
介绍与部署
Hive
Hive 最初是应 Facebook 每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的,其介于 Pig 和传统 RDBMS(关系数据库管理系统 Relational DatabaseManagement System)之间,Hive 的设计目的是让精通 SQL 既能的分析师能够在存放在 HDFS 的大规模数据集上运行查询。Hive 在很多方面和传统数据库类似,但是它底层对 HDFS 和 MapReduce 的依赖意味着它的体系结构有别于传统数据库。
| **Hive ** | **RDBMS ** | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 执行 | MapReduce | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 索引 | 0.8 版本后加入位图索引 | 有复杂的索引 |
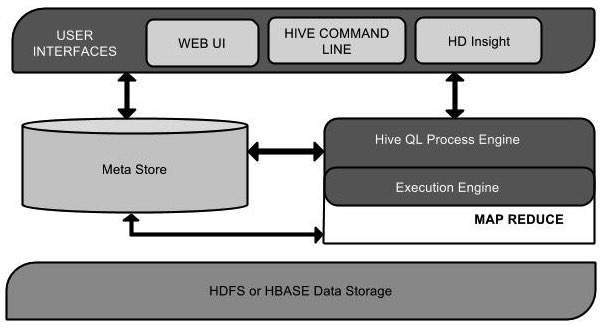
Hive 提供了一系列的工具,可用来对数据进行提取/转化/加载(ETL),是一种可以存储、查询和分析存储在 HDFS(或者 HBase)中的大规模数据的机制。Hive 本身不存储数据,完全依赖于 HDFS 和 MapReduce,Hive 可以将结构化的数据文件映射为一张数据库表,Hive 中表纯逻辑,就是表的元数据。而 HBase 是物理表,定位是 NoSQL。Hive 定义了一种类似 SQL 的查询语言,被称为 HQL,对于熟悉 SQL 的用户可以直接利用 Hive 来查询数据。同时,这个语言也允许熟悉 MapReduce 开发者们开发自定义的 mappers 和 reducers 来处理内建的 mappers 和 reducers 无法完成的复杂的分析工作。Hive 可以允许用户编写自己定义的函数 UDF,来在查询中使用。Hive 中有 3 种 UDF:User Defined Functions(UDF)、User Defined Aggregation Functions(UDAF)、User Defined Table Generating Functions(UDTF)。
Architecture
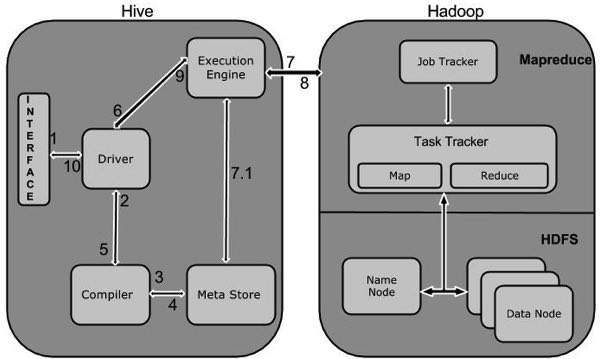
Workflow
| 步骤 | 操作 |
|---|---|
| 1 | Execute Query 类似于 Command Line 或者 Web UI 这样的 Hive 交互工具将用户输入的查询发送到 Driver,JDBC 或者 ODBC |
| 2 | Get Plan Diver 利用 Query Compiler 来解析 Query 以检查语法或者需要进行该查询的需求, |
| 3 | Get Metadata Compiler 将 Metadata 请求发送到 MetaStore(可以是任意数据库), |
| 4 | Send Metadata Metastore 发送 Metadata 作为回应到 Compiler, |
| 5 | Send Plan Compiler 检查下需求然后将 Plan 发送到 Driver,到现在,关于查询的解析与编译就完成了, |
| 6 | Execute Plan Driver 将执行方案发送到执行引擎, |
| 7 | Execute Job 内部来说,Job 会被当做 MapReduce 任务进行执行。执行引擎将该任务发送给位于 NameNode 的 JobTracker,而后 JobTracker 会将任务分配给位于 DataNode 的 TaskTracker,在这里会具体的执行 MapReduce 任务 |
| 7.1 | Metadata Ops 执行过程中,执行引擎也能够在 MetaStore 中进行元数据操作, |
| 8 | Fetch Result 执行引擎从数据节点抓取到结果 |
| 9 | Send Results 执行引擎将查询结果返回为 Driver |
| 10 | Send Results Driver 将结果发送返回给 Hive 交互界面 |
Quick Start
Installation
笔者建议使用 Docker 镜像作为快速搭建的工具,可参考本部分最后章节。首先需要安装 Hadoop,详细的安装请参考笔者的Hadoop 初探与环境搭建。然后需要在这里下载 Hive 的预编译好的版本。下载完毕后可以解压缩该文件:
$ tar zxvf apache-hive-0.14.0-bin.tar.gz
$ ls
然后需要将文件复制到/user/local/hive 目录下:
$ su -
passwd:
# cd /home/user/Download
# mv apache-hive-0.14.0-bin /usr/local/hive
# exit
然后我们需要将 Hive 的类库与可运行文件添加到环境变量中,可以选择添加到~/.bashrc文件:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
