
04.复制
MongoDB Replication
一、副本集
1.1 复制功能
为保证数据安全,实现高可用,MongoDB 提供了复制功能,可以将主节点上的数据复制到多个从节点上,这样即便主节点出现异常,由于数据是以多副本的方式进行存储,仍然可以保证数据安全。一个标准的三节点副本集架构如下:
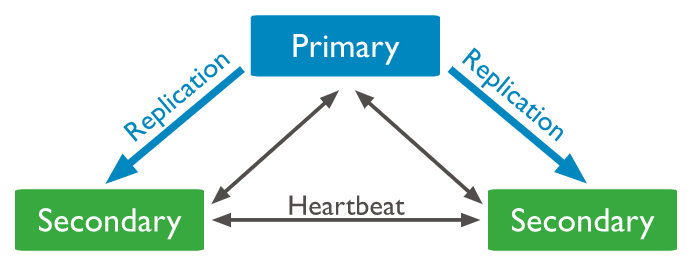
复制过程如下:
1. 初始同步
在副本集初始化时,主节点的 mongod 进程会扫描当前节点上每个数据库中的每个集合,然后将这些数据发送给从节点,进行初始化的全量复制。
2. 同步复制
从节点在初始化完成后,不断同步地复制主节点的 oplog 数据。oplog (操作日志) 是一个特殊的集合,它存储了数据库中所有数据的操作记录。oplog 中的每个操作都具有幂等性,即每个操作对目标数据集无论是应用一次还是多次,都会产生相同的结果。
3. 异步执行
MongoDB 按 namespace 或 document id 对每批操作进行分组,并使用不同的线程应用每组操作,同时 MongoDB 会严格按照原始写入顺序将写入操作应用于从节点上的文档。
1.2 仲裁者
除了可以将正常的 mongod 实例添加到副本集外, 还可以将额外的 mongod 实例添加到副本集作为仲裁者。仲裁者不承担数据的读写操作,它只用于响应选举请求并参与仲裁。因为它不存储数据,所以可以占用更少的服务器资源,如果你的副本集具有偶数个成员,可以通过添加仲裁者来保证有效选举。
虽然仲裁者可以占用更少的服务器资源,但是由于其并不存储数据,所以对数据的安全性并不能起到帮助作用。因此应该尽量避免使用仲裁者,同时尽量保证最多只使用一个仲裁者,即如果节点数量恰好是偶数,则添加一个仲裁者,如果节点数量是奇数,那就不需要仲裁者。

二、故障发现与恢复
2.1 故障发现
副本集的每个节点之间会维持着两秒一次的心跳检测,当从节点与主节点的通信时间超过配置的 electionTimeoutMillis 时间 (默认为 10 秒) 时,则认为该主节点出现故障,此时副本集会进行新的主节点选举。
2.2 优先选举
MongoDB 的选举算法会尝试让高优先级的节点优先发起选举,从而更容易在选举中胜出。如果某一个优先级较低的节点在短时间内被选举为新的主节点,这时副本集仍然会继续发起选举,直至可用的最高优先级的节点成为新的主节点。需要特别注意的是在这个过程当中,优先级为 0 的成员不能寻求选举,也不能成为主节点。
2.3 投票成员
节点发起选举后,需要具有投票权的节点进行投票,当获得半数以上选票时,该备用节点可以成为新的主节点。对于一个复制集,只有处于以下状态的节点拥有投票权,这些节点统称为投票成员:
- PRIMARY:副本集的主节点。
- SECONDARY:处于复制状态的从节点。
- STARTUP2:mongod 完成配置加载后,副本集的每个成员都进入 STARTUP2 状态,此时它成为副本集的活动成员并且有资格投票。然后该成员决定是否进行初始同步。如果成员开始初始同步,则成员将保留在 STARTUP2 状态,直到所有数据复制完成并构建好索引。之后成员过渡到 RECOVERING。
- RECOVERING:当副本集的成员尚未准备好接受读取操作时,它将进入 RECOVERING 状态。处于恢复状态的成员有资格在选举中投票,但没有资格成为主节点。
- ARBITER:ARBITER 状态的成员不复制数据或接受写入操作,仲裁者通常处于这一状态。
- ROLLBACK:如果成员正在进行数据回滚,它就处于 ROLLBACK 状态。
除了投票成员外,那些持有副本集数据的副本,并且可以接受来自客户端应用程序的读取操作,但没有投票权的成员统称为非投票成员。出于网络通讯成本的考虑,MongoDB 的副本集最多有 50 个节点(成员),默认情况下最多可包含 7 个投票成员。投票成员和非投票成员的要求如下:
- 非投票成员的优先级
members[n].priority必须为 0,优先级为 0 的成员不能寻求选举,也不能成为主节点。 - 优先级大于 0 的节点持有的票数
