
DeepLearning-Notes




![]()

深度学习实战
在深度学习篇中,我们将了解深度学习的历史与理论。深度学习的起点即是所谓的神经网络(Neural Network)。
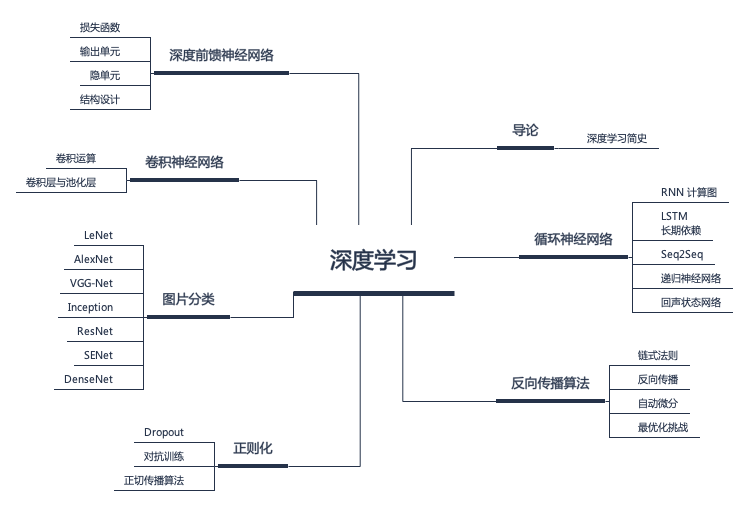
NN | 神经网络基础
神经网络层的基本组成成员为神经元,神经元包含两部分,一部分是上一层网络输出和当前网络层参数的一个线性乘积,另外一部分是线性乘积的非线性转换;如果缺少非线性转换,则多层线性乘积可以转化为一层的线性乘积。
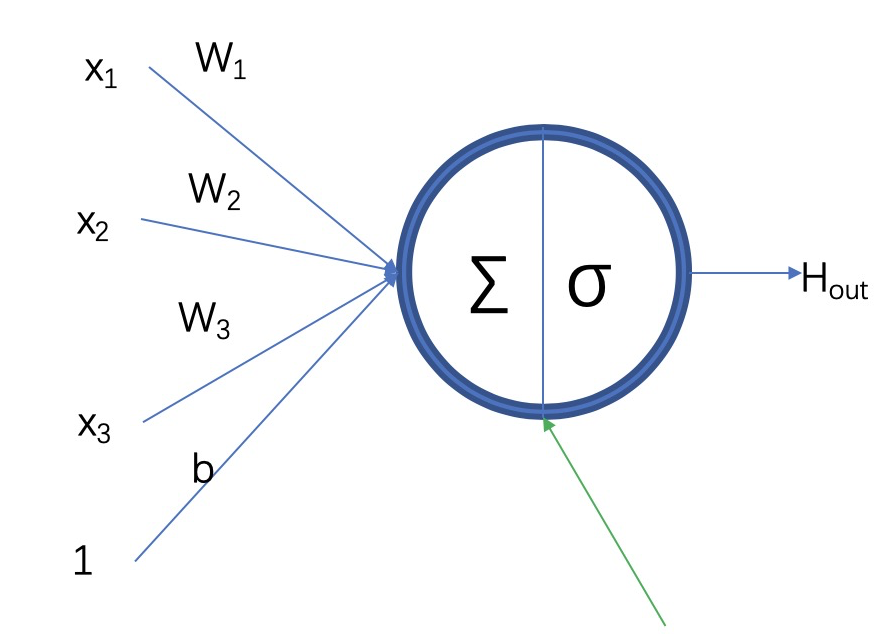
$$ \begin{array}{l}{\mathrm{H}(\mathrm{in})=\Sigma=\mathrm{W}{1} \star \mathrm{x}{1}+\mathrm{W}{2} \star \mathrm{x}{2}+\mathrm{W}{3} \star \mathrm{x}{3}+\mathrm{b}} \ {\mathrm{H}(\mathrm{out})=\sigma(\Sigma)}\end{array} $$
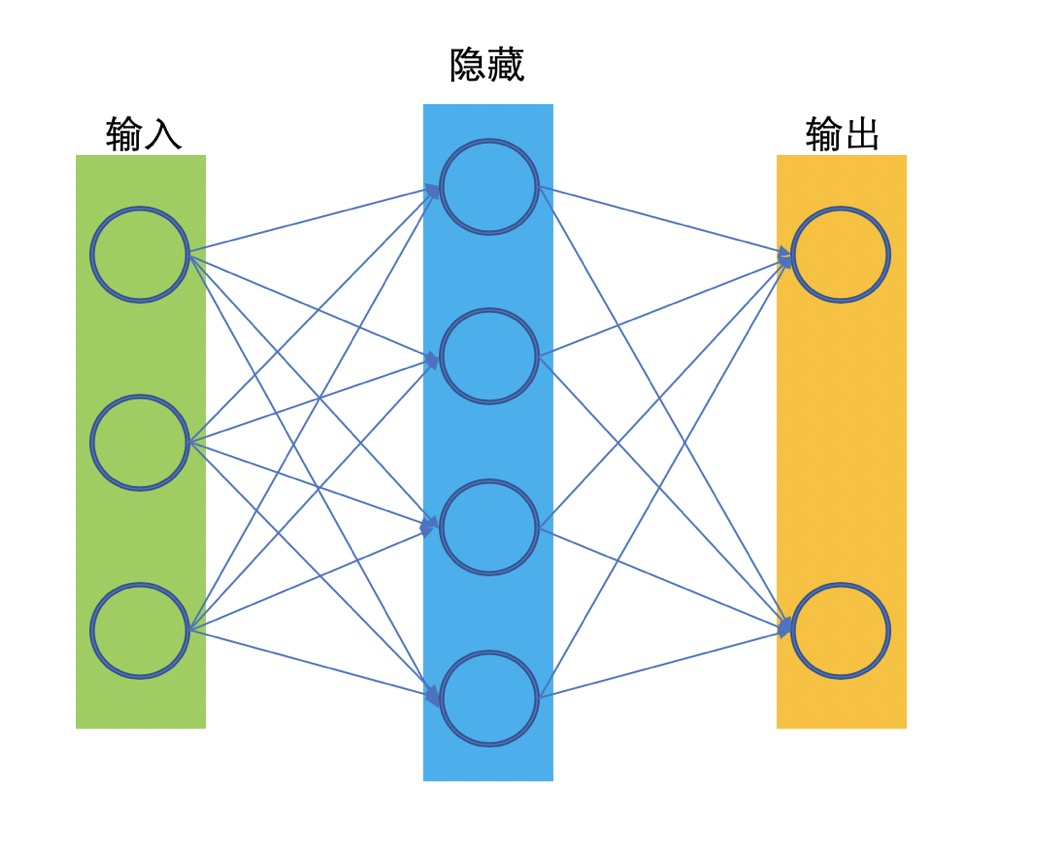
一个神经网络结构通常包含输入层,隐藏层,输出层。输入层是我们的 特征(features),输出层是我们的预测(prediction)。神经网络的目的是拟合一个函数 $f*: features -> prediction$,在训练期间,通过减小 prediction 和 实际 label 的差异的这种方式, 来更改网络参数,来使当前的网络能逼近于理想的函数 $f*$。而对于仅有单个隐藏层的神经网络,我们称为浅层神经网络:
相对于浅层网络结构,有两层,三层及以上隐藏层的我们就可以称为深度网络:
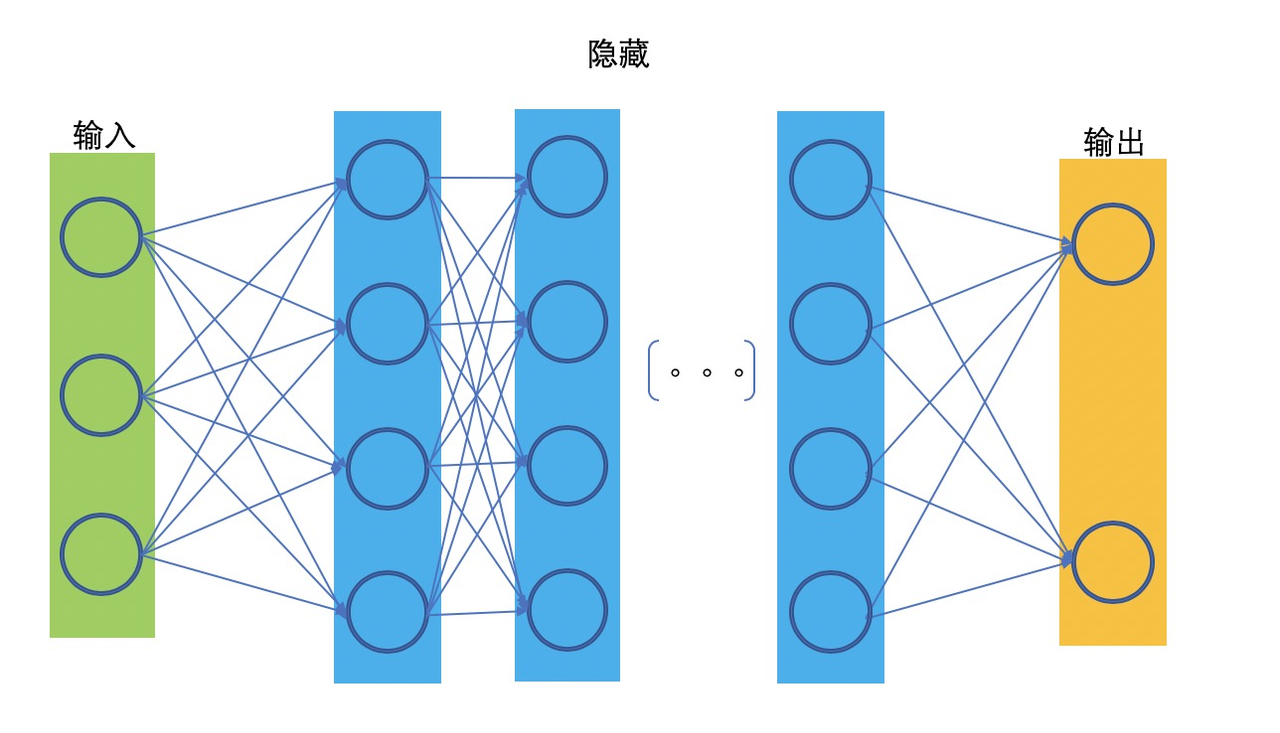
在通常的理解中,一个足够宽的网络,是能够拟合任何函数的。而一个深层网络,则能够用更少的参数来拟合该函数,因为深层的神经元可以获取比浅层神经元更复杂的特征表示。
而根据网络层级间不同的反馈方式,我们又可以将其区分为前馈神经网络、反馈神经网络、双向神经网络以及循环神经网络等:
CNN | 卷积网络
前文中提及的神经网络,不同层间的神经元之间两两皆有关联,隐藏层的神经元会和上一层所有的神经元输出相关。和全连接网络相对应的,是只和上一层部分神经元输出连接的网络,如卷积网络。
卷积网络神经元只和上一层的部分神经元输出是连接的,在直觉上,是因为人的视觉神经元触突只对局部信息敏感,而不是全局所有信息都对同一个触突产生等价作用。
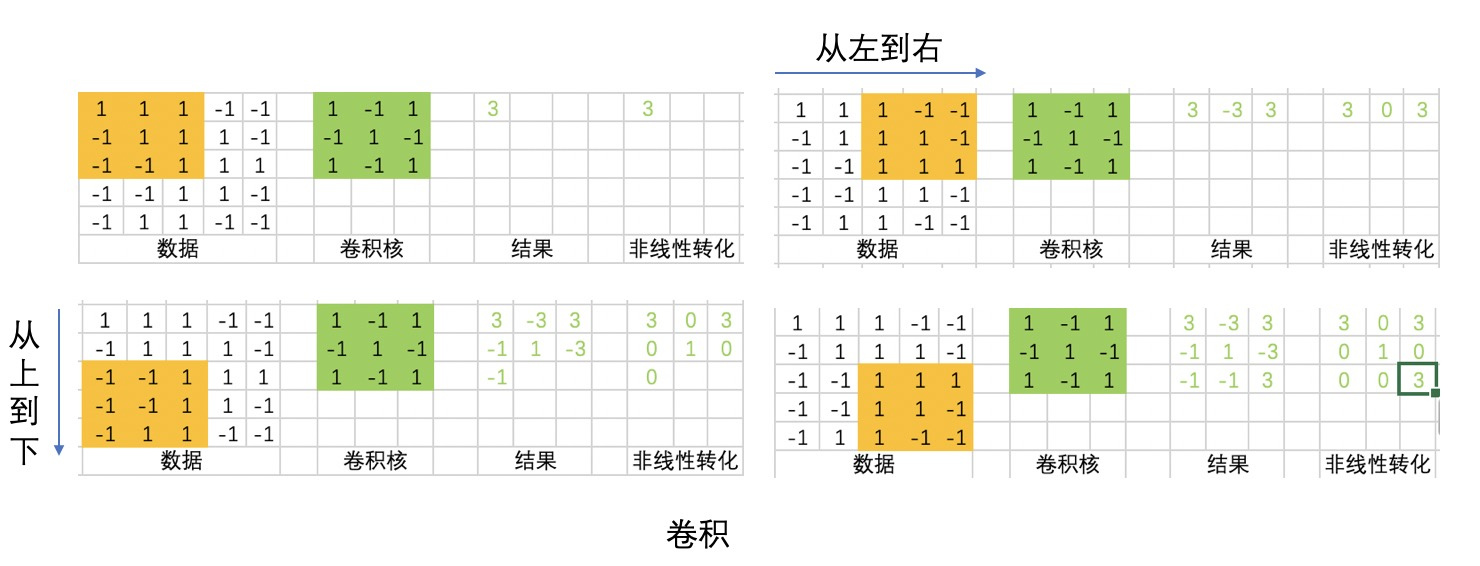
同一个卷积核从左到右,从上到下和输入做乘积,得到了不同强度的输出。从直觉上来理解,卷积核对原始数据的不同数据分布的敏感度是不一样的。如果把卷积核理解为是某种模式, 那么符合这种模式 的数据分布会得到比较强的输出,而不符合这种模式 的输出则得到弱的,甚至是不输出。
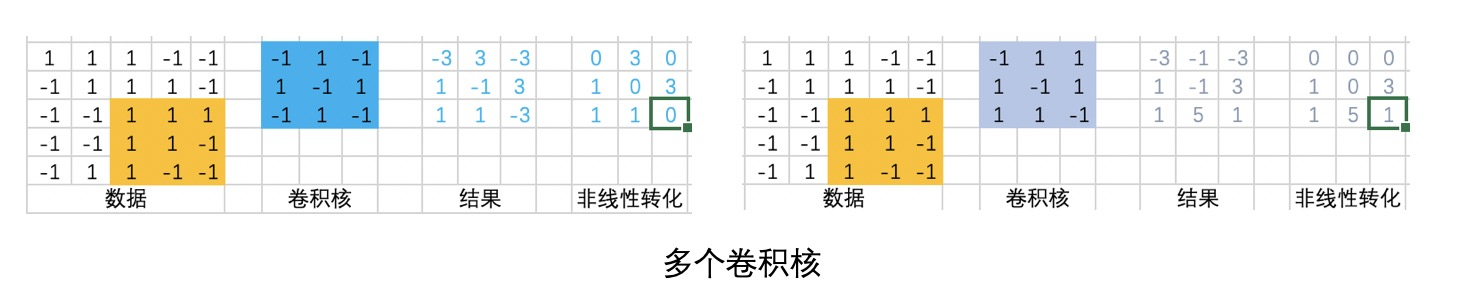
一个卷积核是一个模式提取器,多个卷积核就是多个模式提取器。通过多个特征提取器对原始数据做特征提取转换,就构成了一层卷积。
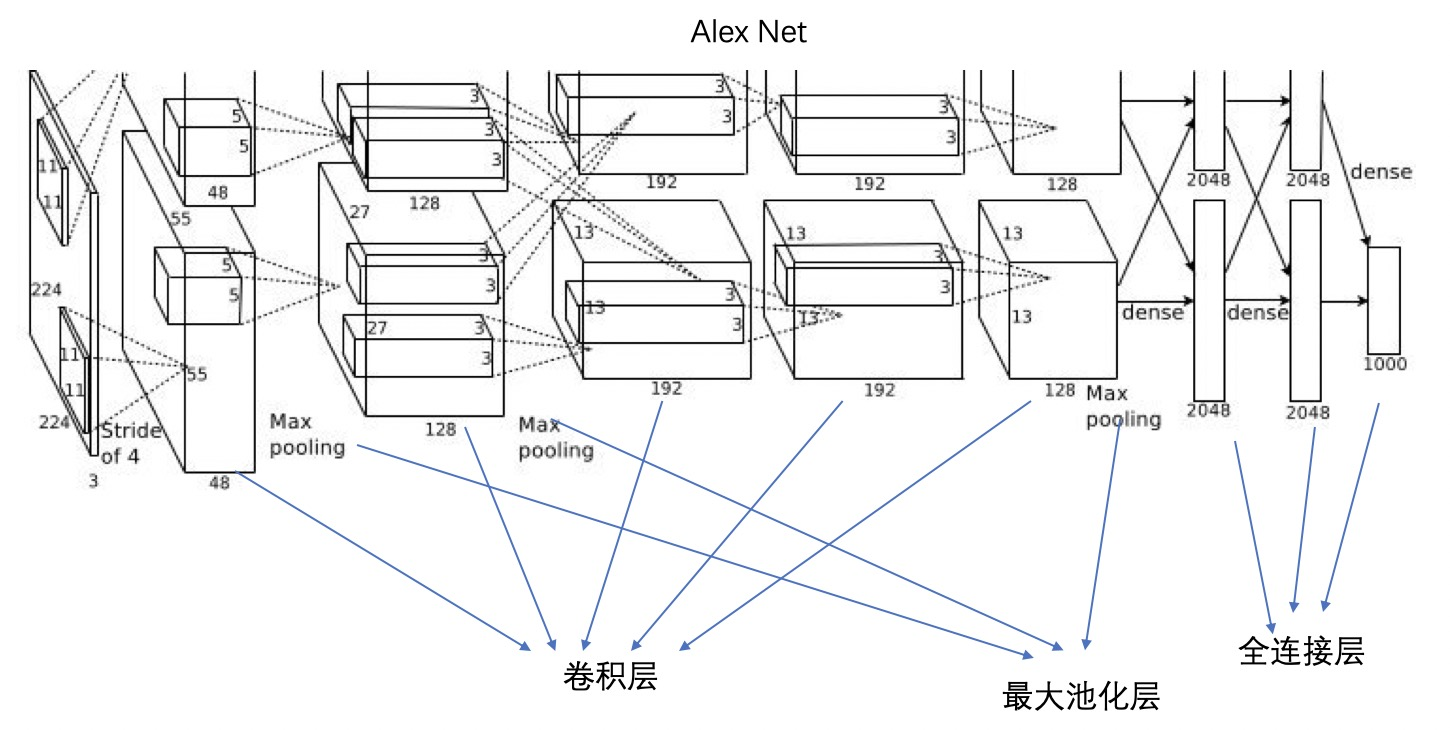
