
JDK 7 与 JDK 8 对比
ConcurrentHashMap JDK 7 与 JDK 8 对比
CHM in JDK 7
JDK 7 版 CHM 使用 Segment 与 HashEntry 两种数据结构,示意图如下。
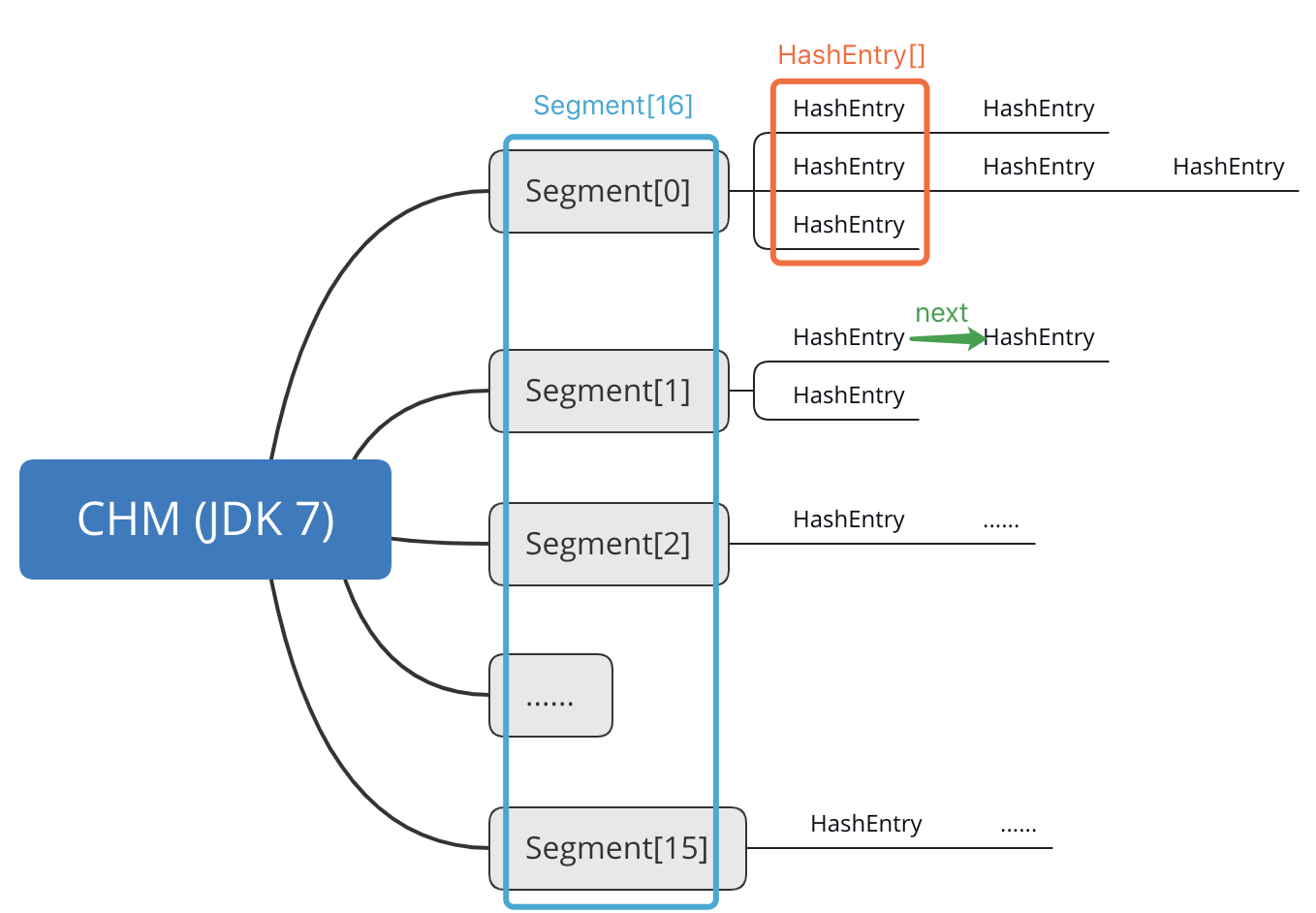
可见,整个 CHM 存储空间被划分成 16 个 Segment,每个 Segment 内又包含 0 到多个 HashEntry 的单链表(有一个 HashEntry 数组存储链表头节点),每个链表就是一个哈希桶。HashEntry 内存储具体的键值及哈希码。
Segment 内部类继承自 ReentrantLock,因此习惯将 JDK 7 CHM 的这种思路称作“锁分段技术”:在 CHM 内数据分布均匀的情况下,每一把 Segment 锁只会负责 1/16 部分数据的同步。当多线程同时写入 CHM 时(读取不用加锁),如果数据落到不同的 Segment 上,就不会造成锁的竞争,提升了并发访问的效率。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
具体的插入过程就不提了,注意区分插入的桶位置存在与不存在 HashEntry(即是否发生了哈希冲突)的两种情况,以及头插法、扩容操作就行,下面看看与锁相关的部分。线程进入 put()方法时,会首先调用 ReentrantLock.tryLock()方法试图获取锁。如果未能获取到锁(被其他线程持有中),就调用 scanAndLockForPut()方法,其源码如下。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