然后需要激活该文件:
$ source ~/.bashrc
为了配置 Hive 可以与 Hadoop 正常工作,需要配置hive-env.sh文件,其位于$HIVE_HOME/conf 目录下:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
编辑 hive-env.sh 然后添加如下行:
export HADOOP_HOME=/usr/local/hadoop
Metastore
我们这里选择 Apache Derby 作为元数据存储的数据库:
$ cd ~
$ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz
$ ls
$ su -
passwd:
# cd /home/user
# mv db-derby-10.4.2.0-bin /usr/local/derby
# exit
下载完毕后需要为 Derby 构建运行环境:
export DERBY_HOME=/usr/local/derby
export PATH=$PATH:$DERBY_HOME/bin
Apache Hive
18
export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar
然后我们需要创建一个新的目录来存储 Metastore 数据:
$ mkdir $DERBY_HOME/data
接下来我们需要配置 Hive 连接 Derby 的 JDBC 配置:
$ cd $HIVE_HOME/conf
$ cp hive-default.xml.template hive-site.xml
编辑 hive-site.xml 文件然后添加如下行:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby://localhost:1527/metastore_db;create=true </value>
<description>JDBC connect string for a JDBC metastore </description>
</property>
创建如下名为 jpox.properties 的配置文件,然后添加如下行:
javax.jdo.PersistenceManagerFactoryClass =
org.jpox.PersistenceManagerFactoryImpl
org.jpox.autoCreateSchema = false
org.jpox.validateTables = false
org.jpox.validateColumns = false
org.jpox.validateConstraints = false
org.jpox.storeManagerType = rdbms
org.jpox.autoCreateSchema = true
org.jpox.autoStartMechanismMode = checked
org.jpox.transactionIsolation = read_committed
javax.jdo.option.DetachAllOnCommit = true
javax.jdo.option.NontransactionalRead = true
javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver
javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true
javax.jdo.option.ConnectionUserName = APP
javax.jdo.option.ConnectionPassword = mine
Verification
在启动 Hive 之前,需要在 HDFS 中创建/tmp 文件夹,这里我们选择 /user/hive/warehouse 文件夹作为数据存储文件,我们需要为该文件夹添加写权限:
chmod g+w
完整的命令如下:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
然后我们可以使用如下命令来验证 Hive 是否安装成功:
$ cd $HIVE_HOME
$ bin/hive
如果你成功地安装了 Hive,那么你会得到如下的提示:
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/hive-log4j.properties
Hive history file=/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt
………………….
