
20.V8 引擎
剖析 V8 引擎
引擎与运行时:代码解析与执行
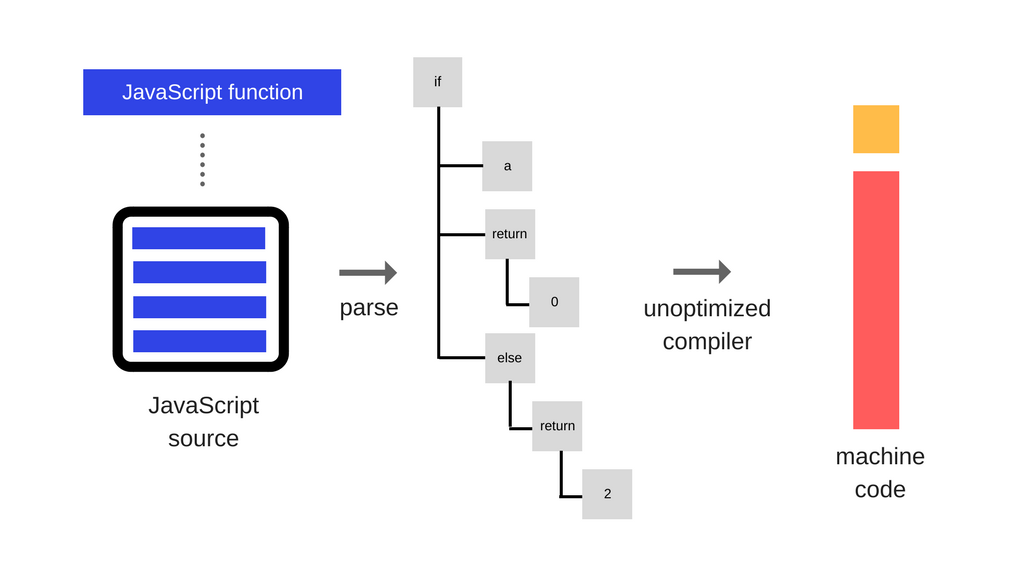
JavaScript 是典型的解释型语言,其需要运行在某个容器内:该容器首先将 JavaScript 代码转化为可执行的命令(语法解析以及 JIT),然后注入某些全局变量以允许 JavaScript 与外部进行交互。所谓的 JavaScript 引擎(Engine )就是负责解析与编译,将 JavaScript 脚本转化为机器理解的命令;而 JavaScript 运行时(Runtime )这是提供了程序运行期间能够访问的内建库。譬如在浏览器中运行的代码,能够访问 Window 对象或者 DOM API,其就是由浏览器的 JavaScript 运行时提供的。而 Node.js 提供的运行时则包含了不同的库,譬如 Cluster 或者文件系统接口等等。所有的运行时都会包含基础的数据类型以及常见的 Console 对象这样的工具库。我们可以认为 Chrome 与 Node.js 共用相同的 Google V8 引擎,而拥有不同的运行时。
这篇文章对于 V8 的工作原理有非常不错的讲解

$ out/Debug/d8 --print-ast add.js
…
--- AST ---
FUNC at 12
. KIND 0
. SUSPEND COUNT 0
. NAME "add"
. PARAMS
. . VAR (0x7fbd5e818210) (mode = VAR) "x"
. . VAR (0x7fbd5e818240) (mode = VAR) "y"
. RETURN at 23
. . ADD at 32
. . . VAR PROXY parameter[0] (0x7fbd5e818210) (mode = VAR) "x"
. . . VAR PROXY parameter[1] (0x7fbd5e818240) (mode = VAR) "y"

$ out/Debug/d8 --print-bytecode add.js
…
[generated bytecode for function: add]
Parameter count 3
Frame size 0
12 E> 0x37738712a02a @ 0 : 94 StackCheck
23 S> 0x37738712a02b @ 1 : 1d 02 Ldar a1
32 E> 0x37738712a02d @ 3 : 29 03 00 Add a0, [0]
36 S> 0x37738712a030 @ 6 : 98 Return
Constant pool (size = 0)
Handler Table (size = 16)
JIT
优化器
作为解释型语言,JavaScript 的性能一直是其瓶颈之一。Google 在 2009 年在 V8 中引入了 JIT 技术 (Just in time compiling ), JavaScript 瞬间提升了 20 - 40 倍的速度。JIT 基于运行期分析编译,而 Javascript 是一个没有类型的语言,于是,大部分时间,JIT 编译器其实是在猜测 Javascript 中的类型,举个例子:
function add (a, b) { return a+b}
const c = add (1 + 2);
// 编译为
function add (int a, int b) { return a + b;} // a, b 被确定为 int 类型
// 有的开发者会做
const d = add ("hello", "world");
这种情况下,JIT 编译器只能推倒重来。JIT 带来的性能提升,有时候还没有这个重编的开销大,Optimization killers · petkaantonov/bluebird Wiki · GitHub。事实上,大部分时间 JIT 都不会生成优化代码,有字节码的,直接字节码,没有字节码的,粗粗编译下就结了,因为 JIT 自己也需要时间,除非是一个函数被使用过很多遍,否则不会被编译成机器码,因为编译花的时间可能比直接跑字节码还多。
语法增强
类型转换
Webpack、Fuse、Rollup、Browserify
静态类型
Modern JavaScript Development Glossary