可见是自旋执行 tryLock()方法获取锁,最多会重试 MAX_SCAN_RETRIES(多核环境下为 64)次。如果重试达到上限还未成功,就直接调用 lock()方法阻塞,等待锁被其他线程释放。注意在重试的最后会检测对应的 HashEntry 是否发生了变化,如果变化了,会重新开始自旋。
本线程插入完毕之后,调用 ReentrantLock.unlock()方法释放锁,同时唤醒 AQS 队列中阻塞着的下一个线程(如果有的话)进行插入操作,执行完毕。
CHM in JDK 8
JDK 8 版 CHM 使用与 HashMap 相同的数据结构,即哈希桶数组(Node[])+链表或红黑树,示意图如下。
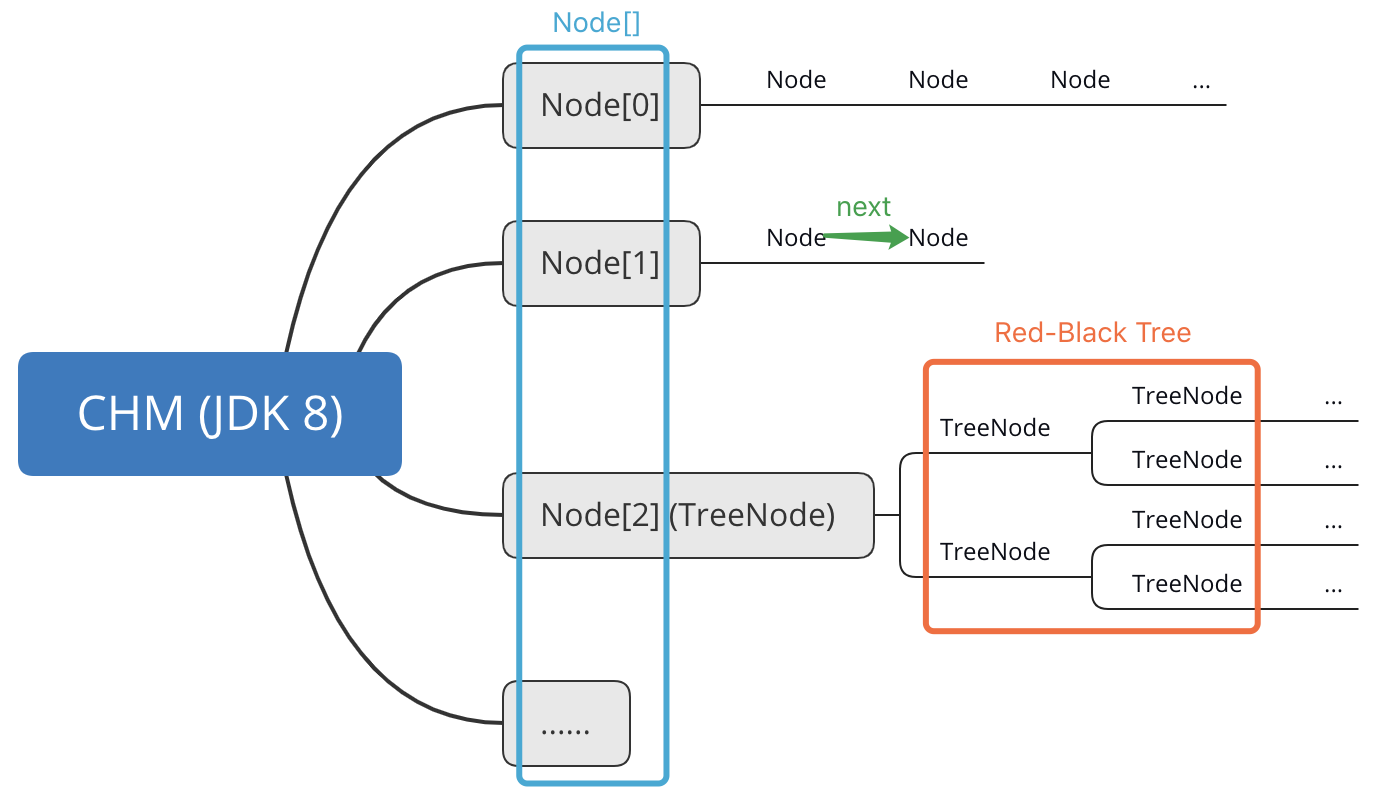
虽然 JDK 8 的 CHM 源码里还保留着 Segment 的定义,但已经不再使用了。以下则是插入数据的核心方法 putVal()的源码。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
该方法的步骤简述如下:
- 计算 key 的哈希码;
- 检查哈希桶数组是否为空,若为空,调用 initTable()方法初始化;
- 调用 tabAt()方法获得哈希码对应到哈希桶数组的下标,并获取该桶的头结点 f;