members[n].votes不能为 0,该参数默认值为 1,可选值为 1 或 0。
如下示例是一个 9 个成员的副本集,包含 7 个投票成员和 2 个无投票成员:

三、搭建副本集
这里以搭建一个三节点的副本集为例,使用三台服务器,主机名分别为 hadoop001,hadoop002,hadoop003。
3.1 下载并解压
选择所需版本的 MongoDB 进行下载,下载地址为: https://www.mongodb.com/download-center/community
这里我下载的版本为 4.0.10 , 安装环境为 RHEL 7.0,下载后进行解压:
tar -zxvf mongodb-linux-x86_64-rhel70-4.0.10.tgz -C /usr/app
3.2 配置环境变量
配置环境变量:
vi /etc/profile
export MONGODB_HOME=/usr/app/mongodb-linux-x86_64-rhel70-4.0.10/
export PATH=${MONGODB_HOME}/bin:$PATH
使得配置的环境变量立即生效:
source /etc/profile
3.3 修改配置
MongoDB 默认存放数据的目录为 /var/lib/mongo ,默认存放日志的目录为 /var/log/mongodb,采用 TGZ 安装包进行安装时,程序不会自动创建这两个目录,需要预先手动创建。同时由于 /var/ 下只能存放临时文件,所以这里我们使用其他目录进行存储,命令如下:
mkdir -p /home/mongodb/data
mkdir -p /home/mongodb/log
修改配置,采用 TGZ 安装包进行安装时,程序不会自动创建配置文件,需要手动创建:
vim /etc/mongod.conf
在配置文件中增加如下配置,这里的配置采用的是 YAML 的格式:
processManagement:
# 以后台进程的方式启动
fork: true
systemLog:
destination: file
path: "/home/mongodb/log/mongod.log"
logAppend: true
storage:
dbPath: "/home/mongodb/data"
net:
port: 27017
# 如果不修改绑定IP,默认只能在本机访问数据库服务
bindIp: 0.0.0.0
replication:
# 处于同一副本集的所有节点需要保证副本集名称一致
replSetName: rs0
MongoDB 的所有配置项可以参考其官方文档:Configuration File Options
3.4 启动服务
以上配置步骤在三台主机上均相同。之后启动三台主机上的 mongod 服务,命令如下:
mongod -f /etc/mongod.conf
3.5 配置副本集
在任意一台主机上使用 mongo shell 连接到本地服务,之后直接使用以下命令配置副本集:
rs.initiate( {
_id : "rs0",
members: [
{ _id: 0, host: "hadoop001:27017" },
{ _id: 1, host: "hadoop002:27017" },
{ _id: 2, host: "hadoop003:27017" }
]
})
3.6 查看副本集情况
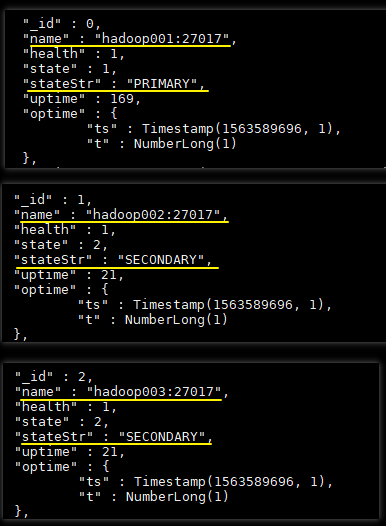
使用 rs.status() 命令查看副本集状态,部分输出如下。从输出中可以看到 hadoop001 为 PRIMARY 节点,而 hadoop002 和 hadoop003 均为 SECONDARY 节点,此时代表副本集已经搭建成功。
参考资料
- 官方文档:https://docs.mongodb.com/manual/replication/
- 官方配置说明:https://docs.mongodb.com/manual/reference/configuration-options/