
选举与成员变更
Leader 选举
节点启动时,默认处于 Follower 的状态,所以开始时所有节点均是 Follower,那么什么时候触发选主呢?Raft 用“心跳”的方式来保持主从节点的联系,如果长时间没有收到主节点的心跳,则开始选主。这里会涉及到两个时间:
- 心跳间隔,主节点隔多长时间发送心跳信息
- 等待时间(election timeout),如果超过这个时间仍然没有收到心跳,则认为主节点宕机。一般每个节点各自在 150 ~ 300ms 间随机取值。
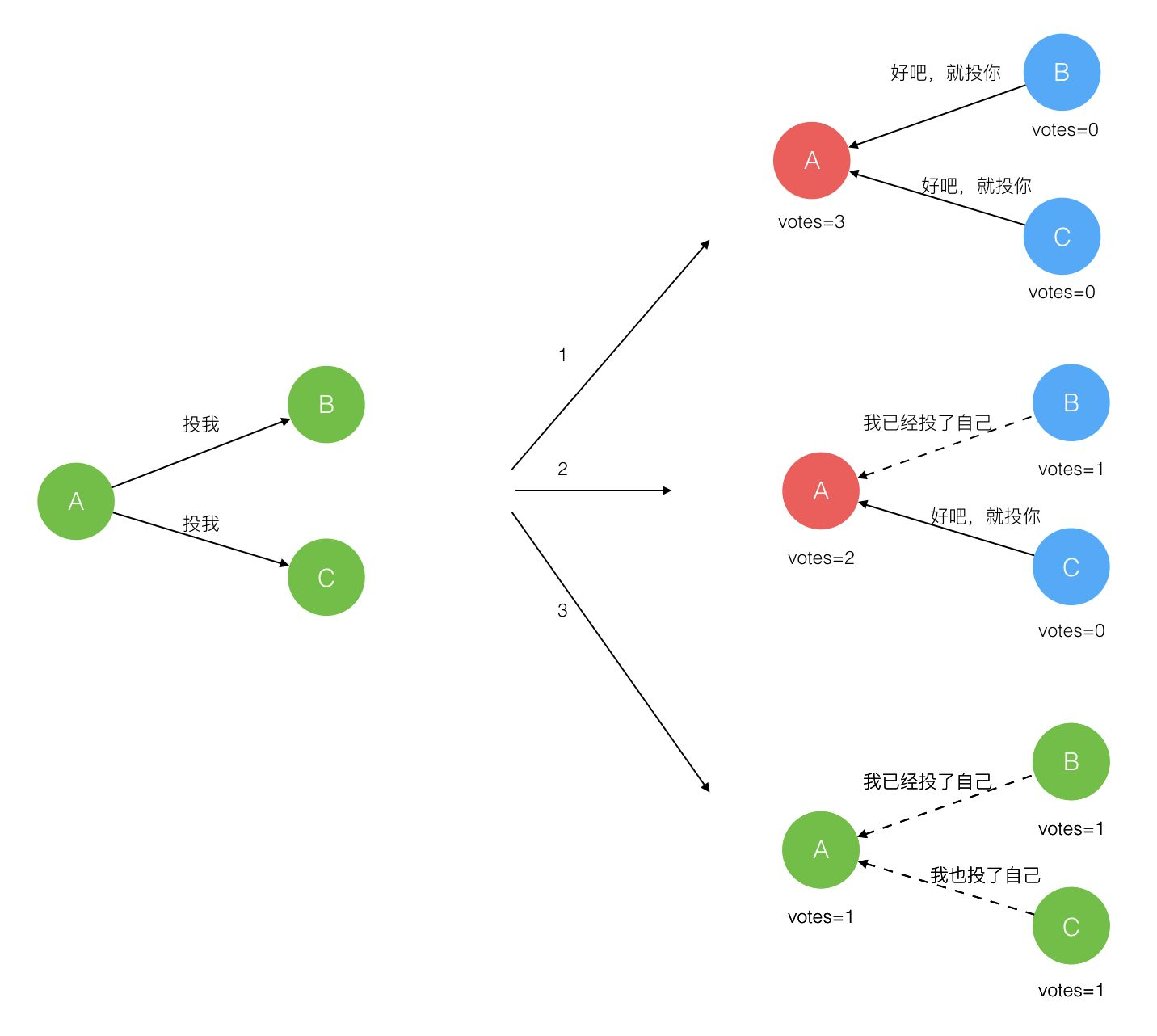
当一个节点在等待时间内没有收到主节点的心跳信息,它首先将自己保存的 term 增加 1 并进入 Candidate 状态。此时它会先投票给自己,然后并行发送 RequestVote 消息给其它所有节点,请求这些节点投票给自己。然后等待直到以下 3 种情形之一发生:
-
赢得了多数的选票,成功选举为 Leader;Candidate 节点需要收到集群中与自己 term 相同的所有节点中大于一半的票数(当然如果节点 term 比自己大,是不会理睬自己的选举消息的)。节点投票时会采取先到先得的原则,对于某个 term,最多投出一票(后面还会再对投票加一些限制)。这样能保证某个 term 中,最多只会产生一个 leader。当一个 Candidate 变成主节点后,它会向其它所有节点发送心跳信息,这样其它的 Candidate 也会变成 Follower。
-
收到了 Leader 的消息,表示有其它服务器已经抢先当选了 Leader;在等待投票的过程中,Candidate 收到其它主节点的心跳信息(只有主节点才会向其它节点发心跳),且信息中包含的 term 大于等于自己的 term,则当前节点放弃竞选,进入 Follower 状态。当然,如前所说,如果心跳中的 term 小于自己,则不予理会。
-
没有服务器赢得多数的选票,Leader 选举失败,等待选举时间超时后发起下一次选举。一般发生在多个 Follower 同时触发选举,而各节点的投票被分散了,导致没有 Candidate 能得到多数票。超过投票的等待时间后,节点触发新一轮选举。理论上,选举有可能永远平票,Raft 中由于各个节点的超时时间是随机的,实际上平票不太会永远持续下去。
Leader 后,Leader 通过定期向所有 Followers 发送心跳信息维持其统治。若 Follower 一段时间未收到 Leader 的心跳则认为 Leader 可能已经挂了,再次发起 Leader 选举过程。Raft 保证选举出的 Leader 上一定具有最新的已提交的日志。
成员变更
成员变更是在集群运行过程中副本发生变化,如增加/减少副本数、节点替换等。成员变更也是一个分布式一致性问题,既所有服务器对新成员达成一致。但是成员变更又有其特殊性,因为在成员变更的一致性达成的过程中,参与投票的进程会发生变化。
如果将成员变更当成一般的一致性问题,直接向 Leader 发送成员变更请求,Leader 复制成员变更日志,达成多数派之后提交,各服务器提交成员变更日志后从旧成员配置(Cold)切换到新成员配置(Cnew)。
双多数派问题
一种方法是先停止所有节点,修改配置增加新的节点,再重启所有节点,但是这样服务起停时就会中断服务,同时也可能增加人为操作失误的风险。另一种方法配置好新的节点直接加入集群,这样也会出问题:在某个时刻使用不同配置的两部分节点可能会各自选出一个主节点。因为各个服务器提交成员变更日志的时刻可能不同,造成各个服务器从旧成员配置(Cold)切换到新成员配置(Cnew)的时刻不同。成员变更不能影响服务的可用性,但是成员变更过程的某一时刻,可能出现在 Cold 和 Cnew 中同时存在两个不相交的多数派,进而可能选出两个 Leader,形成不同的决议,破坏安全性。
如下图:
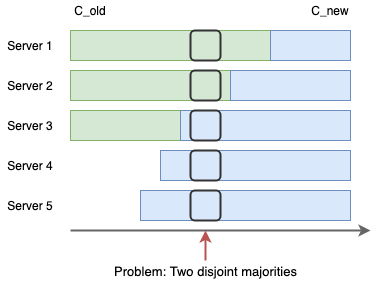
图中绿色为旧的配置,蓝色为新的配置,在中间的某个时刻,Server 1/2/3 可能会选出一个主节点,而 Server 3/4/5 可能会选出另一个,从而破坏了一致性。
两阶段的成员变更
由于成员变更的这一特殊性,成员变更不能当成一般的一致性问题去解决。为了解决这一问题,Raft 提出了两阶段的成员变更方法。集群先从旧成员配置 Cold 切换到一个过渡成员配置,称为共同一致(joint consensus),共同一致是旧成员配置 Cold 和新成员配置 Cnew 的组合 Cold U Cnew,一旦共同一致 Cold U Cnew 被提交,系统再切换到新成员配置 Cnew。
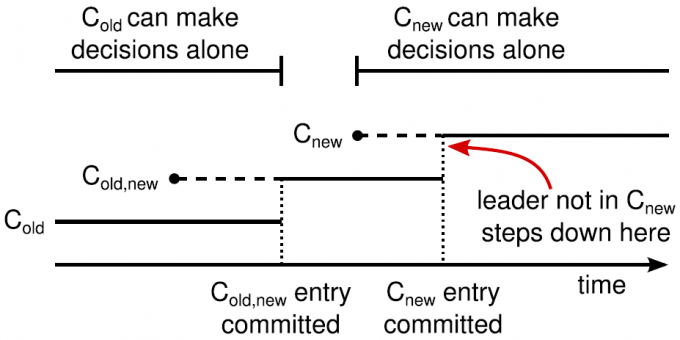
Raft 两阶段成员变更过程如下:
- Leader 收到成员变更请求从 Cold 切成 Cnew;
- Leader 在本地生成一个新的 log entry,其内容是 Cold∪Cnew,代表当前时刻新旧成员配置共存,写入本地日志,同时将该 log entry 复制至 Cold∪Cnew 中的所有副本。在此之后新的日志同步需要保证得到 Cold 和 Cnew 两个多数派的确认;
- Follower 收到 Cold∪Cnew 的 log entry 后更新本地日志,并且此时就以该配置作为自己的成员配置;
- 如果 Cold 和 Cnew 中的两个多数派确认了 Cold U Cnew 这条日志,Leader 就提交这条 log entry;
