
volatile
volatile
在多线程并发编程中,volatile 可以看做轻量级的 synchronized,它在多处理器开发中保证了共享变量的“可见性”。可见性的意思是当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。如果 volatile 变量修饰符使用恰当的话,它比 synchronized 的使用和执行成本更低,因为它不会引起线程上下文的切换和调度。volatile 变量具备以下特征:
- 可见性,对于 volatile 变量的读,线程总是能读到当前最新的 volatile 值,也就是任一线程对 volatile 变量的写入对其余线程都是立即可见;
- 有序性,禁止编译器和处理器为了提高性能而进行指令重排序;
- 基本不保证原子性,由于存在 long/double 非原子性协议,long/double 在 32 位 x86 的 hotspot 虚拟机下允许没有被 volatile 修饰的变量读写操作划分为两次进行。但是从 JDK9 开始,hotspot 也明确约束所有数据类型访问保持原子性,所以 volatile 变量保证原子性可以基本忽略。
在实际的编程中,要注意,除非是在保证仅有一个线程处于写,而其他线程处于读的状态下的时候,才可以使用 volatile 来保证可见性,而不需要使用原子变量或者锁来保证原子性。
volatile 示例
JVM 中每一个变量都有一个主内存,为了保证最佳性能,JVM 允许线程从主内存拷贝一份私有拷贝,然后在线程读取变量的时候从主内存里面读,退出的时候,将修改的值同步到主内存。形象而言,对于变量 t,A 线程对 t 变量修改的值,对 B 线程是可见的。但是 A 获取到 t 的值加 1 之后,突然挂起了,B 获取到的值还是最新的值,volatile 能保证 B 能获取到的 t 是最新的值,因为 A 的 t+1 并没有写到主内存里面去。
public class VolatileTest {
public static volatile int race = 0;
public static int value = 0;
public static void increase() {
race++;
value++;
}
private static final int THREAD_COUNT = 20;
public static void main(String[] args) {
Thread[] threads = new Thread[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
increase();
}
});
threads[i].start();
}
while (Thread.activeCount()> 1) {
Thread.yield();
}
System.out.println("race: " + race + " value: " + value);
}
}
volatile 实现原理
在 Java 内存模型中,通过 as-if-serial 和 happens-before(先行先发生) 来保证从重排的正确性,同时对于 volatile 变量有特殊的规则:对一个变量的写操作先行发生于后面对这个变量的读操作,保证了 volatile 变量的可见性;也就是说 JMM 保证新值能马上同步到主内存,同时把其他线程的工作内存中对应的变量副本置为无效,以及每次使用前立即从主内存读取共享变量。
instance = new Singleton(); // instance是volatile变量
0x01a3de1d: movb $0×0,0×1104800(%esi);0x01a3de24: lock addl $0×0,(%esp);
将带有 volatile 变量操作的 Java 代码转换成汇编代码后,可以看到多了个 lock 前缀指令;这个 lock 指令是关键,在多核处理器下实现两个重要操作:
- 将当前处理器缓存行的数据写回到系统内存。
- 这个写回内存的操作会使其他处理器里缓存该内存地址的数据失效
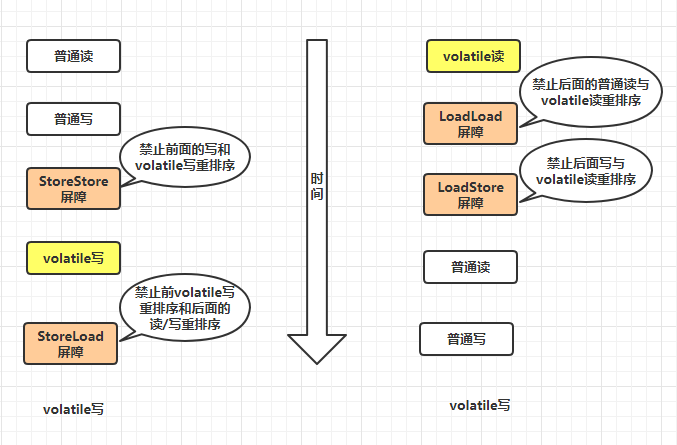
该操作主要基于内存模型中的内存屏障来实现;如上图所示,在 Java 内存模型中,主要有以下 4 种类型的内存屏障:
- LoadLoad 屏障:对于 Load1,LoadLoad,Load2 这样的语句,在 Load2 及后续读取操作前要保证 Load1 要读取的数据读取完毕;
- LoadStore 屏障:对于 Load1,LoadStore,Store2 这样的语句,在 Store2 及后续写入操作前要保证 Load1 要读取的数据读取完毕;
- StoreStore 屏障:对于 Store1,StoreStore,Store2 这样的语句,在 Store2 及后续写入操作前要保证 Store1 的写入操作对其他处理器可见;