hive>
然后可以使用如下命令来列举所有的表:
hive> show tables;
OK
Time taken: 2.798 seconds
hive>
Docker
笔者基于sequenceiq/hadoop-docker以及 Postgres 数据库构建了简单的伪分布式模式的 Hive 镜像,Dockerfile内容如下:
# 使用该Hadoop镜像
FROM sequenceiq/hadoop-docker:2.7.1
MAINTAINER WxChevalier
#Based on Inmobi Hive
#Builds the InMobi Hive from trunk
#Configure Postgres DB
#Starts Hive metastore Server
#Starts Hive Server2
# 安装Postgres作为Hive元数据存储
RUN apt-get update
RUN apt-get -yq install vim postgresql-9.3 libpostgresql-jdbc-java
# 创建元数据库 创建Hive用户并且分配权限privileges
USER postgres
RUN /etc/init.d/postgresql start &&\
psql --command "CREATE DATABASE metastore;" &&\
psql --command "CREATE USER hive WITH PASSWORD 'hive';" && \
psql --command "ALTER USER hive WITH SUPERUSER;" && \
psql --command "GRANT ALL PRIVILEGES ON DATABASE metastore TO hive;"
# 切回到默认的root用户
USER root
# 构建开发工具
RUN apt-get update
RUN apt-get install -y git libprotobuf-dev protobuf-compiler
# 安装Maven
RUN curl -s http://mirror.olnevhost.net/pub/apache/maven/binaries/apache-maven-3.2.1-bin.tar.gz | tar -xz -C /usr/local/
RUN cd /usr/local && ln -s apache-maven-3.2.1 maven
ENV MAVEN_HOME /usr/local/maven
ENV PATH $MAVEN_HOME/bin:$PATH
# 下载并且编译Hive
ENV HIVE_VERSION 0.13.4-inm-SNAPSHOT
RUN cd /usr/local && git clone https://github.com/InMobi/hive.git
RUN cd /usr/local/hive && /usr/local/maven/bin/mvn clean install -DskipTests -Phadoop-2,dist
RUN mkdir /usr/local/hive-dist && tar -xf /usr/local/hive/packaging/target/apache-hive-${HIVE_VERSION}-bin.tar.gz -C /usr/local/hive-dist
# 设定Hive环境信息
ENV HIVE_HOME /usr/local/hive-dist/apache-hive-${HIVE_VERSION}-bin
ENV HIVE_CONF $HIVE_HOME/conf
ENV PATH $HIVE_HOME/bin:$PATH
# 添加Postgres JDBC连接包
RUN ln -s /usr/share/java/postgresql-jdbc4.jar $HIVE_HOME/lib/postgresql-jdbc4.jar
# to avoid psql asking password, set PGPASSWORD
ENV PGPASSWORD hive
# 初始化Hive 元数据库
RUN /etc/init.d/postgresql start &&\
cd $HIVE_HOME/scripts/metastore/upgrade/postgres/ &&\
psql -h localhost -U hive -d metastore -f hive-schema-0.13.0.postgres.sql
# 复制配置文件、SQL以及数据文件
RUN mkdir /opt/files
ADD hive-site.xml /opt/files/
ADD hive-log4j.properties /opt/files/
ADD hive-site.xml $HIVE_CONF/hive-site.xml
ADD hive-log4j.properties $HIVE_CONF/hive-log4j.properties
ADD store_sales.* /opt/files/
ADD datagen.py /opt/files/
# 为Hive 启动配置设定权限
ADD hive-bootstrap.sh /etc/hive-bootstrap.sh
RUN chown root:root /etc/hive-bootstrap.sh
RUN chmod 700 /etc/hive-bootstrap.sh
# To overcome the bug in AUFS that denies postgres permission to read /etc/ssl/private/ssl-cert-snakeoil.key file.
# https://github.com/Painted-Fox/docker-postgresql/issues/30
# https://github.com/docker/docker/issues/783
# To avoid this issue lets disable ssl in postgres.conf. If we really need ssl to encrypt postgres connections we have to fix permissions to /etc/ssl/private directory everytime until AUFS fixes the issue
ENV POSTGRESQL_MAIN /var/lib/postgresql/9.3/main/
ENV POSTGRESQL_CONFIG_FILE $POSTGRESQL_MAIN/postgresql.conf
ENV POSTGRESQL_BIN /usr/lib/postgresql/9.3/bin/postgres
ADD postgresql.conf $POSTGRESQL_MAIN
RUN chown postgres:postgres $POSTGRESQL_CONFIG_FILE