用更简单、更抽象的方式反映了模块的功能,并隐藏了细节。这减少了使用该模块的开发人员的认知负担。例如,使用 B-tree 类的开发人员不需要考虑树中节点的理想扇出,也不需要考虑如何保持树的平衡。其次,信息隐藏使系统更容易演化。如果隐藏了一段信息,那么在包含该信息的模块之外就不存在对该信息的依赖,因此与该信息相关的设计更改将只影响一个模块。例如,如果 TCP 协议发生了变化(例如,为了引入一种新的拥塞控制机制),协议的实现就必须进行修改,但是在使用 TCP 发送和接收数据的高级代码中不需要进行任何修改。
When designing a new module, you should think carefully about what information can be hidden in that module. If you can hide more information, you should also be able to simplify the module’s interface, and this makes the module deeper.
设计新模块时,应仔细考虑可以在该模块中隐藏哪些信息。如果您可以隐藏更多信息,则还应该能够简化模块的接口,这会使模块更深。
Note: hiding variables and methods in a class by declaring them private isn’t the same thing as information hiding. Private elements can help with information hiding, since they make it impossible for the items to be accessed directly from outside the class. However, information about the private items can still be exposed through public methods such as getter and setter methods. When this happens the nature and usage of the variables are just as exposed as if the variables were public.
注意:通过声明变量和方法为私有来隐藏类中的变量和方法与信息隐藏不是同一回事。私有元素可以帮助隐藏信息,因为它们使无法从类外部直接访问项目。但是,私有属性仍可以通过公共方法(如 getter 和 setter 方法)公开。发生这种情况时,私有属性的性质和用法就如同公共属性一样是公开的。
The best form of information hiding is when information is totally hidden within a module, so that it is irrelevant and invisible to users of the module. However, partial information hiding also has value. For example, if a particular feature or piece of information is only needed by a few of a class’s users, and it is accessed through separate methods so that it isn’t visible in the most common use cases, then that information is mostly hidden. Such information will create fewer dependencies than information that is visible to every user of the class.
信息隐藏的最佳形式是将信息完全隐藏在模块中,从而使该信息对模块的用户无关且不可见。但是,部分信息隐藏也具有价值。例如,如果一个特定的特性或信息只被少数的类使用者所需要,并且它是通过不同的方法访问的,所以在最常见的用例中它是不可见的,那么这个信息大部分是隐藏的。与将信息暴露给所有类使用者相比, 这种方式会产生更少的依赖.
5.2 Information leakage 信息泄漏
The opposite of information hiding is information leakage. Information leakage occurs when a design decision is reflected in multiple modules. This creates a dependency between the modules: any change to that design decision will require changes to all of the involved modules. If a piece of information is reflected in the interface for a module, then by definition it has been leaked; thus, simpler interfaces tend to correlate with better information hiding. However, information can be leaked even if it doesn’t appear in a module’s interface. Suppose two classes both have knowledge of a particular file format (perhaps one class reads files in that format and the other class writes them). Even if neither class exposes that information in its interface, they both depend on the file format: if the format changes, both classes will need to be modified. Back-door leakage like this is more pernicious than leakage through an interface, because it isn’t obvious.
信息隐藏的反面是信息泄漏。当一个设计决策反映在多个模块中时,就会发生信息泄漏。这在模块之间创建了依赖关系:对该设计决策的任何更改都将要求对所有涉及的模块进行更改。如果一条信息反映在模块的接口中,则根据定义,该信息已经泄漏;因此,更简单的接口往往与更好的信息隐藏相关。但是,即使信息未出现在模块的接口中,也可能会泄漏信息。假设两个类都具有特定文件格式的知识(也许一个类读取该格式的文件,而另一个类写入它们)。即使两个类都不在其接口中公开该信息,它们都依赖于文件格式:如果格式更改,则两个类都将需要修改。像这样的后门泄漏比通过接口泄漏更有害,因为它并不明显。
Information leakage is one of the most important red flags in software design. One of the best skills you can learn as a software designer is a high level of sensitivity to information leakage. If you encounter information leakage between classes, ask yourself “How can I reorganize these classes so that this particular piece of knowledge only affects a single class?” If the affected classes are relatively small and closely tied to the leaked information, it may make sense to merge them into a single class. Another possible approach is to pull the information out of all of the affected classes and create a new class that encapsulates just that information. However, this approach will be effective only if you can find a simple interface that abstracts away from the details; if the new class exposes most of the knowledge through its interface, then it won’t provide much value (you’ve simply replaced back-door leakage with leakage through an interface).