- 若 f 为空(即为空桶),调用 casTabAt()方法,通过 CAS 操作(Unsafe.compareAndSwapObject())将新元素插入为头节点。若 CAS 失败,说明有并发操作,重试之;
- 若 f 不为空,但是其 hash 值为 MOVED(即-1),说明其他线程触发了扩容操作,调用 helpTransfer()方法参与扩容;
- 若均不符合 4 和 5 步骤的条件,说明可以正常插入,用 synchronized 关键字在 f 上加锁,并在对应桶的链表或红黑树上插入新元素;
- 最后判断是否要将链表转换为红黑树,如果需要,调用 treeifyBin()方法转换之。
通过上面的分析,我们可以总结出,JDK 8 的 CHM 用 CAS 和 synchronized 替代了 JDK 7 中的分段 ReentrantLock。这种切换带来的好处是:
-
锁分离的粒度细化了,从 Segment 级别细化到了哈希桶级别。也就是说,在插入元素不发生哈希冲突的情况下,就不必加锁。
-
在插入桶的头结点时使用无锁的 CAS 操作,效率很高。
-
虽然我们也可以让 Node 类继承 ReentrantLock 并执行 f.lock()/unlock()操作,但从 JDK 6 开始,JVM 对内置的 synchronized 关键字做了大量优化,synchronized 不再是重量级锁的代名词,而是会由无锁状态开始,随着并发程度的提升而膨胀成偏向锁、轻量级锁,再到重量级锁(其中包含适应性自旋过程)。在锁粒度细化的前提下,发生争用的概率降低,synchronized 膨胀成重量级锁的机会也不多,故可以省去线程被挂起和唤醒(上下文切换)的大量开销。