
MESI 协议
MESI 协议
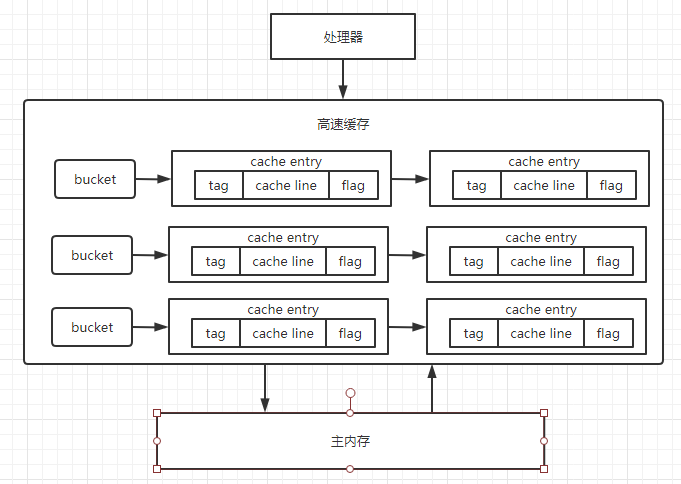
高速缓存内部是一个拉链哈希表,是不是很眼熟,是的,和 HashMap 的内部结构十分相似,高速缓存中分为很多桶,每个桶里用链表的结构连接了很多 cache entry,在每一个 cache entry 内部主要由三部分内容组成:
- tag:指向了这个缓存数据在主内存中的数据的地址
- cache line:存放多个变量数据
- flag:缓存行状态
各个处理器在操作内存数据时,都会往总线发送消息,各个处理器还会不停的从总线嗅探消息,通过这个消息来保证各个处理器的协作。同时 MESI 中有以下两个操作:
- flush 操作:强制处理器在更新完数据后,将更新的数据(可能写缓冲器、寄存器中)刷到高速缓存或者主内存(不同的硬件实现 MESI 协议的方式不一样),同时向总线发出信息说明自己修改了某一数据
- refresh 操作:从总线嗅探到某一数据失效后,将该数据在自己的缓存中失效,然后从更新后的处理器高速缓存或主内存中加载数据到自己的高速缓存中
CPU 读写流程
传统的 MESI 协议中有两个行为的执行成本比较大。一个是将某个 Cache Line 标记为 Invalid 状态,另一个是当某 Cache Line 当前状态为 Invalid 时写入新的数据。所以 CPU 通过 Store Buffer 和 Invalidate Queue 组件来降低这类操作的延时。如图:
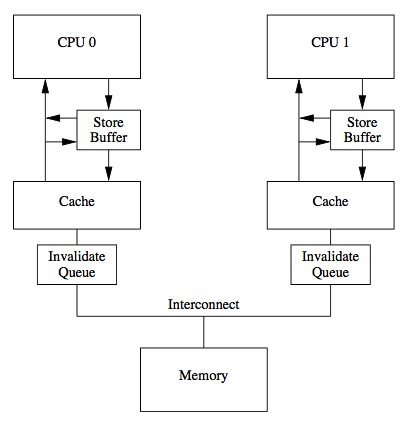
当一个核心在 Invalid 状态进行写入时,首先会给其它 CPU 核发送 Invalid 消息,然后把当前写入的数据写入到 Store Buffer 中。然后异步在某个时刻真正的写入到 Cache Line 中。当前 CPU 核如果要读 Cache Line 中的数据,需要先扫描 Store Buffer 之后再读取 Cache Line(Store-Buffer Forwarding)。但是此时其它 CPU 核是看不到当前核的 Store Buffer 中的数据的,要等到 Store Buffer 中的数据被刷到了 Cache Line 之后才会触发失效操作。而当一个 CPU 核收到 Invalid 消息时,会把消息写入自身的 Invalidate Queue 中,随后异步将其设为 Invalid 状态。和 Store Buffer 不同的是,当前 CPU 核心使用 Cache 时并不扫描 Invalidate Queue 部分,所以可能会有极短时间的脏读问题。
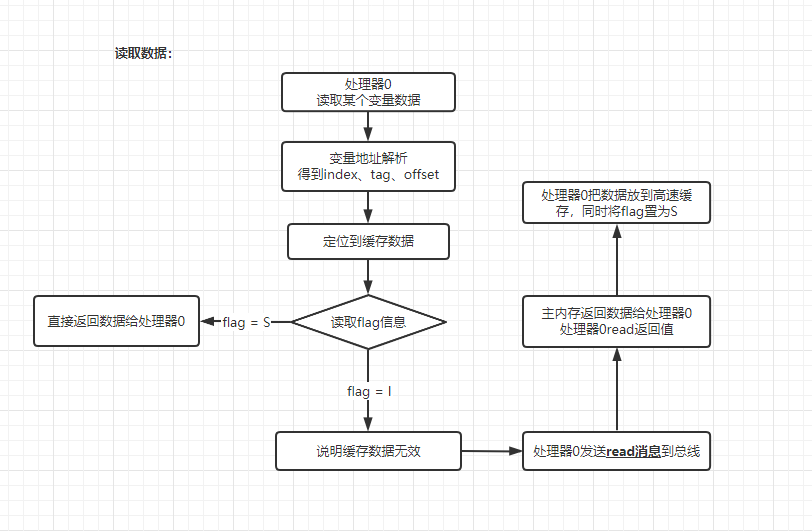
