快速开始
快速开始
环境配置
搭建本地实例
Flink 本身可以单独部署,如果你需要读写 HDFS 中的数据,则需要选择对应的 Hadoop 版本了,在初学阶段笔者还是建议单独部署即可,到这里下载一个编译好的版本,然后直接解压缩即可:
$ cd ~/Downloads # Go to download directory
$ tar xzf flink-*.tgz # Unpack the downloaded archive
$ cd flink-1.0.3
$ bin/start-local.sh # Start Flink
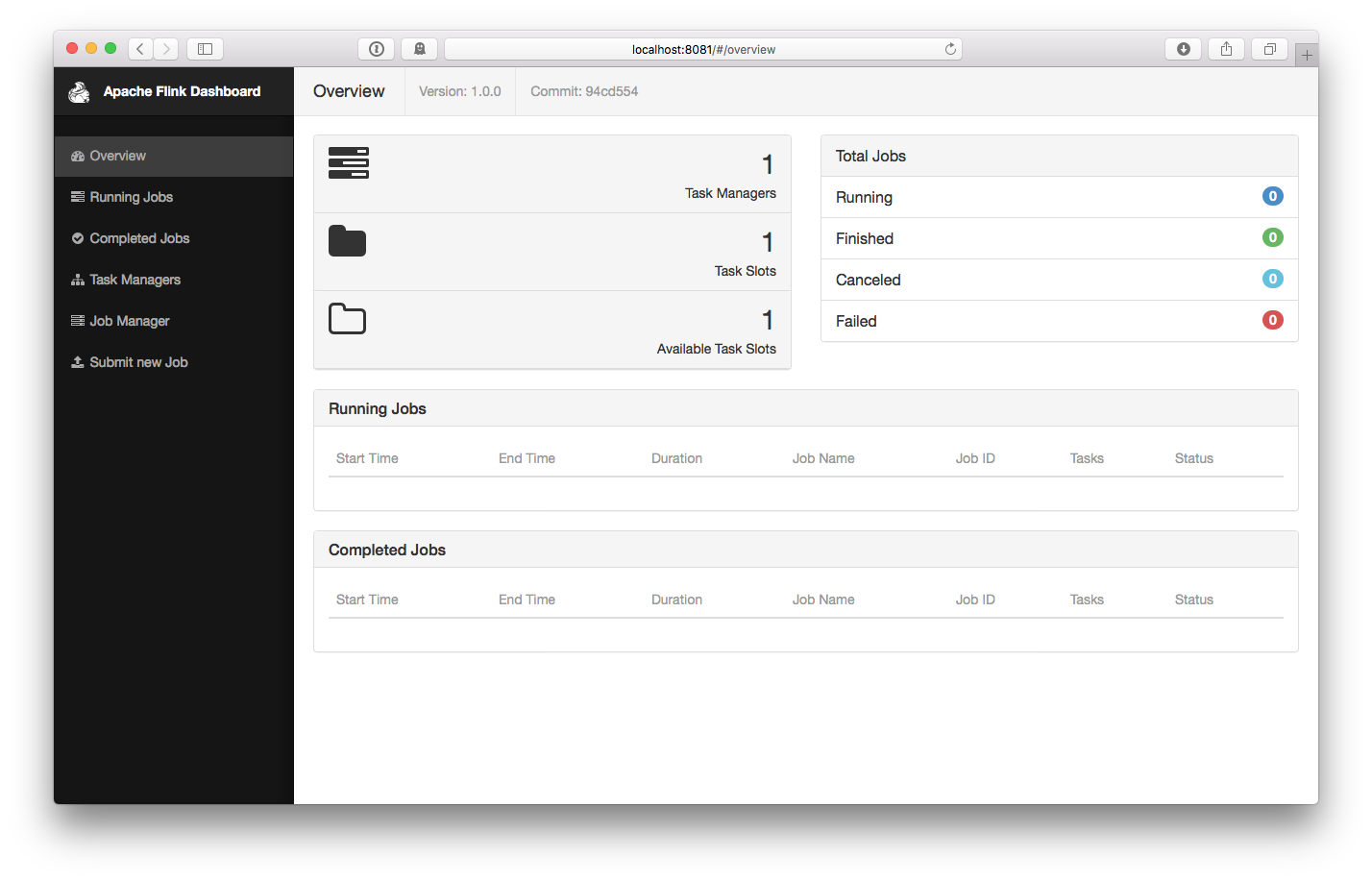
然后转到 http://localhost:8081 就可以看到一个运行的 JobManager 实例,注意,这里也会提示你存在一个 TaskManager 实例,如下图所示:
运行示例
在搭建好了基本的运行环境之后,我们开始测试 SocketTextStreamWordCount example,即从 Socket 中读取数据然后统计出独立的单词数目,典型的 WordCounts。
首先,使用 nc 来启动一个本地的 Server
$ nc -l -p 9000
// mac 下是 nc -l 9000
将任务的 Jar 包提交到 Flink:
$ bin/flink run examples/streaming/SocketTextStreamWordCount.jar \
--hostname localhost \
--port 9000
Printing result to stdout. Use --output to specify output path.
