
常用开发库 - MapStruct 工具库详解
常用开发库 - MapStruct 工具库详解
为什么会引入 MapStruct 这类工具
在开发的时候经常会有业务代码之间有很多的 JavaBean 之间的相互转化,比如 PO/DTO/VO/QueryParam 之间的转换问题。之前我们的做法是:
- 拷贝技术
- org.apache.commons.beanutils.PropertyUtils.copyProperties
- org.apache.commons.beanutils.BeanUtils.copyProperties
- org.springframework.beans.BeanUtils.copyProperties
- net.sf.cglib.beans.BeanCopier
- 纯 get/set
- 辅助 IDE 插件拷贝对象时可以自动 set 所有方法字段 (这种方式可能有些开发人员不清楚)
- 不仅看上去冗余添加新的字段时依然需要手动
- 开发效率比较低
MapStruct 带来的改变
MapSturct 是一个生成类型安全, 高性能且无依赖的 JavaBean 映射代码的注解处理器(annotation processor)。
MapStruct 入门例子
pom.xml
一般来说会加载两个包:
org.mapstruct:mapstruct: 包含 Mapstruct 核心,比如注解等;如果是mapstruct-jdk8会引入一些 jdk8 的语言特性;org.mapstruct:mapstruct-processor: 处理注解用的,可以根据注解自动生成 mapstruct 的 mapperImpl 类
如下示例基于 IDEA 实现,可以在 build 阶段的annotationProcessorPaths中配置mapstruct-processor的 path。
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<org.mapstruct.version>1.4.0.Beta3</org.mapstruct.version>
<org.projectlombok.version>1.18.12</org.projectlombok.version>
</properties>
<dependencies>
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct</artifactId>
<version>${org.mapstruct.version}</version>
</dependency>
<!-- lombok dependencies should not end up on classpath -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${org.projectlombok.version}</version>
<scope>provided</scope>
</dependency>
<!-- fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.71</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<!-- See https://maven.apache.org/plugins/maven-compiler-plugin/compile-mojo.html -->
<!-- Classpath elements to supply as annotation processor path. If specified, the compiler -->
<!-- will detect annotation processors only in those classpath elements. If omitted, the -->
<!-- default classpath is used to detect annotation processors. The detection itself depends -->
<!-- on the configuration of annotationProcessors. -->
<!-- -->
<!-- According to this documentation, the provided dependency processor is not considered! -->
<annotationProcessorPaths>
<path>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>${org.mapstruct.version}</version>
</path>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${org.projectlombok.version}</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
Entity
这里面假设基于一些业务需求采用的是 MySQL,且将一些扩展的数据放在了 config 字段中,并以 JSON 转 String 存储。
@Data
@Accessors(chain = true)
public class User {
private Long id;
private String username;
private String password; // 密码
private Integer sex; // 性别
private LocalDate birthday; // 生日
private LocalDateTime createTime; // 创建时间
private String config; // 其他扩展信息,以JSON格式存储
}
@Data
@Accessors(chain = true)
public class UserVo {
private Long id;
private String username;
private String password;
private Integer gender;
private LocalDate birthday;
private String createTime;
private List<UserConfig> config;
@Data
public static class UserConfig {
private String field1;
private Integer field2;
}
}
@Mapper
public interface UserConverter {
UserConverter INSTANCE = Mappers.getMapper(UserConverter.class);
@Mapping(target = "gender", source = "sex")
@Mapping(target = "createTime", dateFormat = "yyyy-MM-dd HH:mm:ss")
UserVo do2vo(User var1);
@Mapping(target = "sex", source = "gender")
@Mapping(target = "password", ignore = true)
@Mapping(target = "createTime", dateFormat = "yyyy-MM-dd HH:mm:ss")
User vo2Do(UserVo var1);
List<UserVo> do2voList(List<User> userList);
default List<UserVo.UserConfig> strConfigToListUserConfig(String config) {
return JSON.parseArray(config, UserVo.UserConfig.class);
}
default String listUserConfigToStrConfig(List<UserVo.UserConfig> list) {
return JSON.toJSONString(list);
}
}
@Test
public void do2VoTest() {
User user = new User()
.setId(1L)
.setUsername("zhangsan")
.setSex(1)
.setPassword("abc123")
.setCreateTime(LocalDateTime.now())
.setBirthday(LocalDate.of(1999, 9, 27))
.setConfig("[{\"field1\":\"Test Field1\",\"field2\":500}]");
UserVo userVo = UserConverter.INSTANCE.do2vo(user);
// asset
assertNotNull(userVo);
assertEquals(userVo.getId(), user.getId());
// print
System.out.println(user);
System.out.println(userVo);
// User(id=1, username=zhangsan, password=abc123, sex=1, birthday=1999-09-27, createTime=2020-08-17T14:54:01.528, config=[{"field1":"Test Field1","field2":500}])
// UserVo(id=1, username=zhangsan, password=abc123, gender=1, birthday=1999-09-27, createTime=2020-08-17 14:54:01, config=[UserVo.UserConfig(field1=Test Field1, field2=500)])
}
@Test
public void vo2DoTest() {
UserVo.UserConfig userConfig = new UserVo.UserConfig();
userConfig.setField1("Test Field1");
userConfig.setField2(500);
UserVo userVo = new UserVo()
.setId(1L)
.setUsername("zhangsan")
.setGender(2)
.setCreateTime("2020-01-18 15:32:54")
.setBirthday(LocalDate.of(1999, 9, 27))
.setConfig(Collections.singletonList(userConfig));
User user = UserConverter.INSTANCE.vo2Do(userVo);
// asset
assertNotNull(userVo);
assertEquals(userVo.getId(), user.getId());
// print
System.out.println(user);
System.out.println(userVo);
}
MapStrcut 实现的原理?