- StoreLoad 屏障:对于 Store1,StoreLoad,Load2 这样的语句,在 Load2 及后续读取操作前,Store1 的写入对所有处理器可见。
Java 的内存屏障与我们在《Concurrent-Notes》中讨论的读写屏障的关系如下:
- 写屏障与(StoreStore、StoreLoad)屏障的关系:在 volatile 变量写之前加入 StoreSore 屏障保证了 volatile 写之前,写缓冲器中的内容已全部刷回告诉缓存,防止前面的写操作和 volatile 写操作之间发生指令重排,在 volatile 写之后加入 StoreLoad 屏障,保证了后面的读/写操作与 volatile 写操作发生指令重排,所以写屏障同时具有 StoreStore 与 StoreLoad 的功能。
- 读屏障与(LoadLoad、LoadStore)屏障的关系:在 volatile 变量读之后加入 LoadLoad 屏障保证了后面其他读操作的无效队列中无效消息已经被刷回到了高速缓存,在 volatile 变量读操作后加入 LoadStore 屏障,保证了后面其他写操作的无效队列中无效消息已经被刷回高速缓存。读屏障同时具有了 LoadLoad,LoadStore 的功能。
缓存行与 volatile 优化
Doug lea 在 JDK 7 的并发包里新增一个队列集合类 LinkedTransferQueue,它在使用 volatile 变量时,用一种追加字节的方式来优化队列出队和入队的性能。LinkedTransferQueue 的代码如下。
/** 队列中的头部节点 */
private transient final PaddedAtomicReference < QNode > head;
/** 队列中的尾部节点 */
private transient final PaddedAtomicReference < QNode > tail;
static final class PaddedAtomicReference < T > extends AtomicReference T > {
// 使用很多4个字节的引用追加到64个字节
Object p0,
p1,
p2,
p3,
p4,
p5,
p6,
p7,
p8,
p9,
pa,
pb,
pc,
pd,
pe;
PaddedAtomicReference(T r) {
super(r);
}
}
public class AtomicReference <
V > implements java.io.Serializable {
private volatile V value;
// 省略其他代码
}
追加字节能优化性能?这种方式看起来很神奇,但如果深入理解处理器架构就能理解其中的奥秘。让我们先来看看 LinkedTransferQueue 这个类,它使用一个内部类类型来定义队列的头节点(head)和尾节点(tail),而这个内部类 PaddedAtomicReference 相对于父类 AtomicReference 只做了一件事情,就是将共享变量追加到 64 字节。我们可以来计算下,一个对象的引用占 4 个字节,它追加了 15 个变量(共占 60 个字节),再加上父类的 value 变量,一共 64 个字节。
为什么追加 64 字节能够提高并发编程的效率呢?因为对于英特尔酷睿 i7、酷睿、Atom 和 NetBurst,以及 Core Solo 和 Pentium M 处理器的 L1、L2 或 L3 缓存的高速缓存行是 64 个字节宽,不支持部分填充缓存行,这意味着,如果队列的头节点和尾节点都不足 64 字节的话,处理器会将它们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同样的头、尾节点,当一个处理器试图修改头节点时,会将整个缓存行锁定,那么在缓存一致性机制的作用下,会导致其他处理器不能访问自己高速缓存中的尾节点,而队列的入队和出队操作则需要不停修改头节点和尾节点,所以在多处理器的情况下将会严重影响到队列的入队和出队效率。Douglea 使用追加到 64 字节的方式来填满高速缓冲区的缓存行,避免头节点和尾节点加载到同一个缓存行,使头、尾节点在修改时不会互相锁定。
那么是不是在使用 volatile 变量时都应该追加到 64 字节呢?不是的。在两种场景下不应该使用这种方式。
- 缓存行非 64 字节宽的处理器。如 P6 系列和奔腾处理器,它们的 L1 和 L2 高速缓存行是 32 个字节宽。
- 共享变量不会被频繁地写。因为使用追加字节的方式需要处理器读取更多的字节到高速缓冲区,这本身就会带来一定的性能消耗,如果共享变量不被频繁写的话,锁的几率也非常小,就没必要通过追加字节的方式来避免相互锁定。
不过这种追加字节的方式在 Java 7 下可能不生效,因为 Java 7 变得更加智慧,它会淘汰或重新排列无用字段,需要使用其他追加字节的方式