03/08/2016 17:21:56 Job execution switched to status RUNNING.
03/08/2016 17:21:56 Source: Socket Stream -> Flat Map(1/1) switched to SCHEDULED
03/08/2016 17:21:56 Source: Socket Stream -> Flat Map(1/1) switched to DEPLOYING
03/08/2016 17:21:56 Keyed Aggregation -> Sink: Unnamed(1/1) switched to SCHEDULED
03/08/2016 17:21:56 Keyed Aggregation -> Sink: Unnamed(1/1) switched to DEPLOYING
03/08/2016 17:21:56 Source: Socket Stream -> Flat Map(1/1) switched to RUNNING
03/08/2016 17:21:56 Keyed Aggregation -> Sink: Unnamed(1/1) switched to RUNNING
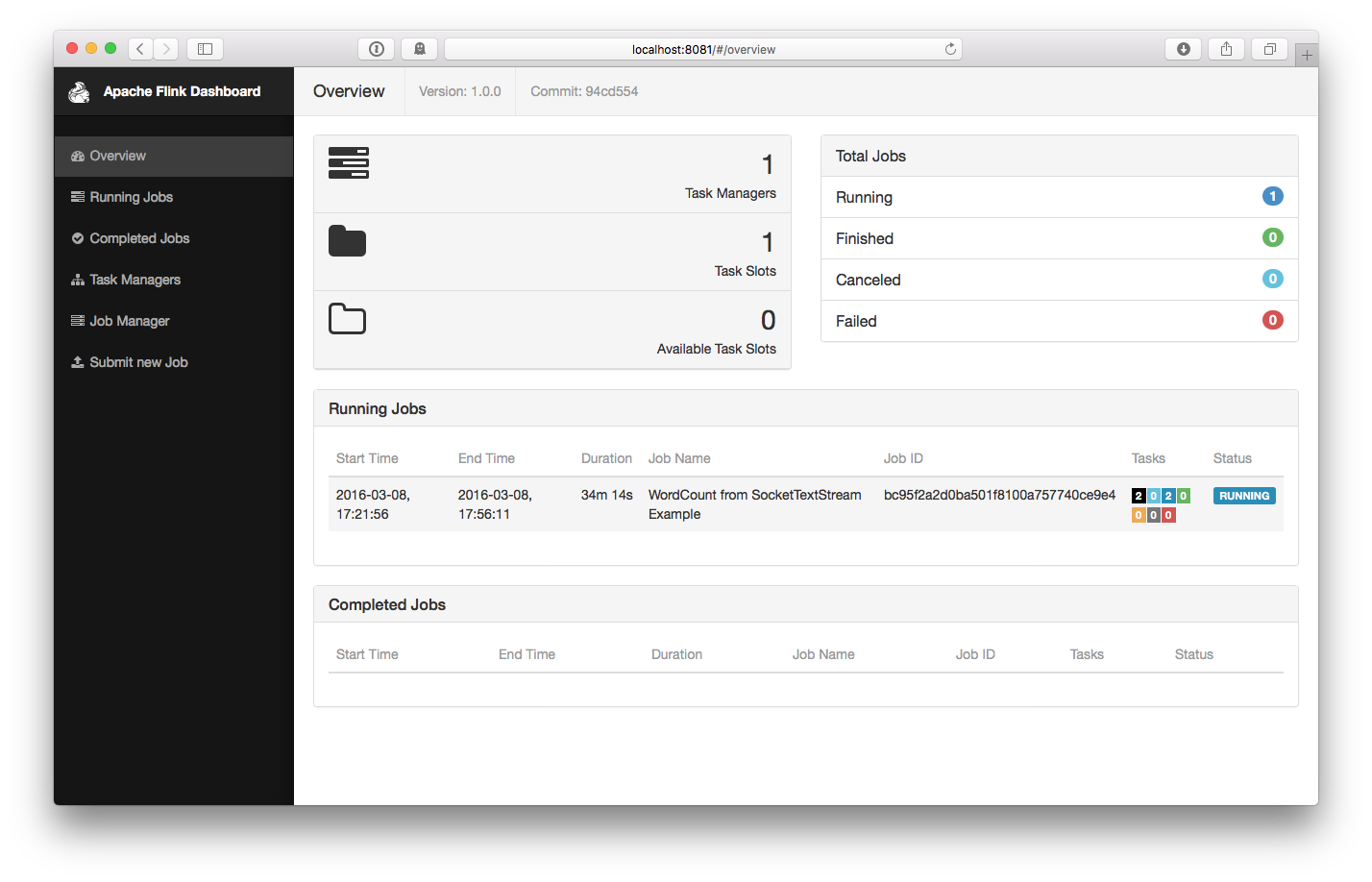
该任务会连接到 Socket 然后等待输入,你可以在 Web 界面中判断任务是否正常运行:
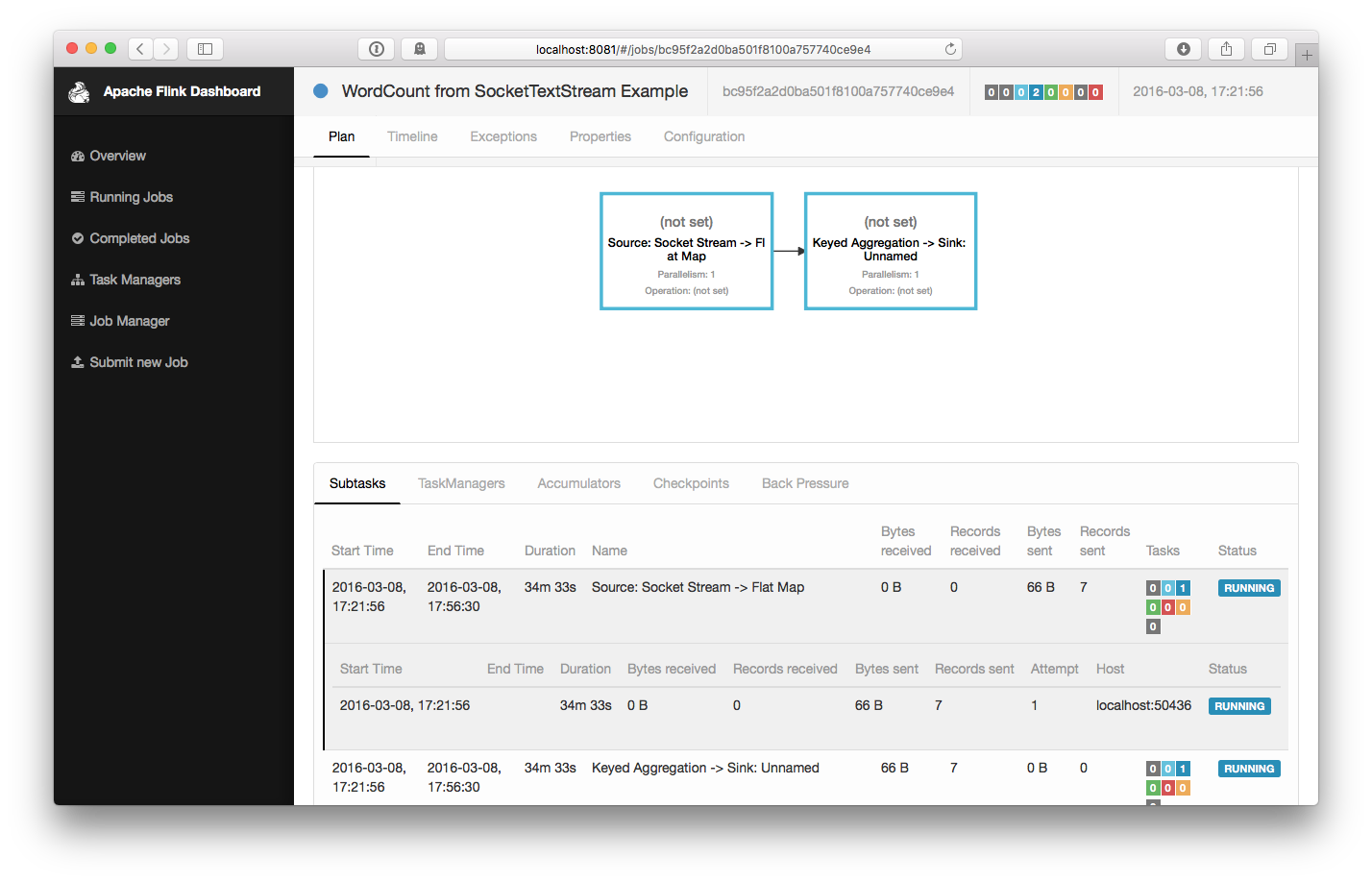
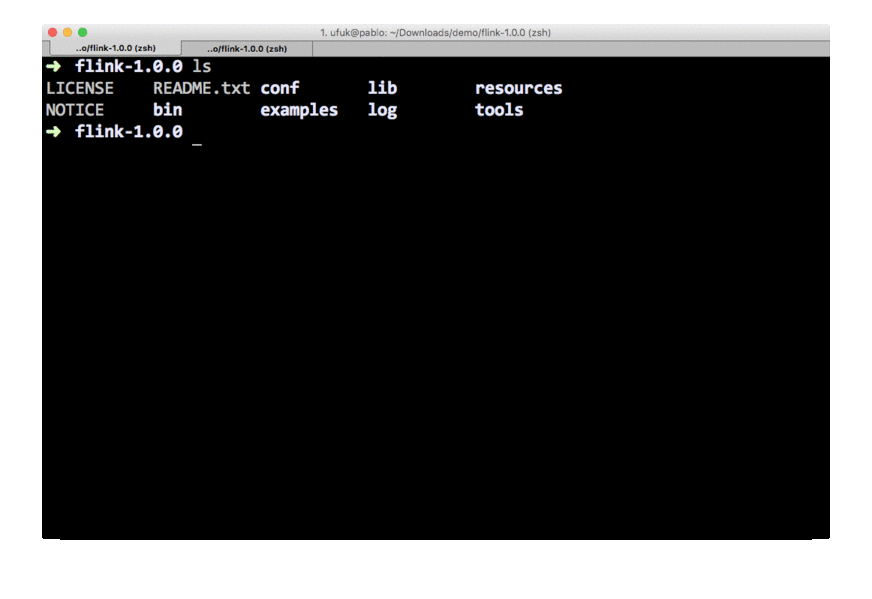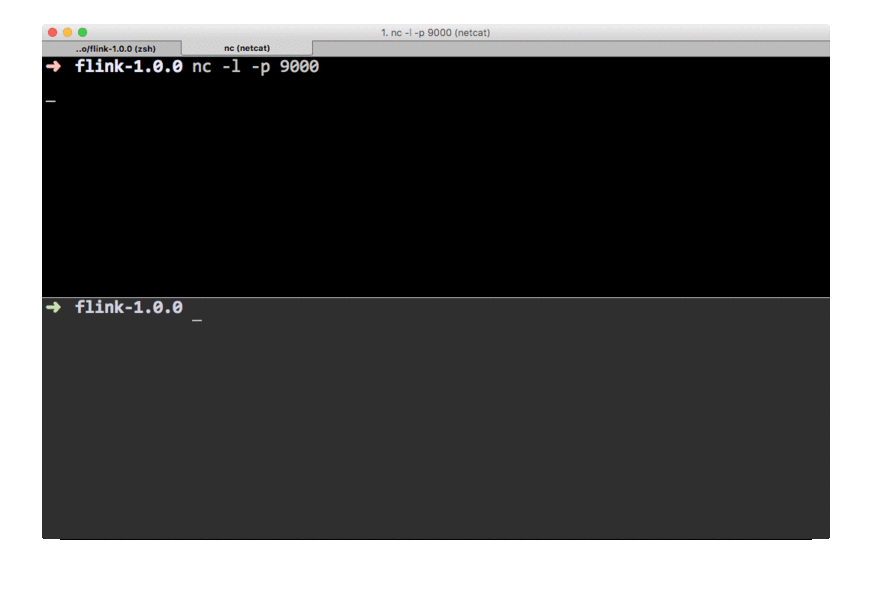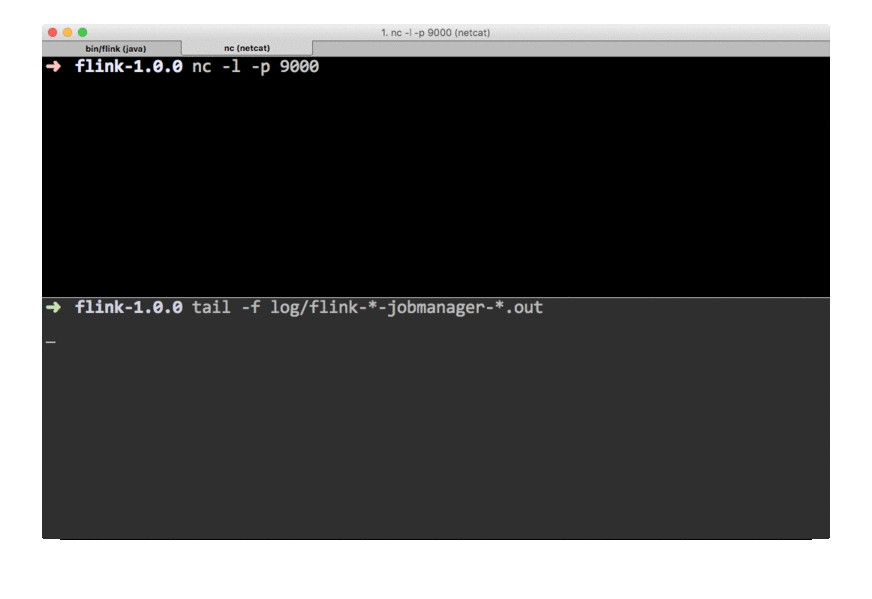