Alex Net, 因为 GPU 内存的原因,Alex 使用了两块 GPU 对模型做了切割,本质上的卷积层是用于特征提取,最大池化层用于提取强特征及减少参数,全连接层则是所有高级特征参与到最后分类决策中去。
RNN | 循环神经网络
CNN 是对空间上特征的提取,RNN 则是对时序上特征的提取。在直觉上,我们理解 RNN 网络是一个可模拟任何函数的一个神经网络(action),加上同时有一份自己的历史存储(memory),action+memory 两者让 RNN 成为了一个图灵机器。
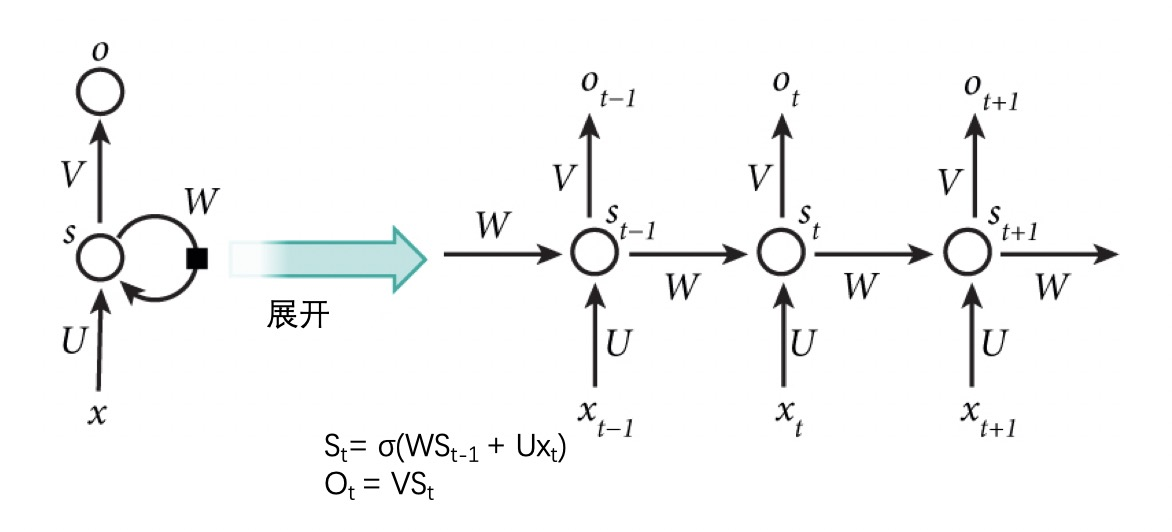
在 RNN 中,$x_1$, $x_2$, $x_3$, $x_t$ 是在时序上不一样的输入,而 $V$,$U$,$W$ 三个矩阵则是共享。同时 RNN 网络中保存了自己的状态 $S$。$S$ 随着输入而改变,不同的输入/不同时刻的输入或多或少影响 RNN 网络的状态 $S$。而 RNN 网络的状态 $S$ 则决定最后的输出。
LSTM | 长短期记忆网络
RNN 的问题是非线性操作 $σ$ 的存在且每一步间通过连乘操作传递,会导致长序列历史信息不能很好的传递到最后,而有了 LSTM 网络。
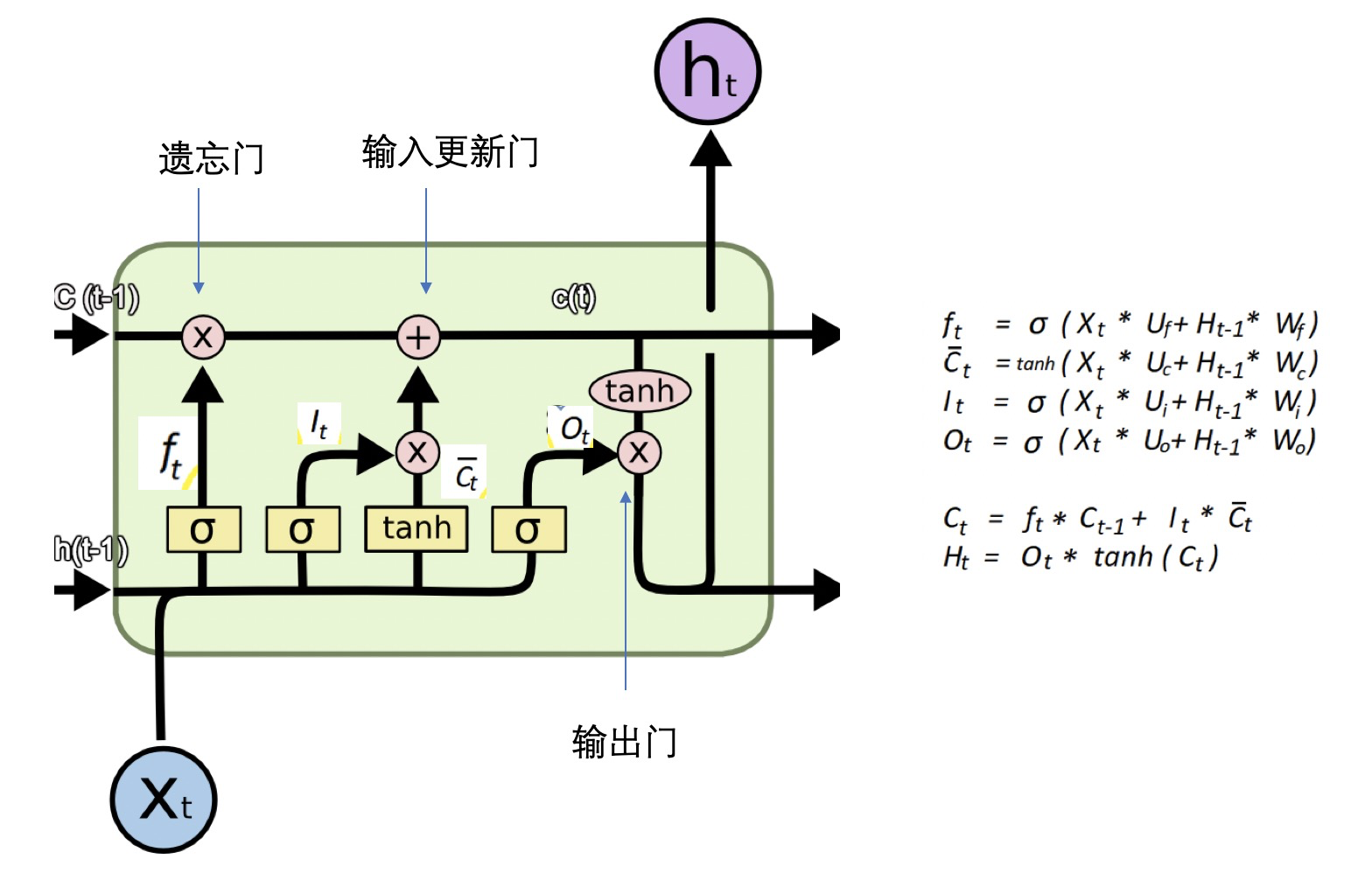
在 LSTM Cell 中,包含了通常意义上的遗忘门(点乘,决定什么要从状态中去除),输入更新门(按位相加,决定什么要添加到状态中去),输出门(点乘,决定状态的输出是什么)。
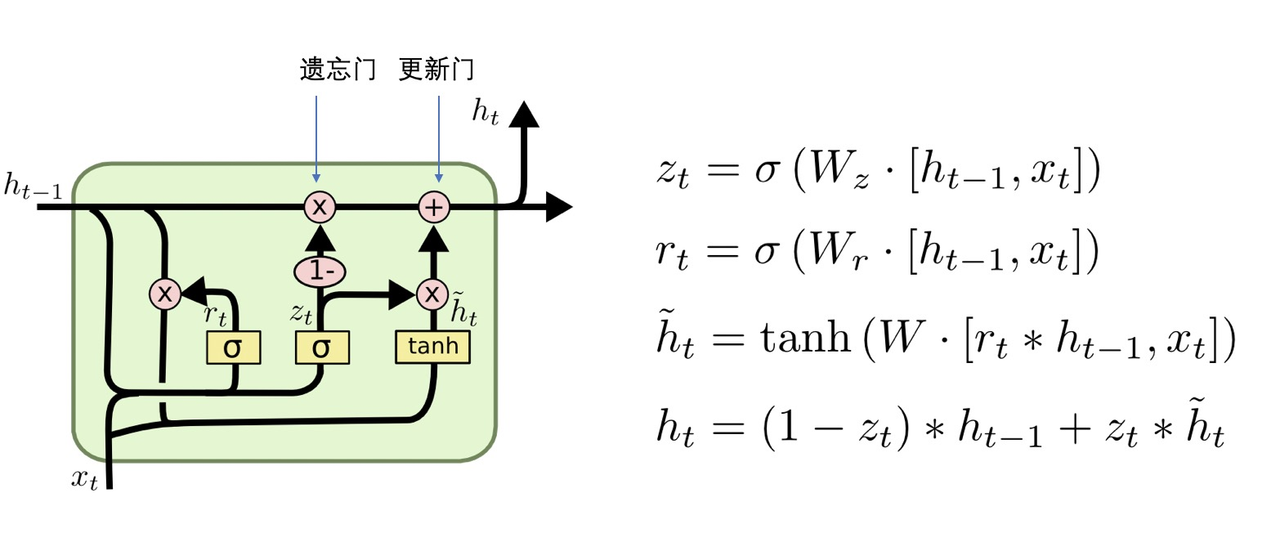
LSTM 本质上是矩阵的运算,后续 LSTM 的变种 GRU 如下:
NLP | 自然语言处理
TextCNN | 文本卷积网络