信息泄漏是软件设计中最重要的危险信号之一。作为一个软件设计师,你能学到的最好的技能之一就是对信息泄露的高度敏感性。如果您在类之间遇到信息泄漏,请自问“我如何才能重新组织这些类,使这些特定的知识只影响一个类?”如果受影响的类相对较小,并且与泄漏的信息紧密相关,那么将它们合并到一个类中是有意义的。另一种可能的方法是从所有受影响的类中提取信息,并创建一个只封装这些信息的新类。但是,这种方法只有在您能够找到一个从细节中抽象出来的简单接口时才有效;如果新类通过其接口公开了大部分知识,那么它就不会提供太多的价值(您只是用通过接口的泄漏替换了后门泄漏)。
img Red Flag: Information Leakage img
Information leakage occurs when the same knowledge is used in multiple places, such as two different classes that both understand the format of a particular type of file.
当在多个地方使用相同的知识时,例如两个都理解特定类型文件格式的不同类,就会发生信息泄漏。
5.3 Temporal decomposition 时间分解
One common cause of information leakage is a design style I call temporal decomposition. In temporal decomposition, the structure of a system corresponds to the time order in which operations will occur. Consider an application that reads a file in a particular format, modifies the contents of the file, and then writes the file out again. With temporal decomposition, this application might be broken into three classes: one to read the file, another to perform the modifications, and a third to write out the new version. Both the file reading and file writing steps have knowledge about the file format, which results in information leakage. The solution is to combine the core mechanisms for reading and writing files into a single class. This class will get used during both the reading and writing phases of the application. It’s easy to fall into the trap of temporal decomposition, because the order in which operations must occur is often on your mind when you code. However, most design decisions manifest themselves at several different times over the life of the application; as a result, temporal decomposition often results in information leakage.
信息泄漏的一个常见原因是我称为时间分解的设计风格。在时间分解中,系统的结构对应于操作将发生的时间顺序。考虑一个应用程序,该应用程序以特定格式读取文件,修改文件内容,然后再次将文件写出。通过时间分解,该应用程序可以分为三类:一类用于读取文件,另一类用于执行修改,第三类用于写出新版本。文件读取和文件写入步骤都具有有关文件格式的知识,这会导致信息泄漏。解决方案是将用于读写文件的核心机制结合到一个类中。该类将在应用程序的读取和写入阶段使用。因为在编写代码时通常会想到必须执行操作的顺序, 所以很容易陷入时间分解的陷阱。但是,大多数设计决策会在应用程序的整个生命周期中的多个不同时刻表现出来。结果,时间分解常常导致信息泄漏。
Order usually does matter, so it will be reflected somewhere in the application. However, it shouldn’t be reflected in the module structure unless that structure is consistent with information hiding (perhaps the different stages use totally different information). When designing modules, focus on the knowledge that’s needed to perform each task, not the order in which tasks occur.
顺序通常很重要,因此它将反映在应用程序中的某个位置。但是,除非该结构与信息隐藏保持一致(也许不同阶段使用完全不同的信息),否则不应将其反映在模块结构中。在设计模块时,应专注于执行每个任务所需的知识,而不是任务发生的顺序。
img Red Flag: Temporal Decomposition img
In temporal decomposition, execution order is reflected in the code structure: operations that happen at different times are in different methods or classes. If the same knowledge is used at different points in execution, it gets encoded in multiple places, resulting in information leakage.
在时间分解中,执行顺序反映在代码结构中:在不同时间发生的操作在不同的方法或类中。如果相同的知识在不同的执行点使用,它会在多个位置被编码,从而导致信息泄漏。
5.4 Example: HTTP server 示例:HTTP 服务器
To illustrate the issues in information hiding, let’s consider the design decisions made by students implementing the HTTP protocol in a software design course. It’s useful to see both the things they did well and they areas where they had problems.
为了说明信息隐藏中的问题,让我们考虑由学生在软件设计课程中实现 HTTP 协议的设计决策。看到他们做得好的事情以及遇到问题的地方都是很有用的。
HTTP is a mechanism used by Web browsers to communicate with Web servers. When a user clicks on a link in a Web browser or submits a form, the browser uses HTTP to send a request over the network to a Web server. Once the server has processed the request, it sends a response back to the browser; the response normally contains a new Web page to display. The HTTP protocol specifies the format of requests and responses, both of which are represented textually. Figure 5.1 shows a sample HTTP request describing a form submission. The students in the course were asked to implement one or more classes to make it easy for Web servers to receive incoming HTTP requests and send responses.
