
Raft
Raft
Raft 是斯坦福的 Diego Ongaro、John Ousterhout 两个人以易懂(Understandability)为目标设计的一致性算法,在 2013 年发布了论文:《In Search of an Understandable Consensus Algorithm》。Paxos 一致性算法从 90 年提出,但是其流程太过于繁杂实现起来也比较复杂;而 Raft 一致性算法就是比 Paxos 简单又能实现 Paxos 所解决的问题的一致性算法,从 2013 年发布,两年多时间内就有了十多种语言的 Raft 算法实现框架,较为出名的有 etcd,Google 的 Kubernetes 也是用了 etcd 作为他的服务发现框架。
Raft 是一个用于日志复制,同步的一致性算法,它提供了和 Paxos 一样的功能和性能,只要保证 n/2+1 节点正常就能够提供服务;但是不同于 Paxos 算法直接从分布式一致性问题出发推导出来,Raft 算法则是从多副本状态机的角度提出,用于管理多副本状态机的日志复制。为了强调可理解性,Raft 将一致性算法分解为几个关键流程(模块):Leader 选举(Leader election)、日志同步(Log replication)、安全性(Safety)、日志压缩(Log compaction)、成员变更(Membership change)等,通过将分布式一致性这个复杂的问题转化为一系列的小问题进而各个击破的方式来解决问题。同时它通过实施一个更强的一致性来减少一些不必要的状态,进一步降低了复杂性。Raft 还允许线上进行动态的集群扩容,利用有交集的大多数机制来保证安全性。
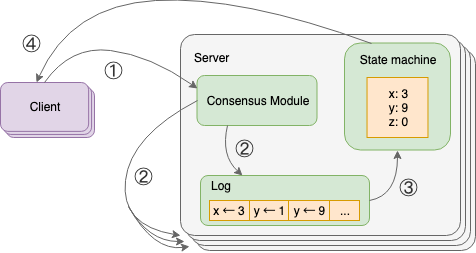
Raft 的主要流程包含以下步骤:
- Raft 开始时在集群中选举出 Leader 负责日志复制的管理;
- Leader 接受来自客户端的事务请求(日志),并将它们复制给集群的其他节点,然后负责通知集群中其他节点提交日志,Leader 负责保证其他节点与他的日志同步;
- 当 Leader 宕掉后集群其他节点会发起选举选出新的 Leader;
系统角色
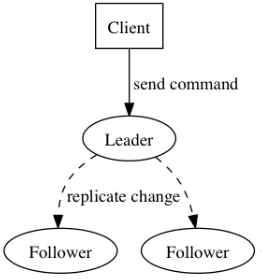
Raft 将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选人(Candidate):
- Leader:接受客户端请求,并向 Follower 同步请求日志,当日志同步到大多数节点上后告诉 Follower 提交日志。
- Follower:接受并持久化 Leader 同步的日志,在 Leader 告之日志可以提交之后,提交日志。
- Candidate:Leader 选举过程中的临时角色。
Raft 要求系统在任意时刻最多只有一个 Leader,正常工作期间只有 Leader 和 Followers;算法将时间分为一个个的任期(term),每一个 term 的开始都是 Leader 选举。Raft 算法角色状态转换如下:
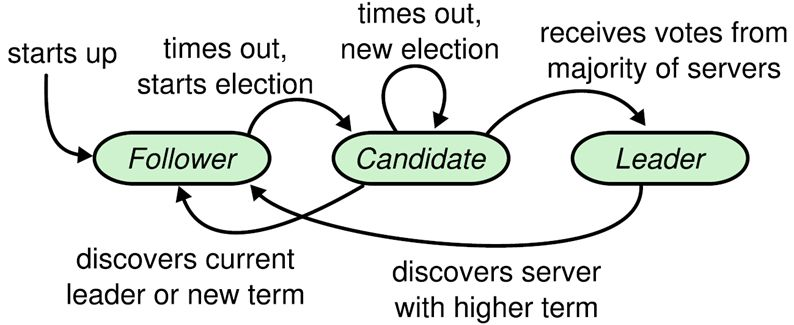
Follower 只响应其他服务器的请求。如果 Follower 超时没有收到 Leader 的消息,它会成为一个 Candidate 并且开始一次 Leader 选举。收到大多数服务器投票的 Candidate 会成为新的 Leader。Leader 在宕机之前会一直保持 Leader 的状态。
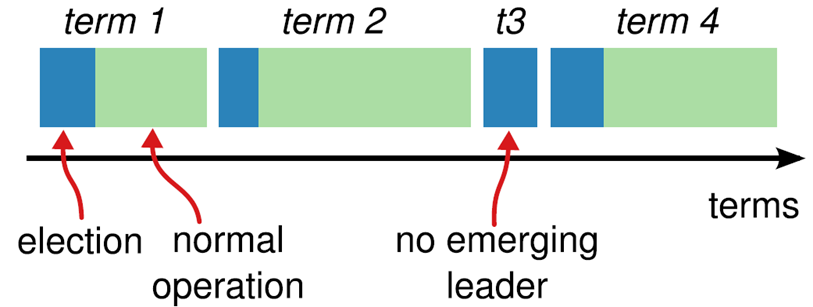
在成功选举 Leader 之后,Leader 会在整个 term 内管理整个集群。如果 Leader 选举失败,该 term 就会因为没有 Leader 而结束。Splite Vote 是因为如果同时有两个候选人向大家邀票,这时通过类似加时赛来解决,两个候选者在一段 timeout 比如 300ms 互相不服气的等待以后,因为双方得到的票数是一样的,一半对一半,那么在 300ms 以后,再由这两个候选者发出邀票,这时同时的概率大大降低,那么首先发出邀票的的候选者得到了大多数同意,成为领导者 Leader,而另外一个候选者后来发出邀票时,那些 Follower 选民已经投票给第一个候选者,不能再投票给它,它就成为落选者了,最后这个落选者也成为普通 Follower 一员了。
Raft 与 Multi-Paxos 对比
Raft 与 Multi-Paxos 有着千丝万缕的关系,下面总结了 Raft 与 Multi-Paxos 的异同。Raft 与 Multi-Paxos 中相似的概念:
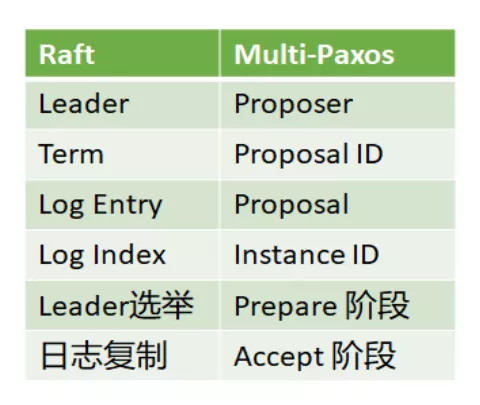
- Raft 的 Leader 即 Multi-Paxos 的 Proposer。
- Raft 的 Term 与 Multi-Paxos 的 Proposal ID 本质上是同一个东西。
- Raft 的 Log Entry 即 Multi-Paxos 的 Proposal。
- Raft 的 Log Index 即 Multi-Paxos 的 Instance ID。
- Raft 的 Leader 选举跟 Multi-Paxos 的 Prepare 阶段本质上是相同的。
- Raft 的日志复制即 Multi-Paxos 的 Accept 阶段。
Raft 与 Multi-Paxos 的不同:
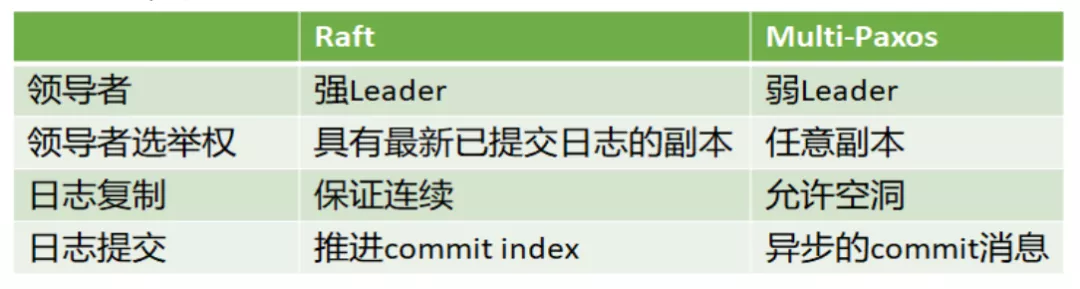
Raft 假设系统在任意时刻最多只有一个 Leader,提议只能由 Leader 发出(强 Leader),否则会影响正确性;而 Multi-Paxos 虽然也选举 Leader,但只是为了提高效率,并不限制提议只能由 Leader 发出(弱 Leader)。强 Leader 在工程中一般使用 Leader Lease 和 Leader Stickiness 来保证:
- Leader Lease:上一任 Leader 的 Lease 过期后,随机等待一段时间再发起 Leader 选举,保证新旧 Leader 的 Lease 不重叠。
- Leader Stickiness:Leader Lease 未过期的 Follower 拒绝新的 Leader 选举请求。
Raft 限制具有最新已提交的日志的节点才有资格成为 Leader,Multi-Paxos 无此限制。Raft 在确认一条日志之前会检查日志连续性,若检查到日志不连续会拒绝此日志,保证日志连续性,Multi-Paxos 不做此检查,允许日志中有空洞。Raft 在 AppendEntries 中携带 Leader 的 commit index,一旦日志形成多数派,Leader 更新本地的 commit index 即完成提交,下一条 AppendEntries 会携带新的 commit index 通知其它节点;Multi-Paxos 没有日志连接性假设,需要额外的 commit 消息通知其它节点。
Links
- 建议在 The Secret Lives of Data 查看 Raft 算法的动画演示讲解。