
Data Parallelism
Data Parallelism
在给定数据集的情况下,数据并行性是指跨数据集的元素组在同一功能的多台机器或线程上同时执行。数据并行性也可以视为 SIMD(“单指令,多个数据”)执行的子集,这是 Flynn 分类法中的一类并行执行。相比之下,人们可以将顺序计算视为“对数据集中的所有元素都执行操作 A”,该数据集的大小可以达到 TB 或 PB。以并行方式进行此顺序计算的挑战包括如何以一种简单且正确的方式抽象不同类型的计算,如何将数据分发到成千上万的计算机或群集以及如何安排任务和处理故障。
MapReduce(Dean&Ghemawat,2008)是 Google 提出的一种编程模型,最初可以满足他们对网络搜索服务的大规模索引的需求。它提供了一个简单的用户程序界面:Map 和 Reduce 功能,并自动处理并行化和分发;底层的执行系统可以提供容错能力和调度功能。
MapReduce 模型简单而强大,并且很快在开发人员中变得非常流行。但是,当开发人员开始编写实际应用程序时,他们通常最终会编写许多样板代码并将这些阶段链接在一起。而且,MapReduce 的流水线迫使他们编写附加的协调代码,即开发风格从简单的逻辑计算抽象向低级的协调管理倒退。
MapReduce 在每个阶段之后将所有数据写入磁盘,这会导致严重的延迟。程序员需要针对目标性能进行手动优化,这又需要他们了解底层的执行模型。整个过程很快变得麻烦。FlumeJava 库旨在通过抽象化数据表示所涉及的复杂性并隐式地处理优化来为开发数据并行管道提供支持。它推迟 Evaluation,从并行集合构造执行计划,优化计划,然后执行基础的 MR 原语。优化的执行与手工优化的流水线相当,因此,不需要直接编写原始 MR 程序。
在 MapReduce 之后,Microsoft 提出了其对应的数据并行性模型 Dryad。程序员需要做的是描述这个 DAG,并让 Dryad 执行引擎构造执行计划并管理调度和优化。Dryad 相对于 MapReduce 的优点之一是 Dryad 顶点可以处理任意数量的输入和输出,而 MR 仅支持每个顶点一个输入和一个输出。除了计算的灵活性外,Dryad 还支持不同类型的通信通道:文件,TCP 管道和共享内存 FIFO。编程模型不如 MapReduce 优雅,因为程序员并不打算直接与之交互。而是希望他们使用高级编程接口 DryadLinq,该接口更具表现力,并且更好地嵌入 .NET 框架中。我们稍后将在专门讨论 Dryad 的部分中看到一些示例。
Dryad 将计算表示为非循环数据流,这对于某些复杂的应用(例如,迭代机器学习算法。Spark 是一个使用函数式编程和流水线提供此类支持的框架。Spark 在很大程度上受到 MapReduce 模型的启发,并建立在使用 DAG 和 DryadLinq 中的惰性评估背后的思想的基础上。无需像 MapReduce 那样为每个作业将数据写入磁盘,Spark 可以跨作业缓存结果。Spark 通过称为弹性分布集(RDD)的专用不变数据结构将计算数据显式缓存在内存中,并在多个并行操作中重用同一数据集。Spark 通过重新使用丢失的 RDD 的沿袭信息,在 RDD 的基础上实现容错。与使用分布式共享内存系统中的检查点实现的容错能力相比,这导致了更少的开销。此外,Spark 是构建许多非常不同的系统的基础框架,例如 Spark SQL 和 DataFrames,GraphX,Streaming Spark,这使得在同一应用程序中轻松混合和匹配这些系统的使用变得容易。这些功能使 Spark 最适合迭代作业和交互式分析,还有助于提供更好的性能。
MapReduce
在此模型中,可并行化的计算被抽象为 map 和 reduce 函数。该计算接受一组键/值对作为输入,并生成一组键/值对作为输出。该过程涉及两个阶段:
-
Map:用户编写的 Map 接受一组键/值对(“记录”)作为输入,对每个记录应用 map 操作,并计算一组中间键/值对作为输出。
-
Reduce:还由用户编写的 Reduce 接受中间键和与该键关联的一组值,对其进行操作,并产生零个或一个输出值。
MapReduce 库提供的 Map 和 Reduce 之间还有一个 Shuffle 阶段,该阶段将同一键的所有中间值组合在一起,并将它们传递给 Reduce 函数。关于执行模型的部分将对此进行更多讨论。从概念上讲,map 和 reduce 函数具有关联的类型:
$$ \begin{array}{c}\operatorname{map}(k 1, v 1) \rightarrow \operatorname{list}(k 2, v 2) \ \text {reduce}(k 2, \text {list}(v 2)) \rightarrow \operatorname{list}(v 2)\end{array} $$