JavaScript was created in 1995 by Brendan Eich with the objective to be a language which designers could easily implement dynamic interfaces, in other words, it wasn’t built to be fast; it was created to add behavior layer on HTML pages comfortably and straightforwardly.
Engine is a program that converts Javascript code into lower level or machine code that microprocessors can understand.
Engine & Runtime: Code Parse, Compile and Execution
After loading, the source code will be transformed into a tree representation called Abstract Syntax Tree or AST. Then, depending on the engine/operational system/platform, either a baseline version of this code is compiled, or a bytecode is created to be interpreted.
JIT
Initially, JavaScript was an interpreted language, making the startup phase faster because the interpreter only needs to read the first instruction, translate it into bytecode and run it right away. For the 90’s internet needs, JavaScript did its job very well. The problem lies when applications start to be more complex.
In the decade of 2000, technologies like Ajax made web applications been more dynamic, Gmail in 2004 and Google Maps in 2005 was a trending on this use case of Ajax technology. This new “way” of building web applications end up with more logic written on the client side. In 2008 with the appearance of Google and it’s engine V8 which compiled all JavaScript code into bytecode right away.
In computing, just-in-time (JIT) compilation, also known as dynamic translation, is a way of executing computer code that involves compilation during execution of a program – at run time – rather than prior to execution.
Most often this consists of source code or more commonly bytecode translation to machine code, which is then executed directly. A system implementing a JIT compiler typically continuously analyses the code being executed and identifies parts of the code where the speedup gained from compilation or recompilation would outweigh the overhead of compiling that code.