CNN 在计算机识别领域中应用广泛,其捕捉局部特征的能力非常强,为分析和利用图像数据的研究者提供了极大的帮助。TextCNN 是 2014 年 Kim 在 EMNLP 上提出将 CNN 应用于 NLP 的文本分类任务中。
从直观上理解,TextCNN 通过一维卷积来获取句子中 n-gram 的特征表示。TextCNN 对文本浅层特征的抽取能力很强,在短文本领域如搜索、对话领域专注于意图分类时效果很好,应用广泛,且速度快,一般是首选;对长文本领域,TextCNN 主要靠 filter 窗口抽取特征,在长距离建模方面能力受限,且对语序不敏感。
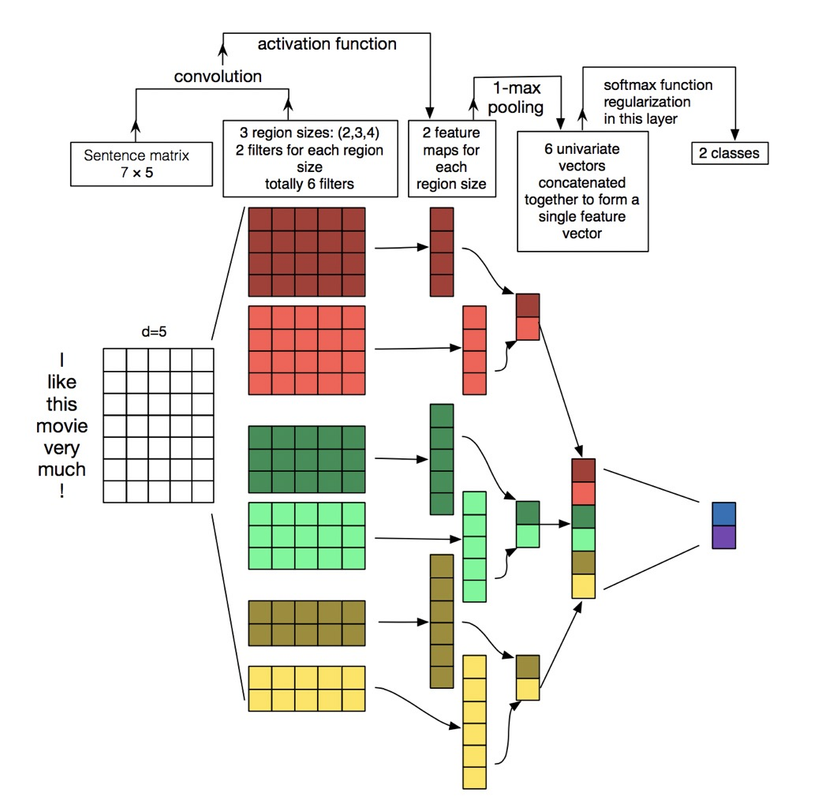
文本卷积与图像卷积的不同之处在于只在文本序列的一个方向做卷积。对句子单词每个可能的窗口做卷积操作得到特征图(feature map)。
$$ \mathrm{c}=\left[\mathrm{c}{1}, \mathrm{c}{2}, \ldots, \mathrm{c}_{\mathrm{n}-\mathrm{h}+1}\right] $$
其中 $\mathrm{c} \in \mathrm{R}^{n-h+1}$,对 feature map 做最大池化(max-pooling)操作,取中最大值 max{c} 作为 filter 提取出的 feature。通过选择每个 feature map 的最大值,可捕获其最重要的特征。每个 filter 卷积核产生一个 feature,一个 TextCNN 网络包括很多不同窗口大小的卷积核,如常用的 filter size ∈ {3,4,5} 每个 filter 的 feature maps=100。
Transformer
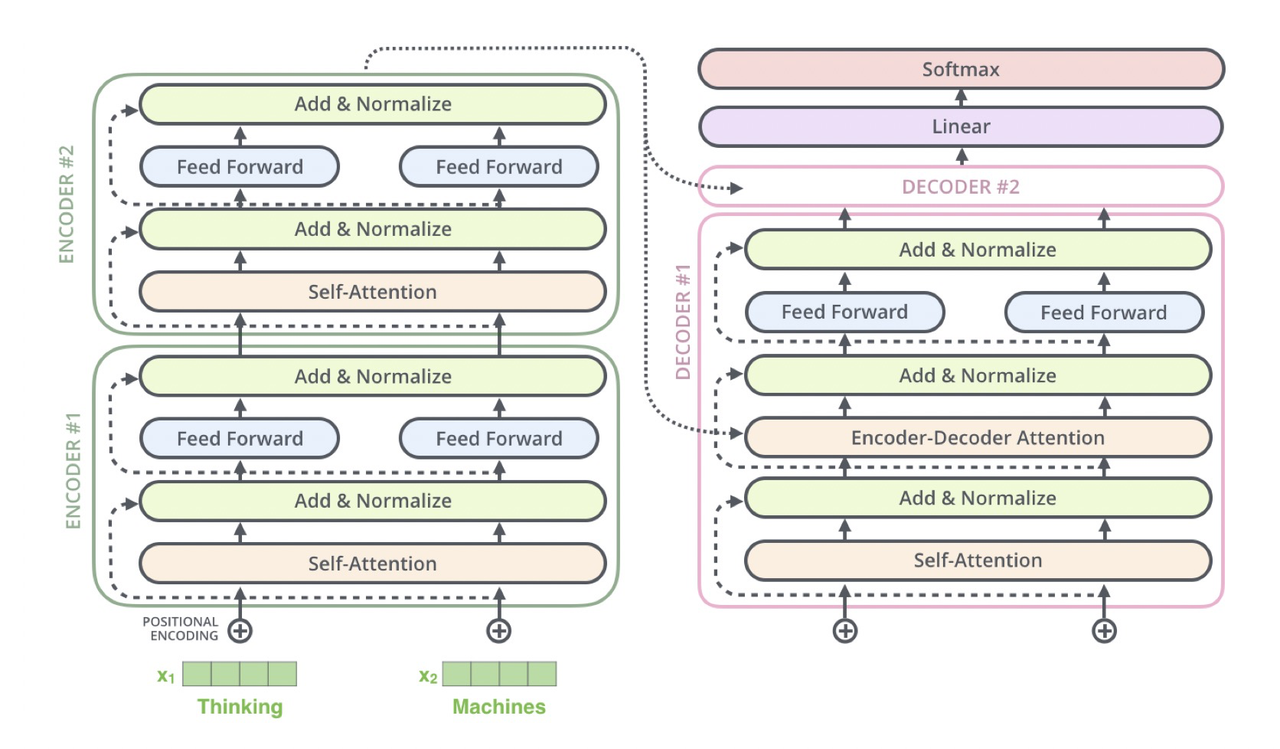