输入键和值是从与输出键和值不同的域中提取的。中间键和值与输出键和值来自同一域。例如,我们可以考虑对大量文档中每个单词出现的次数进行计数的问题。可以将其建模为一个 Map 函数,该 Map 函数发出一个单词加上其计数 1 和一个 reduce 函数,该函数将针对同一单词发出的所有计数加在一起。
map(String key, String value):
// key: document name
// value: document contents
for each word in value:
EmitIntermediate(word, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each value in values:
result += ParseInt(value);
Emit(AsString(result));
在执行期间,MapReduce 库分配一个主节点来管理数据分区和调度。其他节点可以充当工作节点来按需运行 Map 或者 Reduce 操作。稍后将讨论执行模型的更多细节。在这里,值得一提的是,将映射阶段输出的中间结果写入磁盘,然后 reduce 操作从磁盘读取其输入。这对于容错至关重要。
Fault Tolerance
MapReduce 可在成百上千个不可靠的商用机器上运行,因此该库必须提供容错能力。该库假定主节点不会发生故障,并且它监视工作程序故障。如果在超时时未收到任何来自工人的状态更新,则主服务器会将其标记为失败。然后,主机可以根据任务类型和状态将关联的任务安排给其他工作节点。map 和 reduce 任务输出的提交是原子的,正在进行的任务将数据写入私有临时文件,然后一旦任务成功,它将与主服务器协商并重命名文件以完成任务。如果发生故障,工作节点将丢弃这些临时文件。这保证了,如果计算是确定性的,则分布式实现应产生与无故障顺序执行相同的输出。
Limitations
许多分析工作负载(例如 K 均值,逻辑回归,PageRank 之类的图形处理应用程序以及使用并行广度优先搜索的最短路径)需要多个阶段的 MapReduce 作业。在像 Hadoop 这样的常规 MapReduce 框架中,这要求开发人员手动处理驱动程序代码中的迭代。在每次迭代时,每个阶段 T 的结果都会写入 HDFS,并在阶段 T + 1 再次加载回去,从而导致性能瓶颈。这样做的原因是浪费网络带宽,CPU 资源,并且本质上是固有的磁盘 I/O 操作缓慢。为了解决 MapReduce 上的迭代工作负载中的此类挑战,诸如 Haloop,Twister 和 iMapReduce 之类的框架采用了特殊的技术,例如在迭代之间缓存数据并在迭代期间使映射器和化简器保持活动状态。
FlumeJava
引入 FlumeJava 是为了使其易于开发,测试和运行有效的数据并行管道。FlumeJava 将每个数据集表示为一个对象,并通过在这些对象上应用方法来调用转换。它从 MapReduce 作业流水线构造了一个有效的内部执行计划,使用了延迟评估并根据计划结构进行了优化。调试功能使程序员可以先在本地计算机上运行,然后再将其作业部署到大型群集中。FlumeJava 的核心抽象包含了以下部分:
PCollection, a immutable bag of elements of typeT, which can be created from an in-memory JavaCollectionor from reading a file with encoding specified byrecordOf.recordOf(...), specifies the encoding of the instancePTable, a subclass ofPCollection>, an immutable multi-map with keys of typeKand values of typeVparallelDo(), can express both the map and reduce parts of MapReducegroupByKey(), same as shuffle step of MapReducecombineValues(), semantically a special case ofparallelDo(), a combination of a MapReduce combiner and a MapReduce reducer, which is more efficient than doing all the combining in the reducer.flatten, takes a list ofPCollections and returns a singlePCollection.
