
采集与调度
采集与调度
基于时间片的采集
业界主流的 Agent 对于每个配置会分配独立的线程/go runtime 来进行数据读取,但是单线程足以完成所有配置的事件处理以及数据读取,数据读取的瓶颈并不在于计算而是磁盘,对于正常的服务器,每秒基本不可能产生超过 100MB 的日志,而 logtail 数据读取线程可完成每秒 200MB 以上的数据读取(SSD 速率可以更高)。单线程的另一个优势是可以使事件处理和数据读取在无锁环境下运行,相对多线程处理性价比较高。
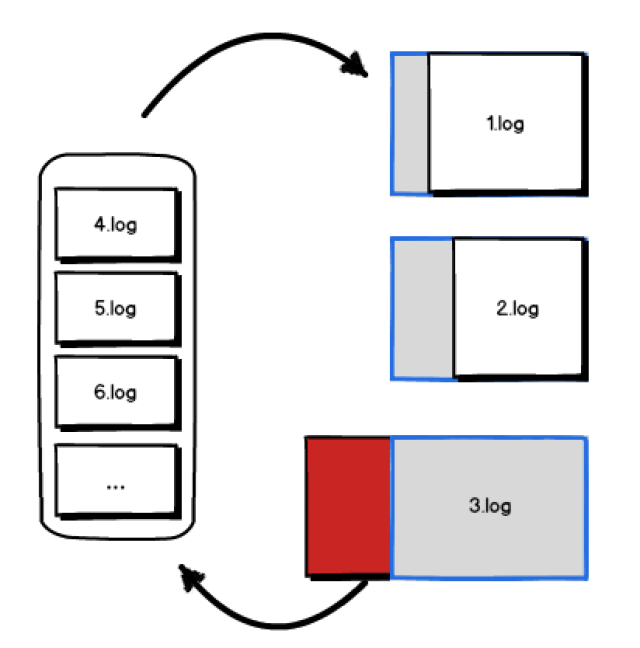
多级高低水位反馈队列
基于时间片的采集调度保证了各个配置的日志在数据读取时得到公平的调度,满足了多租户隔离中基本的公平性,但对于隔离性并未起到帮助作用。例如当部分采集配置因处理复杂或网络异常等原因阻塞时,阻塞配置依然会进行处理,最终会导致队列到达上限而阻塞数据读取线程,影响其他正常配置。
这里的多级指的是处理过程的多级,即各个处理过程间会有一个这样的队列且相邻队列互相关联
例如在 Logtail 的数据读取、处理、发送流程中需要在读取->解析以及解析->发送间各自设置一个这样的队列
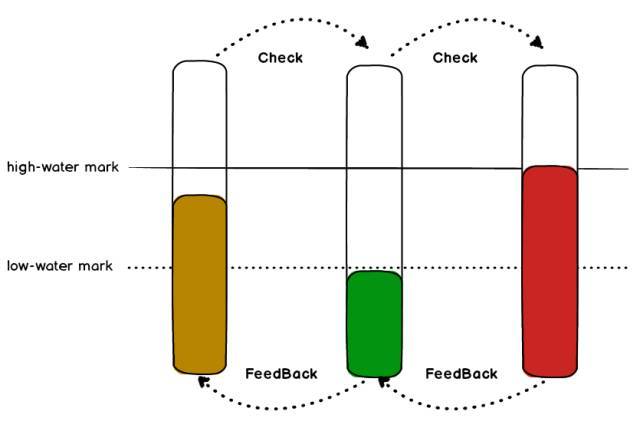
高低水位:
单一队列中设置了高低两个水位
当队列增长到高水位时,停止非紧急数据写入(例如进程重启时、数据拆分等特殊情况允许写入)
当队列从高水位消费到低水位时,再次允许写入
反馈:
反馈分为同步和异步两种
在准备读取当前队列数据时会同步检查下一级队列状态,当下级队列到达高水位时跳过此队列
当前队列从高水位消费到低水位时,异步通知关联的前一级队列
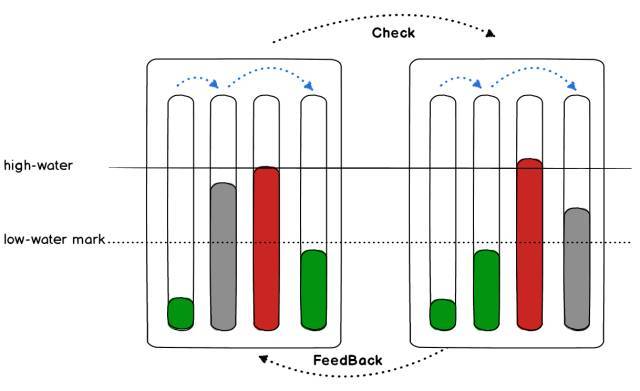
由于多个配置存在,所以我们会为每个配置创建一组队列,每个队列使用指针数组实现,每一级中所有配置队列公用一个锁,对于性能以及内存消耗较为友好。Logtail 中的多级高低水位反馈队列结构如下:
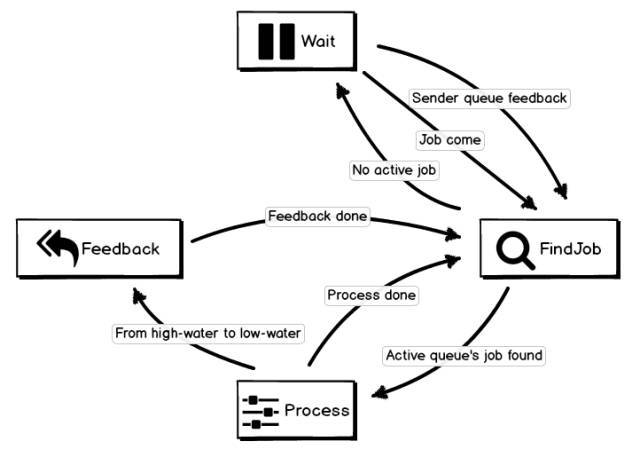
我们以日志解析这个步骤的工作方式来观察多级反馈队列的行为:
初始状态下解析线程处理 Wait 状态,当有数据到达或下一级发送线程某一配置的队列从高水位消费到低水位时,进入 FindJob 状态;
FindJob 会从上一次处理的队列位置顺序查找当前有数据且下一级队列可以写入的队列,若查找到则进行 Process 状态,否则进行 Wait 状态;
Process 对于当前 job 解析完后,判断该 job 所属队列是否从高水位到达低水位,若是则进入 Feedback 状态,否则回到 FindJob 查找下一个有效 job;
Feedback 状态会向关联的上一级队列发送信号,参数携带当前队列 ID,用以触发上一级流程运行,信号发送完毕后进入 FindJob 状态;
基于多级高低水位反馈队列的处理过程中,当遇到下一级阻塞的队列时直接跳过,防止因阻塞 Job 的处理导致线程阻塞,具有较高的隔离性;FindJob 会记录上一次查找的队列 ID,下次查找时会从该 ID 之后的队列开始,保证了各个配置间调度的公平性。
流控以及阻塞处理
上一节的多级高低水位反馈队列解决了多配置间的隔离性和公平性问题,但对于可控性以及可靠性方面还存在一些问题。例如:
无法精确控制每个配置的的采集流量,只能通过删除采集配置停止采集
如果某一配置完全阻塞时,当该配置关联日志文件轮转,恢复阻塞时将丢失轮转前的数据
这里主要包括三个部分:事件处理、数据读取逻辑以及数据发送控制:
事件处理与数据读取无关,即使读取关联的队列满也照常处理,这里的处理主要是更新文件 meta、将轮转文件放入轮转队列,具体可查看上一篇文章;此种方式可保证即使在配置阻塞/暂停的情况下依然保证及时文件轮转也不会丢失数据;
当配置关联的解析队列满时,如果将事件重新放回队列尾,则会造成较多的无效调度,使 CPU 空转。因此我们在遇到解析队列满时,将该事件放到一个专门的 blocked 队列中,当解析队列异步反馈时重新将 blocked 队列中的数据放回事件队列;
Sender 中每个配置的队列关联一个 SenderInfo,SenderInfo 中记录该配置当前网络是否正常、Quota 是否正常以及最大允许的发送速率。每次 Sender 会根据 SenderInfo 中的状从队列中取数据,这里包括:网络失败重试、Quota 超限重试、状态更新、流控等逻辑