Attention 此前就被用于众多 NLP 的任务,用于定位关键 token 或者特征,比如在文本分类的最后加一层 Attention 来提高性能。Transformer 起源自注意力机制(Attention),完全抛弃了传统的 RNN,整个网络结构完全是由 Attention 机制组成。Transformer 可以通过堆叠 Transformer Layer 进行搭建,作者的实验是通过搭建编码器和解码器各 6 层,总共 12 层的 Encoder-Decoder,并在机器翻译中取得了 BLEU 值的新高。
以 N=2 示例,Encoder 阶段:输入“Thinking Machines”,对应词向量,叠加位置向量 Positional Encoding,对每个位置做 Self-Attention 得到; Add&Norm 分两步,residual connection 即,layer Normalization 得到新的,对每个位置分别做 feed forward 全连接和 Add&Norm,得到一个 Encoder Layer 的输出,重复堆叠 2 次,最后将 Encoder Layer 输出到 Decoder 的 Encoder-Decoder Layer 层。
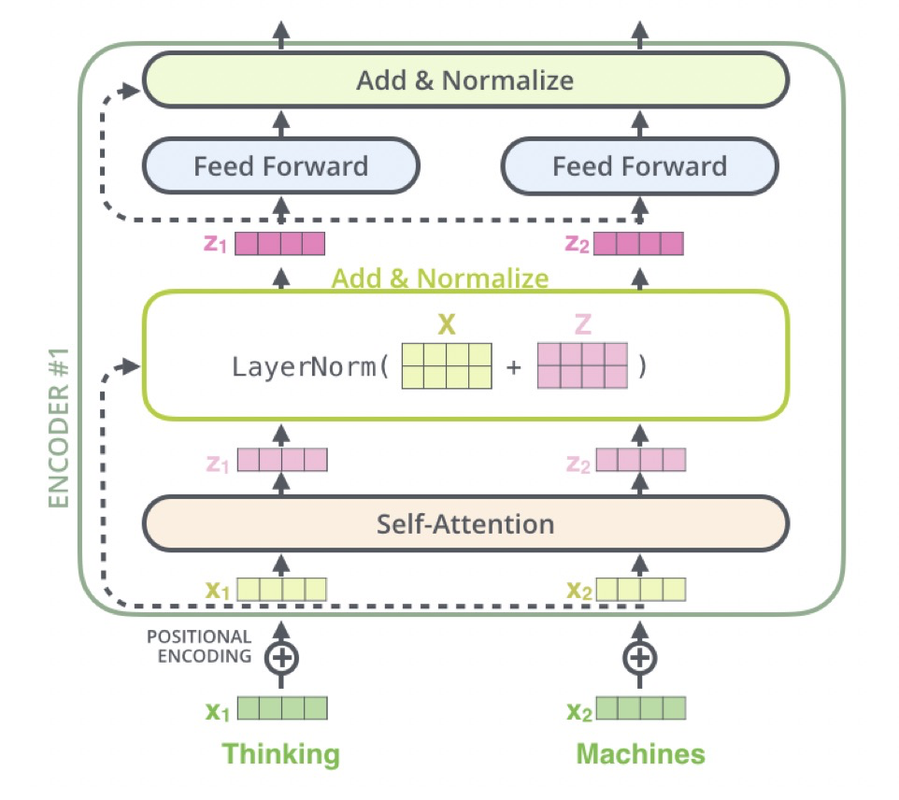
Decoder 阶段:先是对 Decoder 的输入做 Masked Self-Attention Layer,然后将 Encoder 阶段的输出与 Decoder 第一级的输出做 Encoder-Decoder Attention,最后接 FFN 全连接,堆叠 2 个 Decoder,最后接全连接+Softmax 输出当前位置概率最大的的词。
Transformer 的优点:
-
并行计算, 提高训练速度。这是相比 LSTM 很大的突破,LSTM 在训练的时候, 当前步的计算要依赖于上一步的隐状态, 这是一个连续过程, 每次计算都需要等之前的计算完成才能展开,限制模型并行能力。而 Transformer 不用 LSTM 结构, Attention 机制的每一步计算只是依赖上一层的输出,并不依赖上一词的信息,因而词与词之间是可以并行的,从而训练时可以并行计算, 提高训练速度。
-
一步到位的全局联系捕捉。顺序计算的过程中信息会丢失,尽管 LSTM 等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM 依旧无能为力。Transformer 使用了 Attention 机制,从而将序列中的任意两个位置之间的距离是缩小为 1,这对解决 NLP 中棘手的长期依赖问题是非常有效的。
总结对比 CNN、RNN 和 Self-Attention:
-
CNN:只能看到局部领域,适合图像,因为在图像上抽象更高层信息仅仅需要下一层特征的局部区域,文本的话强在抽取局部特征,因而更适合短文本。
-
RNN:理论上能看到所有历史,适合文本,但是存在梯度消失问题。
-
Self-Attention:相比 RNN 不存在梯度消失问题。对比 CNN 更加适合长文本,因为能够看到更远距离的信息,CNN 叠高多层之后可以看到很远的地方,但是 CNN 本来需要很多层才能完成的抽象,Self-Attention 在很底层就可以做到,这无疑是非常巨大的优势。
BERT
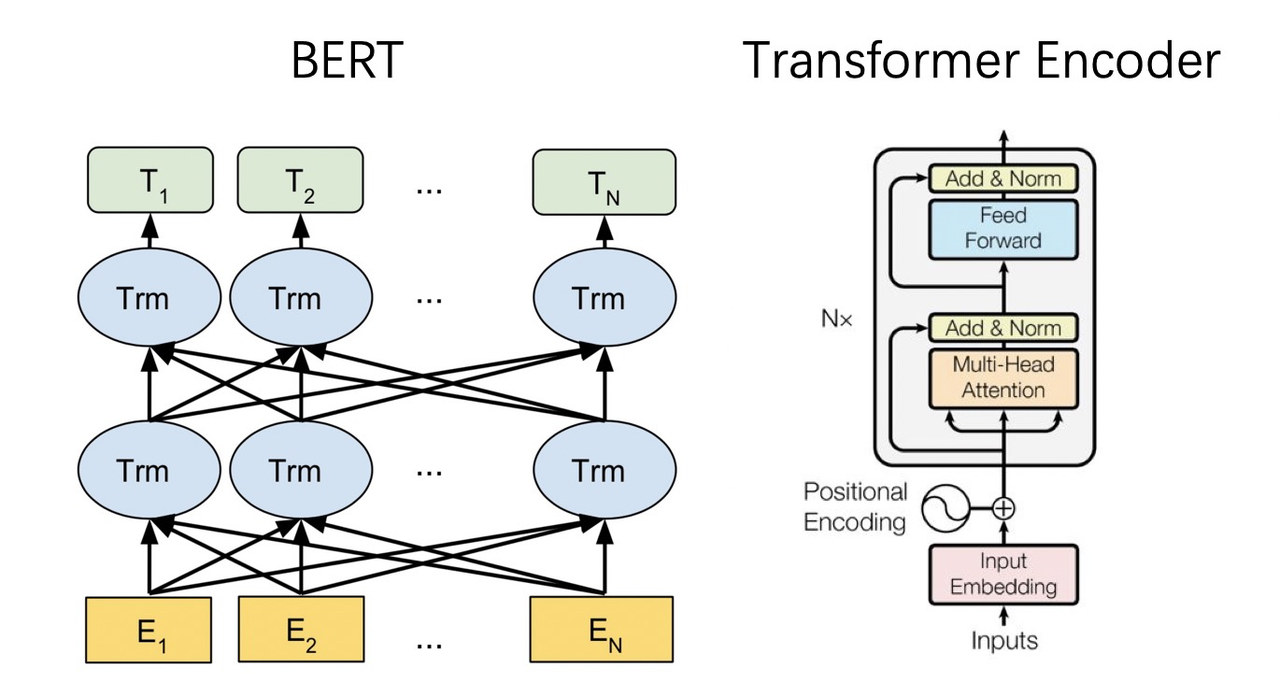
