
3.数据湖
数据湖
为什么需要数据湖?
以 Databricks 推出的 delta 为例,它要解决的核心问题基本上集中在下图:
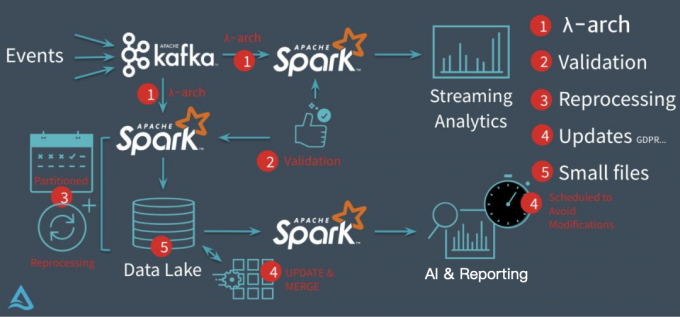
在没有 delta 数据湖之前,Databricks 的客户一般会采用经典的 lambda 架构来构建他们的流批处理场景。以用户点击行为分析为例,点击事件经 Kafka 被下游的 Spark Streaming 作业消费,分析处理(业务层面聚合等)后得到一个实时的分析结果,这个实时结果只是当前时间所看到的一个状态,无法反应时间轴上的所有点击事件。所以为了保存全量点击行为,Kafka 还会被另外一个 Spark Batch 作业分析处理,导入到文件系统上(一般就是 parquet 格式写 HDFS 或者 S3,可以认为这个文件系统是一个简配版的数据湖),供下游的 Batch 作业做全量的数据分析以及 AI 处理等。
这套方案其实存在很多问题
第一、批量导入到文件系统的数据一般都缺乏全局的严格 schema 规范,下游的 Spark 作业做分析时碰到格式混乱的数据会很麻烦,每一个分析作业都要过滤处理错乱缺失的数据,成本较大;
第二、数据写入文件系统这个过程没有 ACID 保证,用户可能读到导入中间状态的数据。所以上层的批处理作业为了躲开这个坑,只能调度避开数据导入时间段,可以想象这对业务方是多么不友好;同时也无法保证多次导入的快照版本,例如业务方想读最近 5 次导入的数据版本,其实是做不到的。
第三、用户无法高效 upsert/delete 历史数据,parquet 文件一旦写入 HDFS 文件,要想改数据,就只能全量重新写一份的数据,成本很高。事实上,这种需求是广泛存在的,例如由于程序问题,导致错误地写入一些数据到文件系统,现在业务方想要把这些数据纠正过来;线上的 MySQL Binlog 不断地导入 update/delete 增量更新到下游数据湖中;某些数据审查规范要求做强制数据删除,例如欧洲出台的 GDPR 隐私保护等等。
第四、频繁地数据导入会在文件系统上产生大量的小文件,导致文件系统不堪重负,尤其是 HDFS 这种对文件数有限制的文件系统。
数据湖对比
| 特性 | Table Schema | 抽象程度高,不绑定 Engine | ACID 语义保证,多版本保证 | 廉价存储 | Python 接口支持 | 流批读写 | 快速 CUDR 和 Pull 增量 | 企业级性能优化 |
|---|---|---|---|---|---|---|---|---|
| Delta | 有 | 无 | 有 | 有 | 有 | 有 | 无 | 无 |
| Hudi | 无 | 无 | 有 | 有 | 无 | 有 | 有 | 无 |
| Iceberg | 有 | 有 | 有 | 有 | 有 | 有 | 无 | 有 |