HTTP 是 Web 浏览器用来与 Web 服务器通信的机制。当用户单击 Web 浏览器中的链接或提交表单时,浏览器使用 HTTP 通过网络将请求发送到 Web 服务器。服务器处理完请求后,会将响应发送回浏览器。该响应通常包含要显示的新网页。HTTP 协议指定了请求和响应的格式,两者均以文本形式表示。图 5.1 显示了描述表单提交的 HTTP 请求示例。要求课程中的学生实现一个或多个类,以使 Web 服务器可以轻松地接收传入的 HTTP 请求并发送响应。
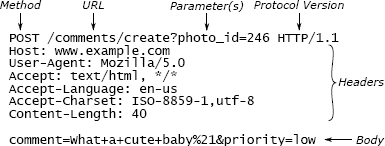
Figure 5.1: A POST request in the HTTP protocol consists of text sent over a TCP socket. Each request contains an initial line, a collection of headers terminated by an empty line, and an optional body. The initial line contains the request type (POST is used for submitting form data), a URL indicating an operation (/comments/create) and optional parameters (photo_id has the value 246), and the HTTP protocol version used by the sender. Each header line consists of a name such as Content-Length followed by its value. For this request, the body contains additional parameters (comment and priority).
图 5.1:HTTP 协议中的 POST 请求包含通过 TCP 套接字发送的文本。每个请求都包含一个初始行,一个由空行终止的标头集合以及一个可选主体。初始行包含请求类型(POST 用于提交表单数据),指示操作(/comments/create)和可选参数(photo_id 的值为 246)的 URL,以及发送方使用的 HTTP 协议版本。每个标题行由一个名称(例如 Content-Length)及其后的值组成。对于此请求,正文包含其他参数(注释和优先级)。
5.5 Example: too many classes 示例:太多的类
The most common mistake made by students was to divide their code into a large number of shallow classes, which led to information leakage between the classes. One team used two different classes for receiving HTTP requests; the first class read the request from the network connection into a string, and the second class parsed the string. This is an example of a temporal decomposition (“first we read the request, then we parse it”). Information leakage occurred because an HTTP request can’t be read without parsing much of the message; for example, the Content-Length header specifies the length of the request body, so the headers must be parsed in order to compute the total request length. As a result, both classes needed to understand most of the structure of HTTP requests, and parsing code was duplicated in both classes. This approach also created extra complexity for callers, who had to invoke two methods in different classes, in a particular order, to receive a request.
学生最常犯的错误是将他们的代码分成大量的浅层类,这导致了类之间的信息泄漏。一个组使用两种不同的类来接收 HTTP 请求。第一类将来自网络连接的请求读取为字符串,第二类将字符串解析。这是时间分解的一个示例(“首先读取请求,然后解析它”)。发生信息泄漏是因为无法解析大量消息就无法读取 HTTP 请求。例如,Content-Length 标头指定了请求主体的长度,因此必须对标头进行解析才能计算总请求长度。结果,这两个类都需要了解 HTTP 请求的大多数结构,并且解析代码在两个类中都是重复的。这种方法也给调用方带来了额外的复杂性,他们必须以特定的顺序调用不同类中的两个方法来接收请求。
Because the classes shared so much information, it would have been better to merge them into a single class that handles both request reading and parsing. This provides better information hiding, since it isolates all knowledge of the request format in one class, and it also provides a simpler interface to callers (just one method to invoke).
由于这些类共享大量信息,因此最好将它们合并为一个同时处理请求读取和解析的类。由于它将请求格式的所有知识隔离在一个类中,因此它提供了更好的信息隐藏,并且还为调用者提供了一个更简单的接口(只是一种调用方法)。
This example illustrates a general theme in software design: information hiding can often be improved by making a class slightly larger. One reason for doing this is to bring together all of the code related to a particular capability (such as parsing an HTTP request), so that the resulting class contains everything related to that capability. A second reason for increasing the size of a class is to raise the level of the interface; for example, rather than having separate methods for each of three steps of a computation, have a single method that performs the entire computation. This can result in a simpler interface. Both of these benefits apply in the example of the previous paragraph: combining the classes brings together all of the code related to parsing an HTTP request, and it replaces two externally-visible methods with one. The combined class is deeper than the original classes.
此示例说明了软件设计中的一般主题:通常可以通过使类稍大一些来改善信息隐藏。这样做的一个原因是将与特定功能相关的所有代码(例如,解析 HTTP 请求)组合在一起,以便生成的类包含与该功能相关的所有内容。增加类大小的第二个原因是提高接口的级别。例如,与其为计算的三个步骤中的每一个步骤使用单独的方法,不如使用一种方法来执行整个计算。这样可以简化接口。这两个优点都适用于上一段的示例:组合类将与解析 HTTP 请求相关的所有代码组合在一起,并且用一个替换了两个外部可见的方法。组合后的类比原有的类都更深。
Of course, it is possible to take the notion of larger classes too far (such as a single class for the entire application). Chapter 9 will discuss conditions under which it makes sense to separate code into multiple smaller classes.
当然,可以将较大的类的概念考虑得太远(例如整个应用程序的单个类)。第 9 章将讨论将代码分成多个较小的类的合理条件。
5.6 Example: HTTP parameter handling 示例:HTTP 参数处理
After an HTTP request has been received by a server, the server needs to access some of the information from the request. The code that handles the request in Figure 5.1 might need to know the value of the photo_id parameter. Parameters can be specified in the first line of the request (photo_id in Figure 5.1) or, sometimes, in the body (comment and priority in Figure 5.1). Each parameter has a name and a value. The values of parameters use a special encoding called URL encoding; for example, in the value for comment in Figure 5.1, “+” is used to represent a space character, and “%21” is used instead of “!”. In order to process a request, the server will need the values for some of the parameters, and it will want them in unencoded form.
服务器收到 HTTP 请求后,服务器需要访问该请求中的某些信息。图 5.1 中处理请求的代码可能需要知道 photo_id 参数的值。参数可以在请求的第一行中指定(图 5.1 中的 photo_id),有时也可以在正文中指定(图 5.1 中的注释和优先级)。每个参数都有一个名称和一个值。参数的值使用一种称为 URL 编码的特殊编码。例如,在图 5.1 中的注释值中,“ +”代表空格字符,“%21”代替“!”。为了处理请求,服务器将需要某些参数的值,并且希望它们采用未编码的形式。
Most of the student projects made two good choices with respect to parameter handling. First, they recognized that server applications don’t care whether a parameter is specified in the header line or the body of the request, so they hid this distinction from callers and merged the parameters from both locations together. Second, they hid knowledge of URL encoding: the HTTP parser decodes parameter values before returning them to the Web server, so that the value of the comment parameter in Figure 5.1 will be returned as “What a cute baby!”, not “What+a+cute+baby%21”). In both of these cases, information hiding resulted in simpler APIs for the code using the HTTP module.
关于参数处理,大多数学生项目都做出了两个不错的选择。首先,他们认识到服务器应用程序不在乎是否在标题行或请求的正文中指定了参数,因此他们对调用者隐藏了这种区别,并将两个位置的参数合并在一起。其次,他们隐藏了 URL 编码的知识:HTTP 解析器在将参数值返回到 Web 服务器之前先对其进行解码,以便图 5.1 中的 comment 参数的值将返回 “What a cute baby!”,而不是 “What+a+cute+baby%21”)。在这两种情况下,信息隐藏都使使用 HTTP 模块的代码的 API 更加简单。
However, most of the students used an interface for returning parameters that was too shallow, and this resulted in lost opportunities for information hiding. Most projects used an object of type HTTPRequest to hold the parsed HTTP request, and the HTTPRequest class had a single method like the following one to return parameters:
但是,大多数学生使用的接口返回的参数太浅,这导致丢失信息隐藏的机会。大多数项目使用 HTTPRequest 类型的对象来保存已解析的 HTTP 请求,并且 HTTPRequest 类具有一种类似于以下方法的单个方法来返回参数:
public Map<String, String> getParams() {
return this.params;
}
Rather than returning a single parameter, the method returns a reference to the Map used internally to store all of the parameters. This method is shallow, and it exposes the internal representation used by the HTTPRequest class to store parameters. Any change to that representation will result in a change to the interface, which will require modifications to all callers. When implementations are modified, the changes often involve changes in the representation of key data structures (to improve performance, for example). Thus, it’s important to avoid exposing internal data structures as much as possible. This approach also makes more work for callers: a caller must first invoke getParams, then it must call another method to retrieve a specific parameter from the Map. Finally, callers must realize that they should not modify the Map returned by getParams, since that will affect the internal state of the HTTPRequest.
该方法不是返回单个参数,而是返回内部用于存储所有参数的映射的引用。这个方法是浅层的,它公开了 HTTPRequest 类用来存储参数的内部表示。对该表示的任何更改都将导致接口的更改,这将需要对所有调用者进行修改。在修改实现时,更改通常涉及关键数据结构表示的更改(例如,为了提高性能)。因此,尽量避免暴露内部数据结构是很重要的。这种方法还为调用者提供了更多的工作:调用者必须首先调用 getParams,然后必须调用另一个方法来从映射中检索特定的参数。最后,调用者必须意识到他们不应该修改 getParams 返回的映射,因为这会影响 HTTPRequest 的内部状态。
Here is a better interface for retrieving parameter values:
这是一个用于检索参数值的更好的接口:
public String getParameter(String name) { ... }
public int getIntParameter(String name) { ... }
getParameter returns a parameter value as a string. It provides a slightly deeper interface than getParams above; more importantly, it hides the internal representation of parameters. getIntParameter converts the value of a parameter from its string form in the HTTP request to an integer (e.g., the photo_id parameter in Figure 5.1). This saves the caller from having to request string-to-integer conversion separately, and hides that mechanism from the caller. Additional methods for other data types, such as getDoubleParameter, could be defined if needed. (All of these methods will throw exceptions if the desired parameter doesn’t exist, or if it can’t be converted to the requested type; the exception declarations have been omitted in the code above).
getParameter 以字符串形式返回参数值。它提供了一个比上面的 getParams 更深的接口;更重要的是,它隐藏了参数的内部表示。getIntParameter 将参数的值从 HTTP 请求中的字符串形式转换为整数(例如,图 5.1 中的 photo_id 参数)。这使调用者不必单独请求字符串到整数的转换,并且对调用者隐藏了该机制。如果需要,可以定义其他数据类型的其他方法,例如 getDoubleParameter。(如果所需的参数不存在,或者无法将其转换为所请求的类型,则所有这些方法都将引发异常;上面的代码中省略了异常声明)。
5.7 Example: defaults in HTTP responses 示例:HTTP 响应中的默认值
The HTTP projects also had to provide support for generating HTTP responses. The most common mistake students made in this area was inadequate defaults. Each HTTP response must specify an HTTP protocol version; one team required callers to specify this version explicitly when creating a response object. However, the response version must correspond to that in the request object, and the request must already be passed as an argument when sending the response (it indicates where to send the response). Thus, it makes more sense for the HTTP classes to provide the response version automatically. The caller is unlikely to know what version to specify, and if the caller does specify a value, it probably results in information leakage between the HTTP library and the caller. HTTP responses also include a Date header specifying the time when the response was sent; the HTTP library should provide a sensible default for this as well.
HTTP 项目还必须提供对生成 HTTP 响应的支持。学生在该领域中最常见的错误是默认值不足。每个 HTTP 响应必须指定一个 HTTP 协议版本。一个组要求呼叫者在创建响应对象时明确指定此版本。但是,响应版本必须与请求对象中的版本相对应,并且在发送响应时必须已将请求作为参数传递(它指示将响应发送到何处)。因此,HTTP 类自动提供响应版本更为有意义。调用者不太可能知道要指定哪个版本,并且如果调用者确实指定了一个值,则可能导致 HTTP 库和调用者之间的信息泄漏。HTTP 响应还包括一个 Date 标头,用于指定发送响应的时间;HTTP 库也应该为此提供一个合理的默认值。
Defaults illustrate the principle that interfaces should be designed to make the common case as simple as possible. They are also an example of partial information hiding: in the normal case, the caller need not be aware of the existence of the defaulted item. In the rare cases where a caller needs to override a default, it will have to know about the value, and it can invoke a special method to modify it.
默认值说明了应该设计接口以使常见情况尽可能简单的原则。它们还是隐藏部分信息的一个示例:在正常情况下,调用者无需知道默认项的存在。在极少数情况下,调用方需要覆盖默认值,它必须知道该值,并且可以调用特殊方法来对其进行修改。
Whenever possible, classes should “do the right thing” without being explicitly asked. Defaults are an example of this. The Java I/O example on page 26 illustrates this point in a negative way. Buffering in file I/O is so universally desirable that noone should ever have to ask explicitly for it, or even be aware of its existence; the I/O classes should do the right thing and provide it automatically. The best features are the ones you get without even knowing they exist.
只要有可能,类就应该“做正确的事”,而无需明确要求。默认值就是一个例子。第 26 页上的 Java I/O 示例以负面方式说明了这一点。普遍希望在文件 I/O 中缓冲,以至于没有人需要明确要求它,甚至不知道它的存在。I/O 类应该做正确的事情并自动提供它。最好的功能是您甚至不知道它们存在的功能。
img Red Flag: Overexposure img
If the API for a commonly used feature forces users to learn about other features that are rarely used, this increases the cognitive load on users who don’t need the rarely used features.
如果一个常用特性的 API 迫使用户了解其他很少使用的特性,这将增加不需要这些很少使用的特性的用户的认知负荷。
5.8 Information hiding within a class 信息隐藏在类中
The examples in this chapter focused on information hiding as it relates to the externally visible APIs for classes, but information hiding can also be applied at other levels in the system, such as within a class. Try to design the private methods within a class so that each method encapsulates some information or capability and hides it from the rest of the class. In addition, try to minimize the number of places where each instance variable is used. Some variables may need to be accessed widely across the class, but others may be needed in only a few places; if you can reduce the number of places where a variable is used, you will eliminate dependencies within the class and reduce its complexity.
本章中的示例着重于信息隐藏,因为它与类的外部可见 API 有关,但是信息隐藏也可以应用于系统中的其他级别,例如类内。尝试在一个类中设计私有方法,以便每个方法都封装一些信息或功能,并将其隐藏在类的其余部分中。此外,请尽量减少使用每个实例变量的位置数量。有些变量可能需要在整个类中广泛使用,但是其他变量可能只需要在少数地方使用;如果可以减少使用变量的位置的数量,则将消除类内的依赖关系并降低其复杂性。
5.9 Taking it too far 走得太远
Information hiding only makes sense when the information being hidden is not needed outside its module. If the information is needed outside the module, then you must not hide it. Suppose that the performance of a module is affected by certain configuration parameters, and that different uses of the module will require different settings of the parameters. In this case it is important that the parameters are exposed in the interface of the module, so that they can be turned appropriately. As a software designer, your goal should be to minimize the amount of information needed outside a module; for example, if a module can automatically adjust its configuration, that is better than exposing configuration parameters. But, it’s important to recognize which information is needed outside a module and make sure it is exposed.
仅当在其模块外部不需要隐藏信息时,隐藏信息才有意义。如果模块外部需要该信息,则不得隐藏它。假设模块的性能受某些配置参数的影响,并且模块的不同用途将需要对参数进行不同的设置。在这种情况下,将参数暴露在模块的接口中很重要,以便可以对其进行适当的调整。作为软件设计师,您的目标应该是最大程度地减少模块外部所需的信息量。例如,如果模块可以自动调整其配置,那将比公开配置参数更好。但是,重要的是要识别模块外部需要哪些信息,并确保将其公开。
5.10 Conclusion 结论
Information hiding and deep modules are closely related. If a module hides a lot of information, that tends to increase the amount of functionality provided by the module while also reducing its interface. This makes the module deeper. Conversely, if a module doesn’t hide much information, then either it doesn’t have much functionality, or it has a complex interface; either way, the module is shallow.
信息隐藏和深层模块密切相关。如果模块隐藏了很多信息,则往往会增加模块提供的功能,同时还会减少其接口。这使模块更深。相反,如果一个模块没有隐藏太多信息,则它要么功能不多,要么接口复杂。无论哪种方式,模块都是浅的。
When decomposing a system into modules, try not to be influenced by the order in which operations will occur at runtime; that will lead you down the path of temporal decomposition, which will result in information leakage and shallow modules. Instead, think about the different pieces of knowledge that are needed to carry out the tasks of your application, and design each module to encapsulate one or a few of those pieces of knowledge. This will produce a clean and simple design with deep modules.
将系统分解为模块时,请尽量不要受运行时操作顺序的影响。这将使您沿着时间分解的路径前进,这将导致信息泄漏和模块浅。相反,请考虑执行应用程序任务所需的不同知识,并设计每个模块以封装这些知识中的一个或几个。这将产生一个干净简单的深模块设计。
1 David Parnas, “On the Criteria to be Used in Decomposing Systems into Modules,” Communications of the ACM, December 1972.
1 David Parnas,“关于将系统分解为模块的标准”,ACM 通讯,1972 年 12 月。