BERT (Bidirectional Encoder Representations from Transformers)本质来讲是 NLP 领域最底层的语言模型,通过海量语料预训练,得到序列当前最全面的局部和全局特征表示。
BERT 网络结构如下所示,BERT 与 Transformer 的 Encoder 网络结构完全相同。假设 Embedding 向量的维度是,输入序列包含 n 个 token,则 BERT 模型一个 layer 的输入是一个的矩阵,而它的输出也同样是一个的矩阵,所以这样 N 层 BERT layer 就可以很方便的首尾串联起来。BERT 的 large model 使用了 N=24 层这样的 Transformer block。
BERT 的主要贡献有以下几个方面
-
预训练的有效性:这方面来说 BERT 改变了游戏规则,是因为相比设计复杂巧妙的网络结构,在海量无监督数据上预训练得到的 BERT 语言表示+少量训练数据微调的简单网络模型的实验结果取得了很大的优势。
-
网络深度:基于 DNN 语言模型(NNLM,CBOW 等)获取词向量的表示已经在 NLP 领域获得很大成功,而 BERT 预训练网络基于 Transformer 的 Encoder,可以做的很深。
-
双向语言模型:在 BERT 之前,ELMo 和 GPT 的主要局限在于标准语言模型是单向的,GPT 使用 Transformer 的 Decoder 结构,只考虑了上文的信息。ELMo 从左往右的语言模型和从右往左的语言模型其实是独立开来训练的,共享 embedding,将两个方向的 LSTM 拼接并不能真正表示上下文,其本质仍是单向的,且多层 LSTM 难训练。
-