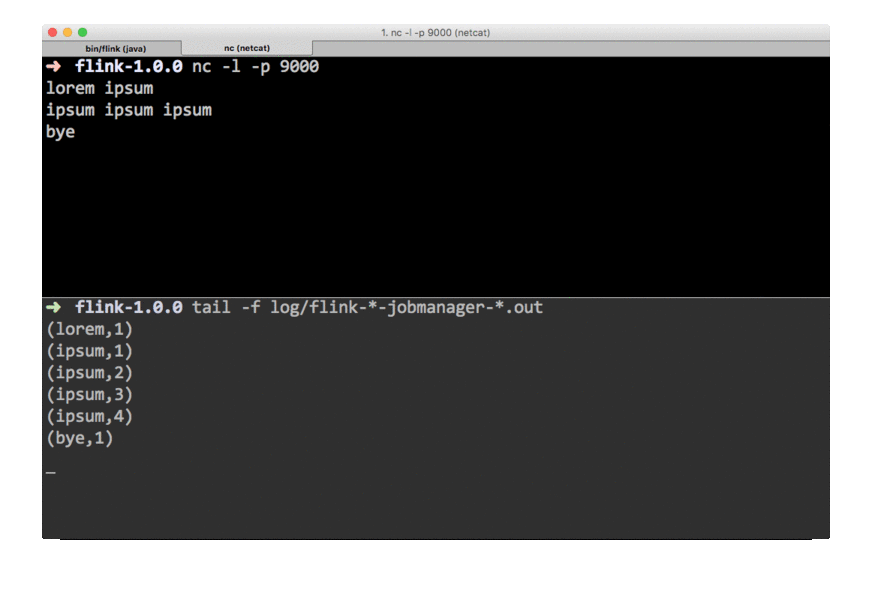
在刚才的 nc 终端里输入一些数据
$ nc -l -p 9000
lorem ipsum
ipsum ipsum ipsum
bye
结果会被直接统计出来
$ tail -f log/flink-*-jobmanager-*.out
(lorem,1)
(ipsum,1)
(ipsum,2)
(ipsum,3)
(ipsum,4)
(bye,1)
如果你要停止 Flink 集群
$ bin/stop-local.sh