
日志复制
日志复制(Log Replication)
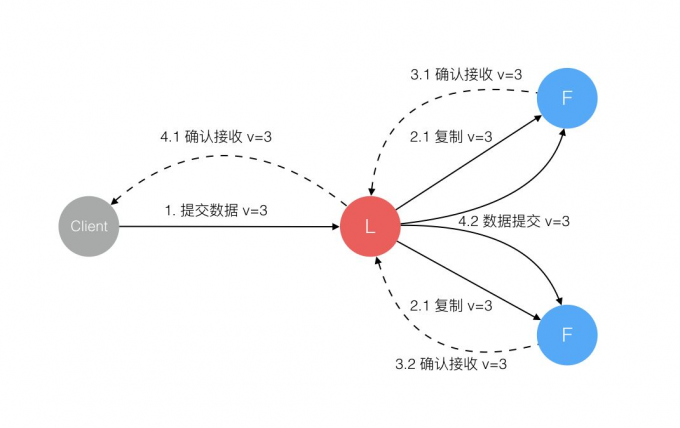
Leader 选出后,就开始接收客户端的请求。Leader 把请求作为日志条目(Log entries)加入到它的日志中,然后并行的向其他服务器发起 AppendEntries RPC 复制日志条目。当这条日志被复制到大多数服务器上,Leader 将这条日志应用到它的状态机并向客户端返回执行结果。
日志结构
Log Replication 分为两个主要步骤:复制(Replication)和 提交(Commit)。当一个节点被选为主节点后,它开始对外提供服务,收到客户端的 command 后,主节点会首先将 command 添加到自己的日志队列中,然后并行地将消息发送给其它所有的节点,在确保消息被安全地复制(下文解释)后,主节点会将该消息提交到状态机中,并返回状态机执行的结果。如果 Follower 挂了或因为网络原因消息丢失了,主节点会不断重试直到所有从节点最终成功复制该消息。
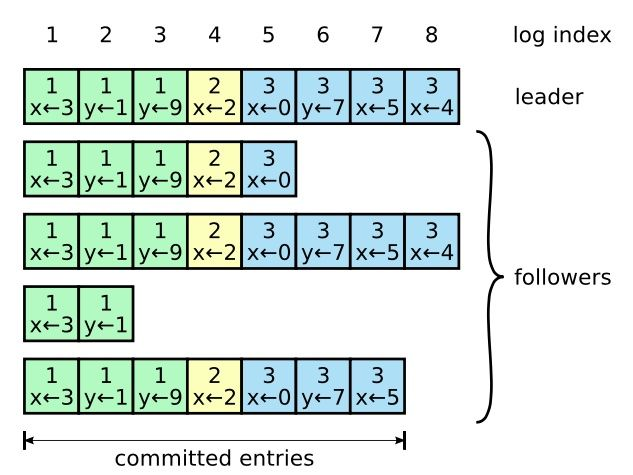
日志由许多条目(log entry)组成,条目顺序编号。条目包含它生成时节点所在的 term(小方格中上方的数字),以及日志的内容。当一个条目被认为安全地被复制,且提交到状态机时,我们认为它处于“已提交(committed)”状态。
是否将一个条目提交到状态机是由主节点决定的。Raft 要保证提交的条目会最终被所有的节点执行。当主节点判断一个条目已经被复制到大多数节点时,就会提交 /Commit 该条目,提交一个条目的同时会提交该条目之前的所有条目,包括那些之前由其它主节点创建的条目(还有些特殊情况下面会提)。主节点会记录当前提交的日志编号 (log index),并在发送心跳时带上该信息,这样其它节点最终会同步提交日志。
日志同步
上面说的是“提交”,那么“复制”是如何进行的?在现实情况下,主从节点的日志可能不一致(例如在消息到达从节点前主节点挂了,而从节点被选为了新的主节点,此时主从节点的日志不一致)。Raft 算法中,主节点需要处理不一致的情况,它要求所有的从节点复制自己的所有日志。
要复制所有日志,就要先找到日志开始不一致的位置,如何做到呢?Raft 当主节点接收到新的 command 时,会发送 AppendEntries 让从节点复制日志,不一致的情况也会在这时被处理(AppendEntries 消息同时还兼职作为心跳信息)。某些 Followers 可能没有成功的复制日志,Leader 会无限的重试 AppendEntries RPC 直到所有的 Followers 最终存储了所有的日志条目。下面是日志不一致的示例:
主节点需要为每个从节点记录一个 nextIndex,作为该从节点下一条要发送的日志的编号。当一个节点刚被选为主节点时,为所有从节点的 nextIndex 初始化自己最大日志编号加 1(如上图示例则为 11)。接着主节点发送 AppendEntries 给从节点,此时从节点会进行一致性检查(Consistency Check)。
所谓一致性检查,指的是当主节点发送 AppendEntries 消息通知从节点添加条目时,需要将新条目 A 之前的那个条目 B 的 log index 和 term,这样,当从节点收到消息时,就可以判断自己第 log index 条日志的 term 是否与 B 的 term 相同,如果不相同则拒绝该消息,如果相同则添加条目 A。
主节点的消息被某个从节点拒绝后,主节点会将该从节点的 nextIndex 减一再重新发送 AppendEntries 消息。不断重试,最终就能找主从节点日志一致的 log index,并用主节点的新日志覆盖从节点的旧日志。当然,如果从节点接收 AppendEntries 消息后,主节点会将 nextIndex 增加一,且如果当前的最新 log index 大于 nextIndex 则会继续发送消息。