目标函数:对比语言模型任务只做预测下一个位置的单词,想要训练包含更多信息的语言模型,就需要让语言模型完成更复杂的任务,BERT 主要完成完形填空和句对预测的任务,即两个 loss:一个是 Masked Language Model,另一个是 Next Sentence Prediction。
Nav | 关联导航
About | 关于
Contributing
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Acknowledgements
-
Awesome-Lists: 📚 Guide to Galaxy, curated, worthy and up-to-date links/reading list for ITCS-Coding/Algorithm/SoftwareArchitecture/AI. 💫 ITCS-编程/算法/软件架构/人工智能等领域的文章/书籍/资料/项目链接精选。
-
Awesome-CS-Books: :books: Awesome CS Books/Series(.pdf by git lfs) Warehouse for Geeks, ProgrammingLanguage, SoftwareEngineering, Web, AI, ServerSideApplication, Infrastructure, FE etc. :dizzy: 优秀计算机科学与技术领域相关的书籍归档。
Copyright & More | 延伸阅读
笔者所有文章遵循知识共享 署名 - 非商业性使用 - 禁止演绎 4.0 国际许可协议,欢迎转载,尊重版权。您还可以前往 NGTE Books 主页浏览包含知识体系、编程语言、软件工程、模式与架构、Web 与大前端、服务端开发实践与工程架构、分布式基础架构、人工智能与深度学习、产品运营与创业等多类目的书籍列表:
