
69-BERT 预训练
BERT 预训练
1.目录:
2.BERT:
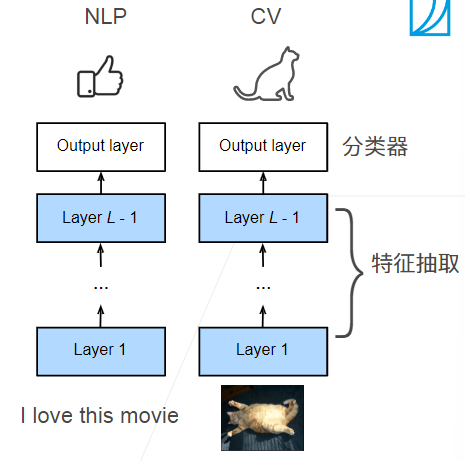
2.1 NLP 里的迁移学习
-
使用预训练好的模型来抽取词,句子的特征
- 例如 word2vec 或语言模型
-
不更新预训练好的模型
-
需要构建新的网络来抓取任务需要的信息
- Word2vec 忽略了时序信息
- 语言模型只看了一个方向
2.2 BERT 的动机
- 基于微调的 NLP 模型
- 预训练的模型抽取了足够多的信息
- 新的任务只需要增加一个简单地输出层
2.3 BERT 架构
-
只有编码器的 Transformer
-
两个版本:
- Base:#blocks=12,hidden size=768,#heads=12,#parameters=110M
- Large:#blocks=24,hidden size=1024,#heads=16,#paramerter=340M
-
在大规模数据上训练>3B 词
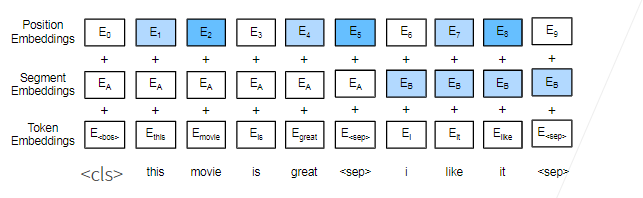
2.4 对输入的修改
- 每个样本是一个句子对
- 加入额外的片段嵌入
- 位置编码可学习
2.5 预训练任务
2.5.1 带掩码的语言模型
- Transformer 的编码器是双向的,标准语言模型要求单向
- 带掩码的语言模型每次随机(15%概率)将一些词元换成
-
2.5.2 下一个句子预测
-
预测一个句子对中两个句子是不是相邻
-
训练样本中:
- 50%概率选择相邻句子对:
this movie is great i like it - 50%概率选择随机句子对:
this movie is great hello world
- 50%概率选择相邻句子对:
-
将
对应的输出放到一个全连接层来预测
2.6 总结
- BERT 针对微调设计
- 基于 Transformer 的编码器做了如下修改
- 模型更大,训练数据更多
- 输入句子对,片段嵌入,可学习的位置编码
- 训练时使用两个任务:
- 带掩码的语言模型
- 下一个句子预测
3.代码实现
3.1 获取输入:
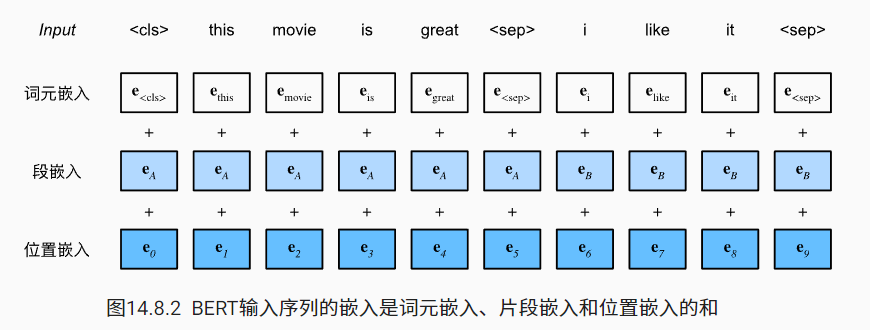
在自然语言处理中,有些任务(如情感分析)以单个文本作为输入,而有些任务(如自然语言推断)以一对文本序列作为输入。BERT 输入序列明确地表示单个文本和文本对。当输入为单个文本时,BERT 输入序列是特殊类别词元“
为了区分文本对,根据输入序列学到的片段嵌入 eA 和 eB 分别被添加到第一序列和第二序列的词元嵌入中。对于单文本输入,仅使用 eA。
下面的get_tokens_and_segments将一个句子或两个句子作为输入,然后返回 BERT 输入序列的标记及其相应的片段索引。
#@save
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
BERT 选择 Transformer 编码器作为其双向架构。在 Transformer 编码器中常见是,位置嵌入被加入到输入序列的每个位置。然而,与原始的 Transformer 编码器不同,BERT 使用可学习的位置嵌入。总之, 下图表明 BERT 输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的和。
3.2 BERT 实现
下面的BERTEncoder类类似于 10.7 节中实现的TransformerEncoder类。与TransformerEncoder不同,BERTEncoder使用片段嵌入和可学习的位置嵌入。
#@save
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
假设词表大小为 10000,为了演示BERTEncoder的前向推断,让我们创建一个实例并初始化它的参数。
vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000, 768, 1024, 4
norm_shape, ffn_num_input, num_layers, dropout = [768], 768, 2, 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout)
我们将tokens定义为长度为 8 的 2 个输入序列,其中每个词元是词表的索引。使用输入tokens的BERTEncoder的前向推断返回编码结果,其中每个词元由向量表示,其长度由超参数num_hiddens定义。此超参数通常称为 Transformer 编码器的隐藏大小(隐藏单元数)
tokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
encoded_X.shape
3.3 预训练任务
3.3.1 遮掩语言模型
我们实现了下面的MaskLM类来预测 BERT 预训练的掩蔽语言模型任务中的掩蔽标记。预测使用单隐藏层的多层感知机(self.mlp)。在前向推断中,它需要两个输入:BERTEncoder的编码结果和用于预测的词元位置。输出是这些位置的预测结果。
#@save
class MaskLM(nn.Module):
"""BERT的掩蔽语言模型任务"""
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
# 假设batch_size=2,num_pred_positions=3
# 那么batch_idx是np.array([0,0,0,1,1])
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat
为了演示MaskLM的前向推断,我们创建了其实例mlm并对其进行了初始化。回想一下,来自BERTEncoder的正向推断encoded_X表示 2 个 BERT 输入序列。我们将mlm_positions定义为在encoded_X的任一输入序列中预测的 3 个指示。mlm的前向推断返回encoded_X的所有掩蔽位置mlm_positions处的预测结果mlm_Y_hat。对于每个预测,结果的大小等于词表的大小。
mlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = torch.tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(encoded_X, mlm_positions)
mlm_Y_hat.shape
通过掩码下的预测词元mlm_Y的真实标签mlm_Y_hat,我们可以计算在 BERT 预训练中的遮蔽语言模型任务的交叉熵损失。
mlm_Y = torch.tensor([[7, 8, 9], [10, 20, 30]])
loss = nn.CrossEntropyLoss(reduction='none')
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))
mlm_l.shape
3.3.2 下一句预测
下面的NextSentencePred类使用单隐藏层的多层感知机来预测第二个句子是否是 BERT 输入序列中第一个句子的下一个句子。由于 Transformer 编码器中的自注意力,特殊词元“self.output)以X作为输入,其中X是多层感知机隐藏层的输出,而 MLP 隐藏层的输入是编码后的“
#@save
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
我们可以看到,NextSentencePred实例的前向推断返回每个 BERT 输入序列的二分类预测。
encoded_X = torch.flatten(encoded_X, start_dim=1)
# NSP的输入形状:(batchsize,num_hiddens)
nsp = NextSentencePred(encoded_X.shape[-1])
nsp_Y_hat = nsp(encoded_X)
nsp_Y_hat.shape
3.4 整合代码
在预训练 BERT 时,最终的损失函数是掩蔽语言模型损失函数和下一句预测损失函数的线性组合。现在我们可以通过实例化三个类BERTEncoder、MaskLM和NextSentencePred来定义BERTModel类。前向推断返回编码后的 BERT 表示encoded_X、掩蔽语言模型预测mlm_Y_hat和下一句预测nsp_Y_hat。
#@save
class BERTModel(nn.Module):
"""BERT模型"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
hid_in_features=768, mlm_in_features=768,
nsp_in_features=768):
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, num_layers,
dropout, max_len=max_len, key_size=key_size,
query_size=query_size, value_size=value_size)
self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),
nn.Tanh())
self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)
self.nsp = NextSentencePred(nsp_in_features)
def forward(self, tokens, segments, valid_lens=None,
pred_positions=None):
encoded_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
else:
mlm_Y_hat = None
# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat
3.5 小结
- word2vec 和 GloVe 等词嵌入模型与上下文无关。它们将相同的预训练向量赋给同一个词,而不考虑词的上下文(如果有的话)。它们很难处理好自然语言中的一词多义或复杂语义。
- 对于上下文敏感的词表示,如 ELMo 和 GPT,词的表示依赖于它们的上下文。
- ELMo 对上下文进行双向编码,但使用特定于任务的架构(然而,为每个自然语言处理任务设计一个特定的体系架构实际上并不容易);而 GPT 是任务无关的,但是从左到右编码上下文。
- BERT 结合了这两个方面的优点:它对上下文进行双向编码,并且需要对大量自然语言处理任务进行最小的架构更改。
- BERT 输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的和。
- 预训练包括两个任务:掩蔽语言模型和下一句预测。前者能够编码双向上下文来表示单词,而后者则显式地建模文本对之间的逻辑关系。
Q&A:
Q1:BERT 是不是很少用在 CV 上?
transformer 架构这几年在大量的用于 CV 上
Q2:展示一下 10W batch 训练结果?
微调时会用到
Q3:使用 BERT large 时显存不足,有什么方法吗?
单机多卡,模型并行,或改用小模型