
二阶段提交
二阶段提交
事务原子性的目的是在多次写操作中途出错的情况下,提供一种简单的语义。事务的结果要么是成功提交,在这种情况下,事务的所有写入都是持久化的;要么是中止,在这种情况下,事务的所有写入都被回滚(即撤消或丢弃)。原子性可以防止失败的事务搅乱数据库,避免数据库陷入半成品结果和半更新状态。这对于多对象事务和维护次级索引的数据库尤其重要。每个辅助索引都是与主数据相分离的数据结构,因此,如果你修改了一些数据,则还需要在辅助索引中进行相应的更改。原子性确保二级索引与主数据保持一致(如果索引与主数据不一致,就没什么用了)。
两阶段提交(Two-phase commit)是一种用于实现跨多个节点的原子事务提交的算法,即确保所有节点提交或所有节点中止。它是分布式数据库中的经典算法。2PC 在某些数据库内部使用,也以 XA 事务的形式对应用可用(例如 Java Transaction API 支持)或以 SOAP Web 服务的 WS-AtomicTransaction 形式提供给应用。下图说明了 2PC 的基本流程。2PC 中的提交/中止过程分为两个阶段(因此而得名),而不是单节点事务中的单个提交请求。

2PC 使用一个通常不会出现在单节点事务中的新组件:协调者(coordinator)(也称为事务管理器(transaction manager))。协调者通常在请求事务的相同应用进程中以库的形式实现(例如,嵌入在 Java EE 容器中),但也可以是单独的进程或服务。这种协调者的例子包括 Narayana,JOTM,BTM 或 MSDTC。正常情况下,2PC 事务以应用在多个数据库节点上读写数据开始。我们称这些数据库节点为参与者(participants)。当应用准备提交时,协调者开始阶段 1:它发送一个准备(prepare)请求到每个节点,询问它们是否能够提交。然后协调者会跟踪参与者的响应:
-
如果所有参与者都回答“是”,表示它们已经准备好提交,那么协调者在阶段 2 发出提交(commit)请求,然后提交真正发生。
-
如果任意一个参与者回复了“否”,则协调者在阶段 2 中向所有节点发送中止(abort)请求。
这个过程有点像西方传统婚姻仪式:司仪分别询问新娘和新郎是否要结婚,通常是从两方都收到“我愿意”的答复。收到两者的回复后,司仪宣布这对情侣成为夫妻:事务就提交了,这一幸福事实会广播至所有的参与者中。如果新娘与新郎之一没有回复”我愿意“,婚礼就会中止。
系统承诺
这个简短的描述可能并没有说清楚为什么两阶段提交保证了原子性,而跨多个节点的一阶段提交却没有。在两阶段提交的情况下,准备请求和提交请求当然也可以轻易丢失。2PC 又有什么不同呢?为了理解它的工作原理,我们必须更详细地分解这个过程:
-
当应用想要启动一个分布式事务时,它向协调者请求一个事务 ID。此事务 ID 是全局唯一的。
-
应用在每个参与者上启动单节点事务,并在单节点事务上捎带上这个全局事务 ID。所有的读写都是在这些单节点事务中各自完成的。如果在这个阶段出现任何问题(例如,节点崩溃或请求超时),则协调者或任何参与者都可以中止。
-
当应用准备提交时,协调者向所有参与者发送一个准备请求,并打上全局事务 ID 的标记。如果任意一个请求失败或超时,则协调者向所有参与者发送针对该事务 ID 的中止请求。
-
参与者收到准备请求时,需要确保在任意情况下都的确可以提交事务。这包括将所有事务数据写入磁盘(出现故障,电源故障,或硬盘空间不足都不能是稍后拒绝提交的理由)以及检查是否存在任何冲突或违反约束。通过向协调者回答“是”,节点承诺,只要请求,这个事务一定可以不出差错地提交。换句话说,参与者放弃了中止事务的权利,但没有实际提交。
-
当协调者收到所有准备请求的答复时,会就提交或中止事务作出明确的决定(只有在所有参与者投赞成票的情况下才会提交)。协调者必须把这个决定写到磁盘上的事务日志中,如果它随后就崩溃,恢复后也能知道自己所做的决定。这被称为提交点(commit point)。
-