FlumeJava 的典型代码实现如下:
PTable<String, Integer> wordsWithOnes =
words.parallelDo(
new DoFn<String, Pair<String, Integer>> () {
void process(String word,
EmitFn<Pair<String, Integer>> emitFn) {
emitFn.emit(Pair.of(word, 1));
}
}, tableOf(strings(), ints()));
PTable<String, Collection<Integer>>
groupedWordsWithOnes = wordsWithOnes.groupByKey();
PTable<String, Integer> wordCounts =
groupedWordsWithOnes.combineValues(SUM_INTS);
使用 FlumeJava 传递 MapReduce 作业的优点之一是,它通过使用延迟评估延迟执行并行操作来自动启用优化。每个 PCollection 对象的状态都可以推迟(尚未计算)并具体化(计算)。程序调用 parallelDo() 时,它将创建一个指向实际延迟操作对象的操作指针。这些操作形成一个称为执行计划的有向无环图。在调用 run() 之前,不会对执行计划进行评估。这将导致执行计划的优化和前向拓扑顺序的评估。这些将模块化执行计划转变为有效计划的优化策略包括:
-
Fusion: $f(g(x))=>g \circ f(x)$,本质上是功能组成。通过将多个可组合步骤组合为一个步骤,通常可以帮助减少给定工作所需的步骤数量。
-
MapShuffleCombineReduce (MSCR) Operation: 将 ParallelDo,GroupByKey,CombineValues 和 Flatten 组合到一个 MapReduce 作业中。这将 MapReduce 扩展为接受多个输入和多个输出。下图说明了具有 3 个输入通道,2 个分组(“ GroupByKey”)输出通道和 1 个直通输出通道的 MSCR 操作的情况。
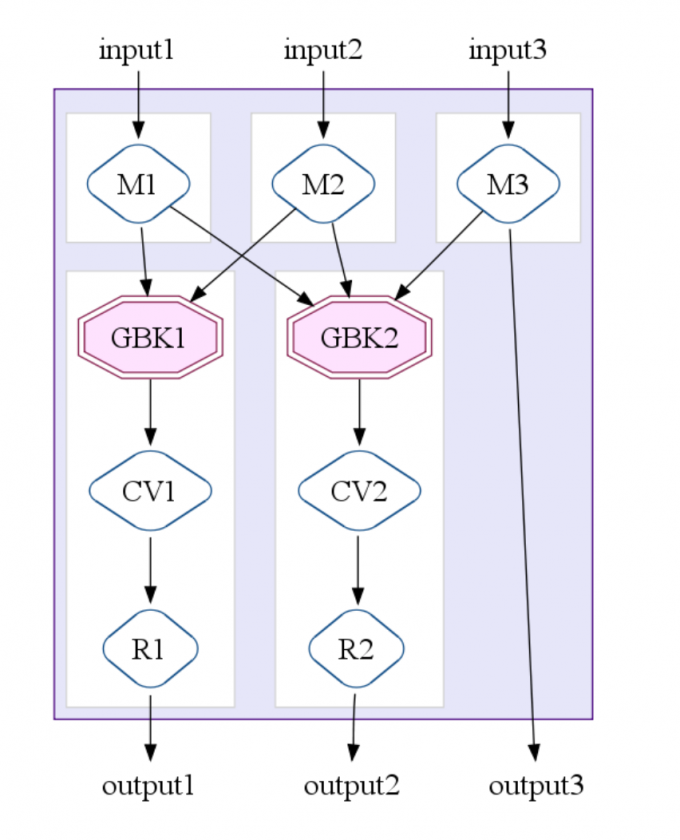
总体优化器策略涉及一系列优化操作,其最终目标是产生最少,最有效的 MSCR 操作:
- Sink Flatten: $h(f(a)+g(b)) \rightarrow h(f(a))+h(g(b))$
- Lift combineValues operations: If a
CombineValuesoperation immediately follows aGroupByKeyoperation, theGroupByKeyrecords the fact and originalCombineValuesis left in place, which can be treated as normalParallelDooperation and subject to ParallelDo fusions. - Insert fusion blocks:
- Fuse
ParallelDos - Fuse MSCRs: create MSCR operations, and convert any remaining unfused ParallelDo operations into trivial MSCRs.
SiteData 示例显示,在最终执行计划中,可以将 16 个并行数据操作优化为两个 MSCR 操作。优化器的局限性在于所有这些优化都是基于执行计划的结构,FlumeJava 不会分析用户定义函数的内容。
Dryad
Dryad 是一种通用的数据并行执行引擎,可让开发人员为计算明确地指定任意有向无环图(DAG),其中每个顶点都是计算任务,边代表通信通道(文件,TCP 管道或 Shared-Memory FIFI)。Dryad 作业是一种逻辑计算图,在运行时会自动映射到物理资源。从程序员的角度来看,通道产生或消耗堆对象,而数据通道的类型在读取或写入这些对象时没有区别。在 Dryad 系统中,一个名为“作业管理器”的进程连接到集群网络,并通过咨询名称服务器(NS)并将命令委派给在集群中每台计算机上运行的守护程序(D)来调度作业。