接下来我们来说明在两个处理器情况下,其中一个处理器(处理器 0)要修改数据的整个过程。假定数据所在 cache line 在两个高速缓存中都处于 S(Shared)状态。
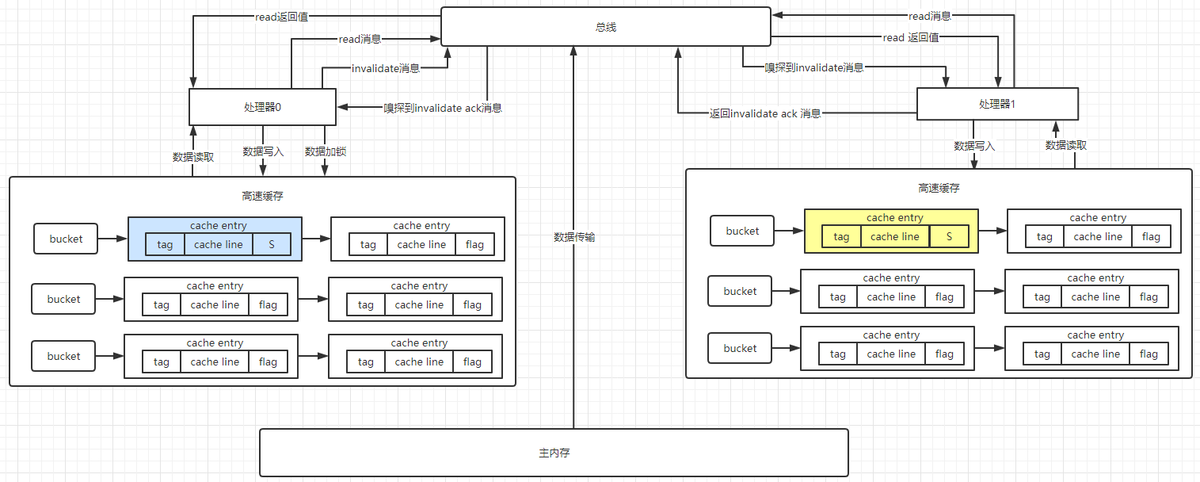
- 处理器 0 发送 invalidate 消息到总线;
- 处理器 1 在总线上进行嗅探,嗅探到 invalidate 消息后,通过地址解析定位到对应的 cache line,发现此时 cache line 的状态为 S,则将 cache line 的状态改为 I,同时返回 invalidate ack 消息到总线;
- 处理器 0 在总线在嗅探到所有(例子中只有处理器 1)的 invalidate ack 后,将要修改的 cache line 状态置为 E(Exclusive),表示要进行独占修改,修改完以后将 cache line 状态置为 M(Modified),同时可能将数据刷回主内存。
在这个过程中,如有其他处理器要修改处理器 0 中的 cache line 状态将会被阻塞。同时,假如此时处理器 1 要读取相应的 cache line 数据,则会发现状态为 I(Invalid)。于是处理器 1 向总线中发出 read 消息,处理器 0 嗅探到 read 消息后,将会从自己的高速缓存或者主内存中将数据发送到总线,并将自身对应的 cache line 状态置为 S(Shared),处理器 1 从总线中接收到 read 消息后,将最新的数据写入到对应的 cache line,并将状态置为 S(Shared)。由此处理 0 与处理器 1 中对应的 cache line 状态又都变成了 S(Shared)。
更新和读取数据的过程如下所示:
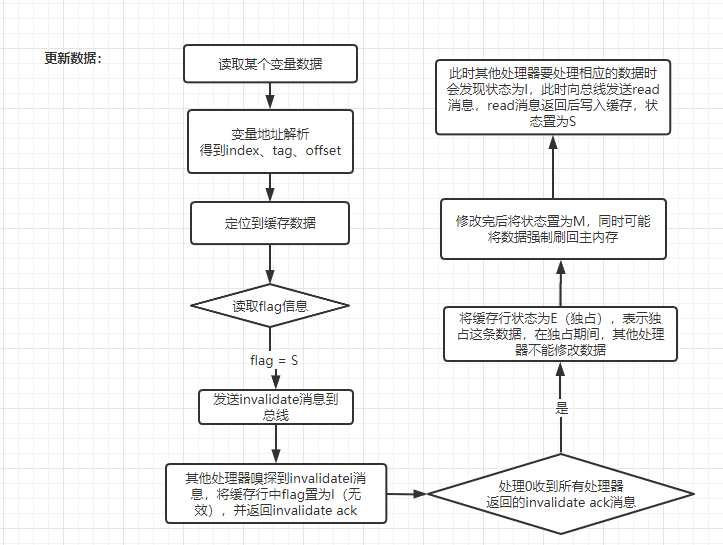
MESI 协议能保证各个处理器间的高速缓存数据一致性,但是同样带来两个严重的效率问题:
- 当处理器 0 向总线发送 invalidate 消息后,要等到所有其他拥有相同缓存的处理器返回 invalidate ack 消息才能将对应的 cache line 状态置为 E 并进行修改,但是在这过程中它一直是处于阻塞状态,这将严重影响处理器的性能
- 当处理 1 嗅探到 invalidate 消息后,会先去将对应的 cache line 状态置为 I,然后才会返回 invalidate ack 消息到总线,这个过程也是影响性能的。