一旦协调者的决定落盘,提交或放弃请求会发送给所有参与者。如果这个请求失败或超时,协调者必须永远保持重试,直到成功为止。没有回头路:如果已经做出决定,不管需要多少次重试它都必须被执行。如果参与者在此期间崩溃,事务将在其恢复后提交,由于参与者投了赞成,因此恢复后它不能拒绝提交。
因此,该协议包含两个关键的“不归路”点:当参与者投票“是”时,它承诺它稍后肯定能够提交(尽管协调者可能仍然选择放弃)。一旦协调者做出决定,这一决定是不可撤销的。这些承诺保证了 2PC 的原子性。(单节点原子提交将这两个事件混为一谈:将提交记录写入事务日志。)
协调者失效
我们已经讨论了在 2PC 期间,如果参与者之一或网络发生故障时会发生什么情况:如果任何一个准备请求失败或者超时,协调者就会中止事务。如果任何提交或中止请求失败,协调者将无条件重试。但是如果协调者崩溃,会发生什么情况就不太清楚了。如果协调者在发送准备请求之前失败,参与者可以安全地中止事务。但是,一旦参与者收到了准备请求并投了“是”,就不能再单方面放弃,必须等待协调者回答事务是否已经提交或中止。如果此时协调者崩溃或网络出现故障,参与者什么也做不了只能等待。参与者的这种事务状态称为存疑(in doubt)的或不确定(uncertain)的。
如下图所示,在这个特定的例子中,协调者实际上决定提交,数据库 2 收到提交请求。但是,协调者在将提交请求发送到数据库 1 之前发生崩溃,因此数据库 1 不知道是否提交或中止。即使超时在这里也没有帮助:如果数据库 1 在超时后单方面中止,它将最终与执行提交的数据库 2 不一致。同样,单方面提交也是不安全的,因为另一个参与者可能已经中止了。

没有协调者的消息,参与者无法知道是提交还是放弃。原则上参与者可以相互沟通,找出每个参与者是如何投票的,并达成一致,但这不是 2PC 协议的一部分。可以完成 2PC 的唯一方法是等待协调者恢复。这就是为什么协调者必须在向参与者发送提交或中止请求之前,将其提交或中止决定写入磁盘上的事务日志:协调者恢复后,通过读取其事务日志来确定所有存疑事务的状态。任何在协调者日志中没有提交记录的事务都会中止。因此,2PC 的提交点归结为协调者上的常规单节点原子提交。
怀疑时持有锁
为什么我们这么关心存疑事务?系统的其他部分就不能继续正常工作,无视那些终将被清理的存疑事务吗?问题在于锁(locking),正如在读已提交中所讨论的那样,数据库事务通常获取待修改的行上的行级排他锁,以防止脏写。此外,如果要使用可序列化的隔离等级,则使用两阶段锁定的数据库也必须为事务所读取的行加上共享锁。
在事务提交或中止之前,数据库不能释放这些锁,因此,在使用两阶段提交时,事务必须在整个存疑期间持有这些锁。如果协调者已经崩溃,需要 20 分钟才能重启,那么这些锁将会被持有 20 分钟。如果协调者的日志由于某种原因彻底丢失,这些锁将被永久持有,或至少在管理员手动解决该情况之前。
当这些锁被持有时,其他事务不能修改这些行。根据数据库的不同,其他事务甚至可能因为读取这些行而被阻塞。因此,其他事务没法儿简单地继续它们的业务了,如果它们要访问同样的数据,就会被阻塞。这可能会导致应用大面积进入不可用状态,直到存疑事务被解决。
从协调者故障中恢复
理论上,如果协调者崩溃并重新启动,它应该干净地从日志中恢复其状态,并解决任何存疑事务。然而在实践中,孤立(orphaned)的存疑事务确实会出现,即无论出于何种理由,协调者无法确定事务的结果(例如事务日志已经由于软件错误丢失或损坏)。这些事务无法自动解决,所以它们永远待在数据库中,持有锁并阻塞其他事务。即使重启数据库服务器也无法解决这个问题,因为在 2PC 的正确实现中,即使重启也必须保留存疑事务的锁(否则就会冒有违反原子性保证的风险)。这是一种棘手的情况。
唯一的出路是让管理员手动决定提交还是回滚事务。管理员必须检查每个存疑事务的参与者,确定是否有任何参与者已经提交或中止,然后将相同的结果应用于其他参与者。解决这个问题潜在地需要大量的人力,并且可能发生在严重的生产中断期间(不然为什么协调者处于这种糟糕的状态),并很可能要在巨大精神压力和时间压力下完成。
许多 XA 的实现都有一个叫做启发式决策(heuristic decistions)的紧急逃生舱口:允许参与者单方面决定放弃或提交一个存疑事务,而无需协调者做出最终决定。要清楚的是,这里启发式是可能破坏原子性(probably breaking atomicity)的委婉说法,因为它违背了两阶段提交的系统承诺。因此,启发式决策只是为了逃出灾难性的情况而准备的,而不是为了日常使用的。
2PC
所谓的两个阶段是指:第一阶段:准备阶段(投票阶段)和第二阶段:提交阶段(执行阶段)。
准备阶段
事务协调者(事务管理器)给每个参与者(资源管理器)发送 Prepare 消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的 redo 和 undo 日志,但不提交,到达一种“万事俱备,只欠东风”的状态。
可以进一步将准备阶段分为以下三个步骤:
1)协调者节点向所有参与者节点询问是否可以执行提交操作(vote),并开始等待各参与者节点的响应。
2)参与者节点执行询问发起为止的所有事务操作,并将 Undo 信息和 Redo 信息写入日志。(注意:若成功这里其实每个参与者已经执行了事务操作)
3)各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则它返回一个”同意”消息;如果参与者节点的事务操作实际执行失败,则它返回一个”中止”消息。
提交阶段
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。(注意:必须在最后阶段释放锁资源)
接下来分两种情况分别讨论提交阶段的过程。


当协调者节点从所有参与者节点获得的相应消息都为”同意”时:
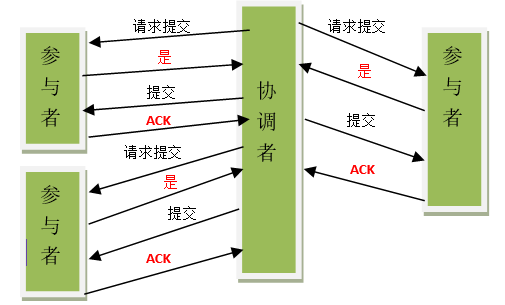
1)协调者节点向所有参与者节点发出”正式提交(commit)”的请求。
2)参与者节点正式完成操作,并释放在整个事务期间内占用的资源。
3)参与者节点向协调者节点发送”完成”消息。
4)协调者节点受到所有参与者节点反馈的”完成”消息后,完成事务。
如果任一参与者节点在第一阶段返回的响应消息为”中止”,或者 协调者节点在第一阶段的询问超时之前无法获取所有参与者节点的响应消息时:
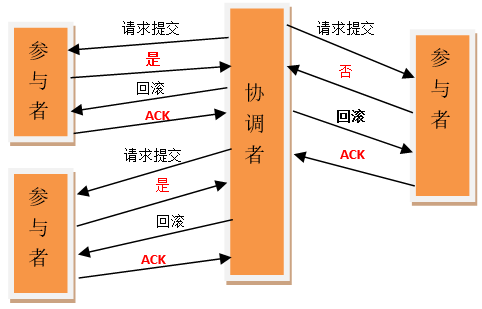
1)协调者节点向所有参与者节点发出”回滚操作(rollback)”的请求。
2)参与者节点利用之前写入的 Undo 信息执行回滚,并释放在整个事务期间内占用的资源。
3)参与者节点向协调者节点发送”回滚完成”消息。
4)协调者节点受到所有参与者节点反馈的”回滚完成”消息后,取消事务。
不管最后结果如何,第二阶段都会结束当前事务。
二阶段提交看起来确实能够提供原子性的操作,但是不幸的事,二阶段提交还是有几个缺点的:
1、同步阻塞的性能问题同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
2、单点故障的可靠性问题。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
3、数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送 commit 请求之后,发生了局部网络异常或者在发送 commit 请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了 commit 请求。而在这部分参与者接到 commit 请求之后就会执行 commit 操作。但是其他部分未接到 commit 请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
4、二阶段无法解决的问题:协调者再发出 commit 消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
由于二阶段提交存在着诸如同步阻塞、单点问题、脑裂等缺陷,所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交。