同步保证
Raft 日志同步保证如下两点:
- 如果不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的。
- 如果不同日志中的两个条目有着相同的索引和任期号,则它们之前的所有条目都是完全一样的。
第一条特性源于 Leader 在一个 term 内在给定的一个 log index 最多创建一条日志条目,同时该条目在日志中的位置也从来不会改变。第二条特性源于 AppendEntries 的一个简单的一致性检查。当发送一个 AppendEntries RPC 时,Leader 会把新日志条目紧接着之前的条目的 log index 和 term 都包含在里面。如果 Follower 没有在它的日志中找到 log index 和 term 都相同的日志,它就会拒绝新的日志条目。
一般情况下,Leader 和 Followers 的日志保持一致,因此 AppendEntries 一致性检查通常不会失败。然而,Leader 崩溃可能会导致日志不一致:旧的 Leader 可能没有完全复制完日志中的所有条目。
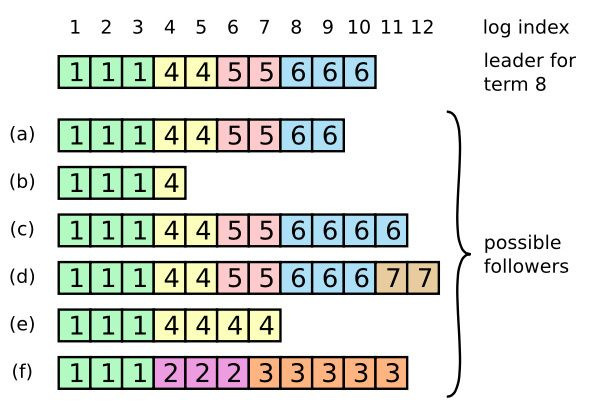
上图阐述了一些 Followers 可能和新的 Leader 日志不同的情况。一个 Follower 可能会丢失掉 Leader 上的一些条目,也有可能包含一些 Leader 没有的条目,也有可能两者都会发生。丢失的或者多出来的条目可能会持续多个任期。Leader 通过强制 Followers 复制它的日志来处理日志的不一致,Followers 上的不一致的日志会被 Leader 的日志覆盖。
Leader 为了使 Followers 的日志同自己的一致,Leader 需要找到 Followers 同它的日志一致的地方,然后覆盖 Followers 在该位置之后的条目。Leader 会从后往前试,每次 AppendEntries 失败后尝试前一个日志条目,直到成功找到每个 Follower 的日志一致位点,然后向后逐条覆盖 Followers 在该位置之后的条目。
日志压缩
在实际的系统中,不能让日志无限增长,否则系统重启时需要花很长的时间进行回放,从而影响可用性。Raft 采用对整个系统进行 snapshot 来解决,snapshot 之前的日志都可以丢弃。每个副本独立的对自己的系统状态进行 snapshot,并且只能对已经提交的日志记录进行 snapshot。
Snapshot 中包含以下内容:
- 日志元数据。最后一条已提交的 log entry 的 log index 和 term。这两个值在 snapshot 之后的第一条 log entry 的 AppendEntries RPC 的完整性检查的时候会被用上。
- 系统当前状态。
当 Leader 要发给某个日志落后太多的 Follower 的 log entry 被丢弃,Leader 会将 snapshot 发给 Follower。或者当新加进一台机器时,也会发送 snapshot 给它。发送 snapshot 使用 InstalledSnapshot RPC。
做 snapshot 既不要做的太频繁,否则消耗磁盘带宽,也不要做的太不频繁,否则一旦节点重启需要回放大量日志,影响可用性。推荐当日志达到某个固定的大小做一次 snapshot。做一次 snapshot 可能耗时过长,会影响正常日志同步。可以通过使用 copy-on-write 技术避免 snapshot 过程影响正常日志同步。