
安全性
安全性
要保证所有的状态机有一样的状态,单凭复制与选举算法还不够。例如有 3 个节点 A、B、C,如果 A 为主节点期间 C 挂了,此时消息被多数节点(A,B)接收,所以 A 会提交这些日志。此时若 A 挂了,而 C 恢复且被选为主节点,则 A 已经提交的日志会被 C 的日志覆盖,从而导致状态机的状态不一致。
Raft 增加了如下两条限制以保证安全性:
- 拥有最新的已提交的 log entry 的 Follower 才有资格成为 Leader。
- Leader 只能推进 commit index 来提交当前 term 的已经复制到大多数服务器上的日志,旧 term 日志的提交要等到提交当前 term 的日志来间接提交(log index 小于 commit index 的日志被间接提交)。
选主的限制
拥有最新的已提交的 log entry 的 Follower 才有资格成为 Leader。
在所有的主从结构的一致性算法中,主节点最终都必须包含所有提交的日志。有些算法在从节点不包含所有已提交日志的情况下,依旧允许它当选为主节点,之后从节点会将这些日志同步到主节点上。但是 Raft 采用了简单的方式,只允许那些包含所有已提交日志的节点当选为主节点。
注意到节点当选主节点要求得到多数票,同时一个日志被提交的前提条件是它被多数节点接收,综合这两点,说明选举要产生结果,则至少有一个节点在场,它是包含了当前已经提交的所有日志的。
因此,Raft 算法在处理要求选举的 RequestVote 消息时做了限制:消息中会携带 Candidate 的 log 消息,而在投票时,Follower 会判断 Candidate 的消息是不是比自己“更新”(下文定义),如果不如自己“新”,则拒绝为该 Candidate 投票。
Raft 会首先判断两个节点最后一个 log entry 的 term,哪个节点的对应的 term 更大则代表该节点的日志“更新”;如果 term 的大小一致,则谁的 log entry 更多谁就“更新”。注意,加了这个限制后,选出的节点不会是“最新的”,即包含所有日志;但会是足够新的,至少比半数节点更新,而这也意味着它所包含的日志都是可以被提交的(但不一定已经提交)。
这个保证是在 RequestVote RPC 中做的,Candidate 在发送 RequestVote RPC 时,要带上自己的最后一条日志的 term 和 log index,其他节点收到消息时,如果发现自己的日志比请求中携带的更新,则拒绝投票。日志比较的原则是,如果本地的最后一条 log entry 的 term 更大,则 term 大的更新,如果 term 一样大,则 log index 更大的更新。
提交前一个 term 的日志
Leader 只能推进 commit index 来提交当前 term 的已经复制到大多数服务器上的日志,旧 term 日志的提交要等到提交当前 term 的日志来间接提交(log index 小于 commit index 的日志被间接提交)。
这里我们要讨论一个特别的情况。我们知道一个主节点如果发现自己任期(term)内的某条日志已经被存储到了多数节点上,主节点就会提交这条日志。但如果主节点在提交之前就挂了,之后的主节点会尝试把前任未提交的这些日志复制到所有子节点上,但与之前不同,仅仅判断这些日志被复制到多数节点,新的主节点并不能立马提交这些日志,下面举一个反例:
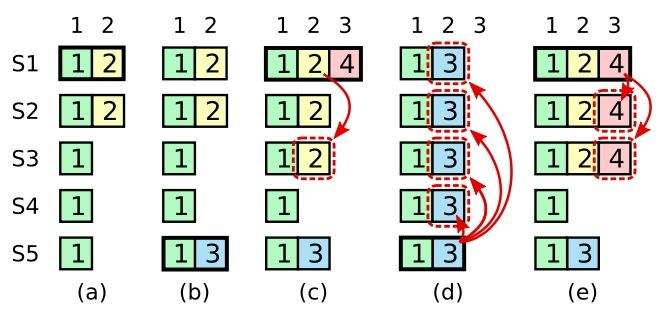
- 在 (a) 时,S1 当选并将日志编号为 2 的日志复制到其它节点上。
- 在 (b) 时,S1 宕机,S5 获得来自 S3 与 S4 的投票,当选为 term 3 的主节点,此时收到来自客户端的消息,写入自己编号为 2 的日志。
- (c) 期间,S5 宕机而 S1 重启完毕,它重新当选为主节点并继续将自己的日志复制给 S3,此时编号为 2 且 term 为 2 的日志已经被复制到多数节点,但它还不能被提交。
- 如果此时 S1 宕机,如 (d) 所示,此时 S5 获得来自 S2 S3 S4 的投票,当选新的主节点,此时它将用自己的编号为 2,term 为 3 的日志覆盖其它节点的日志。
- 而如果 S1 继续存活,且在自己的任期内将某条日志复制到多数节点,如 (e) 所示,则此时 S5 已经不可能继续当选为主节点,因此该日志之前的所有日志均可被提交(包括前任创建的,编号 2 的日志)。
上例中的 (c) 和 (d) 说明了,即使前任的日志已经被复制到多数节点上,它依然可能被覆盖。因此 Raft 并不通过计算前任日志的复制次数来判断是否提交这些日志,Raft 只对自己任期内的日志计数并在复制到多数节点时进行提交,且在提交这条日志的同时提交之前的所有日志。
Raft 算法会出现这个额外的问题,是因为它在复制前任的日志时,会保留前任的 term,而其它一致性算法会为这些日志使用新的 term。Raft 算法的优势在于方便推理日志的形成过程,同时新的主节点需要发送的前任日志数目会更少。
网络分区容忍
根据前文介绍的 Raft 的两大安全性保障,我们能知道 Raft 天然兼容网络分区的情况。
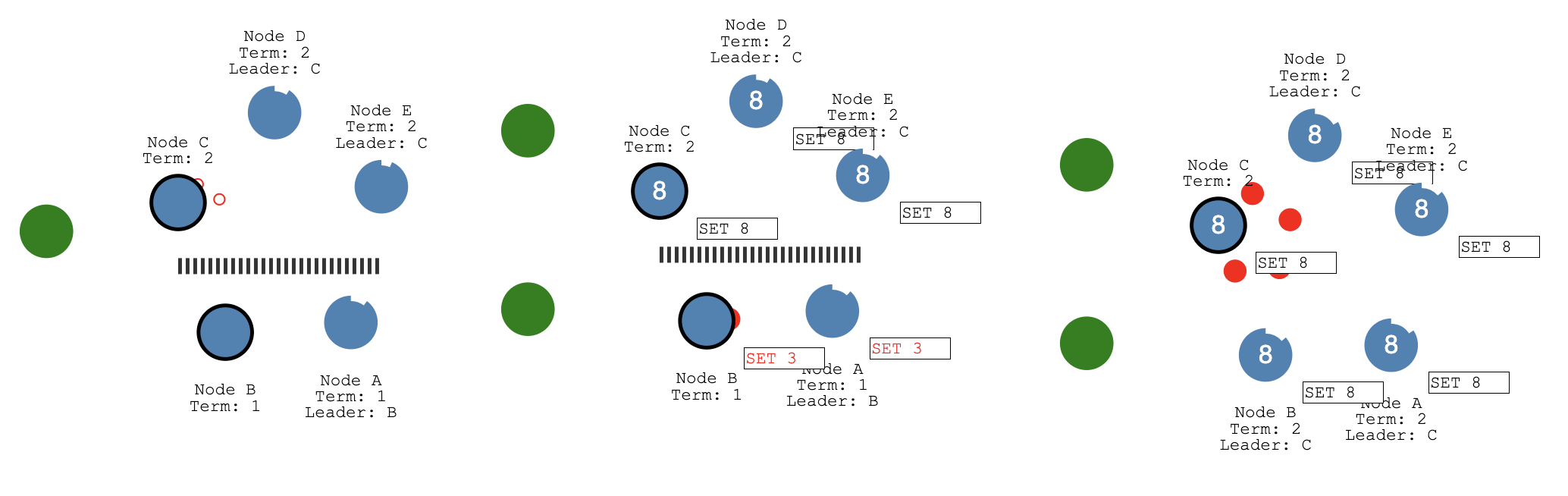
在开始的时候所有节点的 Leader 是 B,而后发生了网络分区情况,独立的三个节点选择了 C 作为新的 Leader。此时有两个客户端分别设置了不同的值 3 和 8,节点 B 因为无法与绝大部分节点通信,因此属于不可提交状态;而新成组的 3 个节点会进行值的设置。
在网络分区被修复后,B 接收到了更高的 Electron Term 因此退化为普通的节点,然后根据 Leader 上最新的日志回滚本地未提交的 Entries。