基于以上两个问题,设计者又引入了写缓冲器和无效队列。在上面的场景中,处理器 0,先将要修改的数据放入写缓冲器,再向总线发出 invalidate 消息来通知其他有相同缓存的处理器缓存失效,处理器 0 就可以继续执行其他指令,当接收到其他所有处理器的 invalidate ack 后,再将处理器 0 中的 cache line 置为 E,并将写缓冲器中的数据写入高速缓存。处理器 1 从总线嗅探到 invalidate 消息后,先将消息放入到无效队列,接着立刻返回 invalidate ack 消息。这样来提高处理的速度,达到提高性能的目的。
写缓冲器和无效队列提高 MESI 协议下处理器性能,但同时也带来了新的可见性与有序性问题如下:
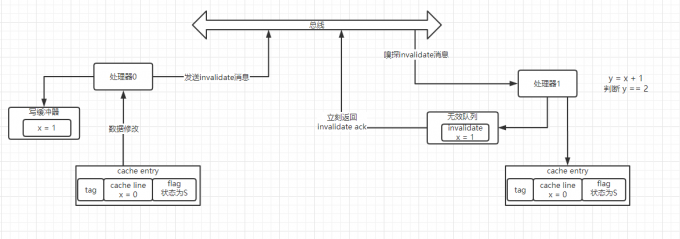
如上图所示:假设最初共享变量 x=0 同时存在于处理 0 和处理 1 的高速缓存中,且对应状态为 S(Shared),此时处理 0 要将 x 的值改变成 1,先将值写到写缓冲器里,然后向总线发送 invalidate 消息,同时处理器 1 希望将 x 的值加 1 赋给 y,此时处理器 1 发现自身缓存中 x=0 状态为 S,则直接用 x=0 进行参与计算,从而发生了错误,显然这个错误由写缓冲器和无效队列导致的,因为 x 的新值还在写缓冲器中,无效消息在处理 1 的无效队列中。
典型案例:并发加
可见性问题最经典的案例即是并发加操作,如下两个线程同时在更新变量 test 的 count 属性域的值,第一次都会将 count=0 读到各自的 CPU 缓存里,执行完 count+=1 之后,各自 CPU 缓存里的值都是 1,同时写入内存后,我们会发现内存中是 1,而不是我们期望的 2。之后由于各自的 CPU 缓存里都有了 count 的值,两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。
Thread th1 = new Thread(()->{
test.add10K();
});
Thread th2 = new Thread(()->{
test.add10K();
});
// 每个线程中对相同对象执行加操作
count += 1;
在 Java 中,如果多个线程共享一个对象,并且没有合理的使用 volatile 声明和线程同步,一个线程更新共享对象后,另一个线程可能无法取到对象的最新值。当一个共享变量被 volatile 修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。通过 synchronized 和 Lock 也能够保证可见性,synchronized 和 Lock 能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
Links
- 并发吹剑录(一):CPU 缓存一致性协议 MESI https://cubox.pro/c/QsiEBF