MapStruct 来生成的代码, 其类似于人手写。 速度上可以得到保证。前面例子中生成的代码可以在编译后看到, 在 target/generated-sources/annotations 里可以看到; 同时真正在代码包执行的可以在 target/classes 包中看到。
编译后的类
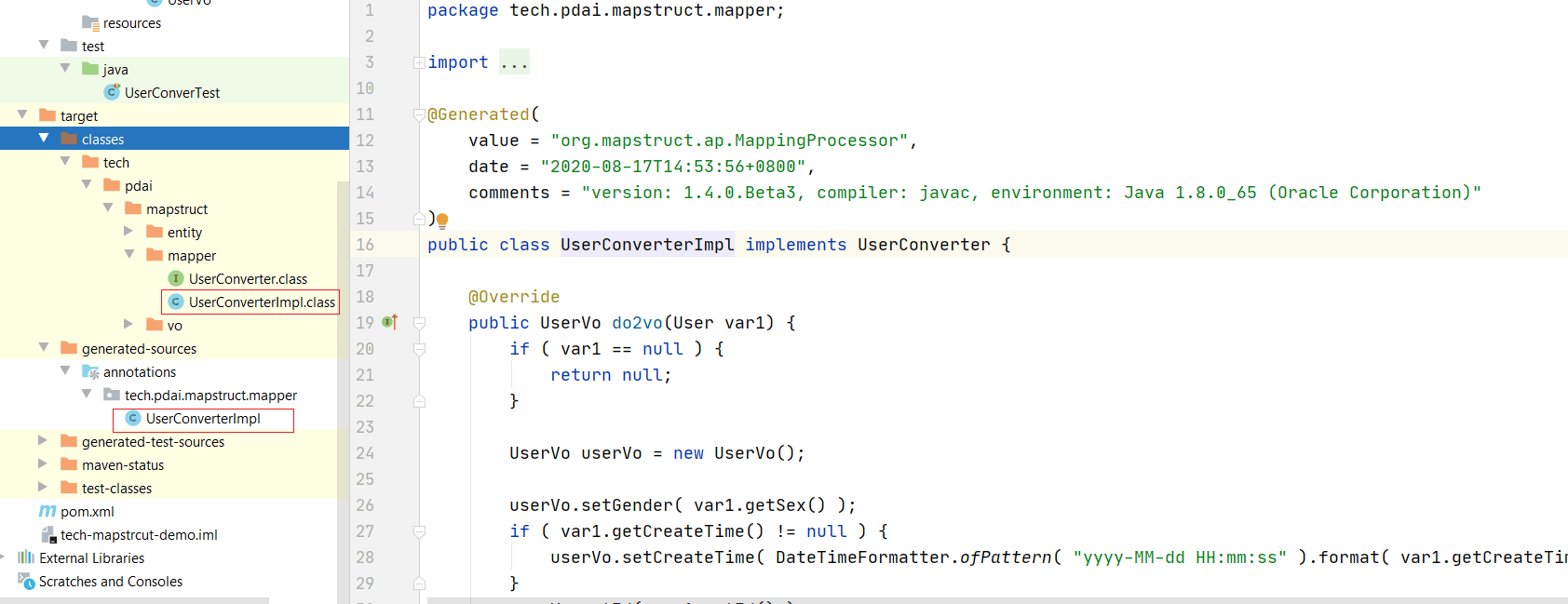
public class UserConverterImpl implements UserConverter {
@Override
public UserVo do2vo(User var1) {
if ( var1 == null ) {
return null;
}
UserVo userVo = new UserVo();
userVo.setGender( var1.getSex() );
if ( var1.getCreateTime() != null ) {
userVo.setCreateTime( DateTimeFormatter.ofPattern( "yyyy-MM-dd HH:mm:ss" ).format( var1.getCreateTime() ) );
}
userVo.setId( var1.getId() );
userVo.setUsername( var1.getUsername() );
userVo.setPassword( var1.getPassword() );
userVo.setBirthday( var1.getBirthday() );
userVo.setConfig( strConfigToListUserConfig( var1.getConfig() ) );
return userVo;
}
@Override
public User vo2Do(UserVo var1) {
if ( var1 == null ) {
return null;
}
User user = new User();
user.setSex( var1.getGender() );
if ( var1.getCreateTime() != null ) {
user.setCreateTime( LocalDateTime.parse( var1.getCreateTime(), DateTimeFormatter.ofPattern( "yyyy-MM-dd HH:mm:ss" ) ) );
}
user.setId( var1.getId() );
user.setUsername( var1.getUsername() );
user.setBirthday( var1.getBirthday() );
user.setConfig( listUserConfigToStrConfig( var1.getConfig() ) );
return user;
}
@Override
public List<UserVo> do2voList(List<User> userList) {
if ( userList == null ) {
return null;
}
List<UserVo> list = new ArrayList<UserVo>( userList.size() );
for ( User user : userList ) {
list.add( do2vo( user ) );
}
return list;
}
}
这里面用了什么机制?
核心之处就是对于注解的解析上。JDK5 引入了注解的同时,也提供了两种解析方式。
- 运行时解析
运行时能够解析的注解,必须将@Retention 设置为 RUNTIME, 比如@Retention(RetentionPolicy.RUNTIME),这样就可以通过反射拿到该注解。java.lang,reflect 反射包中提供了一个接口 AnnotatedElement,该接口定义了获取注解信息的几个方法,Class、Constructor、Field、Method、Package 等都实现了该接口,对反射熟悉的朋友应该都会很熟悉这种解析方式。
- 编译时解析
编译时解析有两种机制,分别简单描述下:
1)Annotation Processing Tool
apt 自 JDK5 产生,JDK7 已标记为过期,不推荐使用,JDK8 中已彻底删除,自 JDK6 开始,可以使用 Pluggable Annotation Processing API 来替换它,apt 被替换主要有 2 点原因:
- api 都在 com.sun.mirror 非标准包下
- 没有集成到 javac 中,需要额外运行
2)Pluggable Annotation Processing API
JSR 269: Pluggable Annotation Processing API 在新窗口打开自 JDK6 加入,作为 apt 的替代方案,它解决了 apt 的两个问题,javac 在执行的时候会调用实现了该 API 的程序,这样我们就可以对编译器做一些增强,这时 javac 执行的过程如下:

Lombok 本质上就是一个实现了“JSR 269 API”的程序。在使用 javac 的过程中,它产生作用的具体流程如下:
- javac 对源代码进行分析,生成了一棵抽象语法树(AST)
- 运行过程中调用实现了“JSR 269 API”的 Lombok 程序
- 此时 Lombok 就对第一步骤得到的 AST 进行处理,找到@Data 注解所在类对应的语法树(AST),然后修改该语法树(AST),增加 getter 和 setter 方法定义的相应树节点
- javac 使用修改后的抽象语法树(AST)生成字节码文件,即给 class 增加新的节点(代码块)
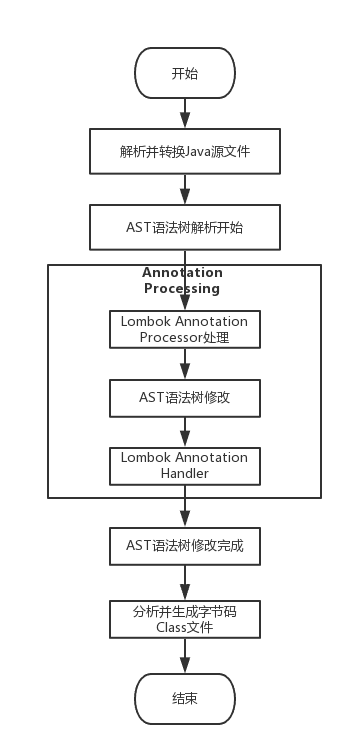
从上面的 Lombok 执行的流程图中可以看出,在 Javac 解析成 AST 抽象语法树之后, Lombok 根据自己编写的注解处理器,动态地修改 AST,增加新的节点(即 Lombok 自定义注解所需要生成的代码),最终通过分析生成 JVM 可执行的字节码 Class 文件。使用 Annotation Processing 自定义注解是在编译阶段进行修改,而 JDK 的反射技术是在运行时动态修改,两者相比,反射虽然更加灵活一些但是带来的性能损耗更加大。