- 接下来 Leader 生成一条新的 log entry,其内容是新成员配置 Cnew,同样将该 log entry 写入本地日志,同时复制到 Follower 上;
- Follower 收到新成员配置 Cnew 后,将其写入日志,并且从此刻起,就以该配置作为自己的成员配置,并且如果发现自己不在 Cnew 这个成员配置中会自动退出;
- Leader 收到 Cnew 的多数派确认后,表示成员变更成功,后续的日志只要得到 Cnew 多数派确认即可。Leader 给客户端回复成员变更执行成功。
异常分析:
- 如果 Leader 的 Cold U Cnew 尚未推送到 Follower,Leader 就挂了,此后选出的新 Leader 并不包含这条日志,此时新 Leader 依然使用 Cold 作为自己的成员配置。
- 如果 Leader 的 Cold U Cnew 推送到大部分的 Follower 后就挂了,此后选出的新 Leader 可能是 Cold 也可能是 Cnew 中的某个 Follower。
- 如果 Leader 在推送 Cnew 配置的过程中挂了,那么同样,新选出来的 Leader 可能是 Cold 也可能是 Cnew 中的某一个,此后客户端继续执行一次改变配置的命令即可。
- 如果大多数的 Follower 确认了 Cnew 这个消息后,那么接下来即使 Leader 挂了,新选出来的 Leader 肯定位于 Cnew 中。
两阶段成员变更比较通用且容易理解,但是实现比较复杂,同时两阶段的变更协议也会在一定程度上影响变更过程中的服务可用性,因此我们期望增强成员变更的限制,以简化操作流程。两阶段成员变更,之所以分为两个阶段,是因为对 Cold 与 Cnew 的关系没有做任何假设,为了避免 Cold 和 Cnew 各自形成不相交的多数派选出两个 Leader,才引入了两阶段方案。
如果增强成员变更的限制,假设 Cold 与 Cnew 任意的多数派交集不为空,这两个成员配置就无法各自形成多数派,那么成员变更方案就可能简化为一阶段。那么如何限制 Cold 与 Cnew,使之任意的多数派交集不为空呢?方法就是每次成员变更只允许增加或删除一个成员。可从数学上严格证明,只要每次只允许增加或删除一个成员,Cold 与 Cnew 不可能形成两个不相交的多数派。
一阶段成员变更:
- 成员变更限制每次只能增加或删除一个成员(如果要变更多个成员,连续变更多次)。
- 成员变更由 Leader 发起,Cnew 得到多数派确认后,返回客户端成员变更成功。
- 一次成员变更成功前不允许开始下一次成员变更,因此新任 Leader 在开始提供服务前要将自己本地保存的最新成员配置重新投票形成多数派确认。
- Leader 只要开始同步新成员配置,即可开始使用新的成员配置进行日志同步。