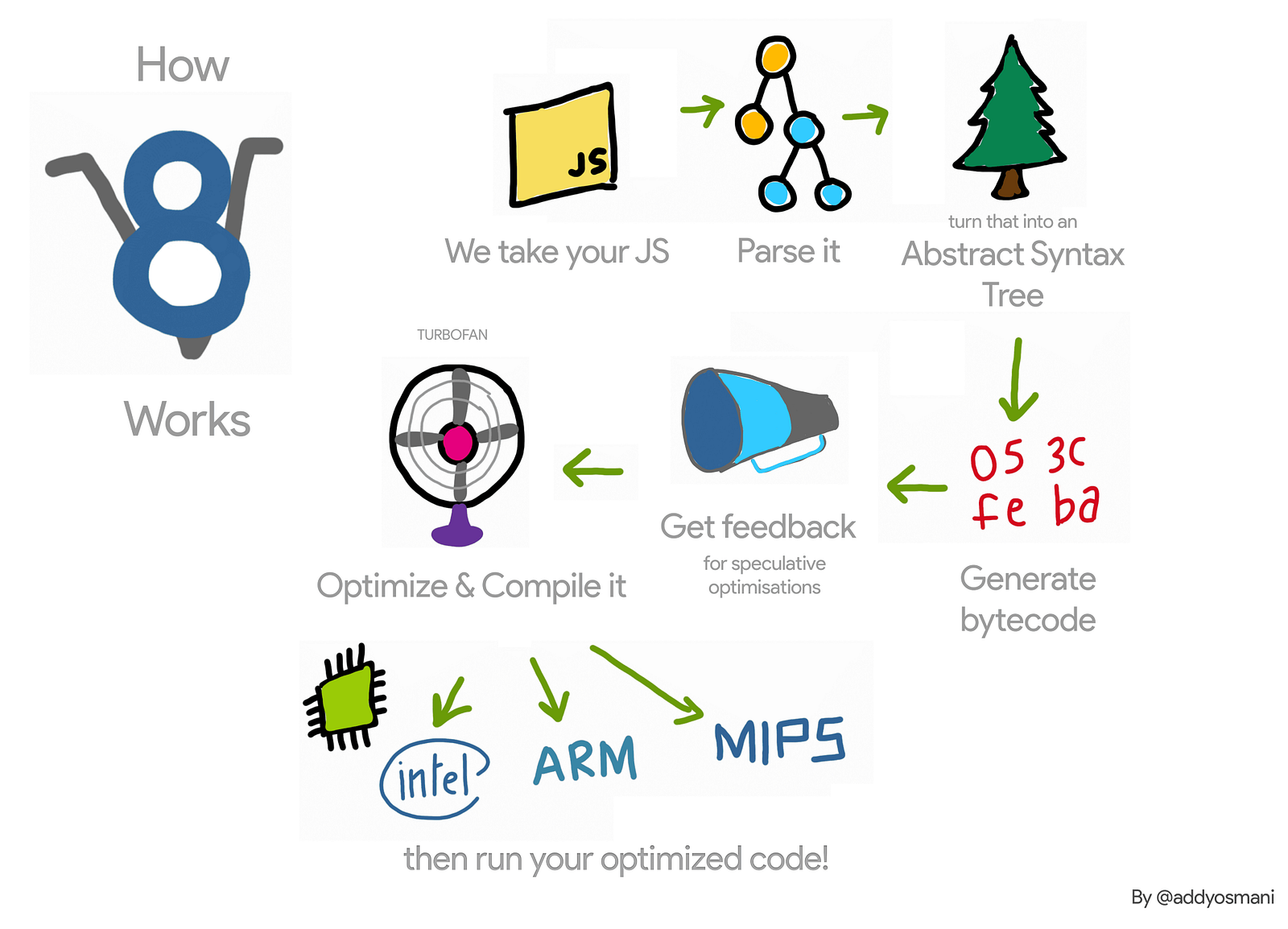
In summary, the phases of JIT compiler could be described as:
-
Parse
-
Compile
-
Optimize/deoptimize
-
Execution
-
Garbage Collector
The following is great example of JIT phases on V8 by Addy Osmani:
The Profiler
The Profiler is another entity to be observed, which monitors and collect code execution data. I’ll describe it in summary how it works, taking into account that are differences among browsers engines.
At the first time, everything passes through the interpreter; this process guarantees that the code runs faster after AST is generated. When a piece of code is executed multiple times, as our getNextState() function, the interpreter loses his performance since it needs to interpret the same piece of code over and over again, when this happens, the profiler marks this piece of code as warm and baseline compiler comes to action.
We will use the following snippet to illustrate how JIT works:
function sum(x, y) {
return x + y;
}
[1, 2, 3, 4, 5, "6", 7, 8, 9, 10].reduce((prev, curr) => sum(prev, curr), 0);
When profiler marks a piece of code as warm, the JIT sends this code to the baseline compiler, which creates a stub for this part of code while the profiler keeps collecting data regarding the frequency and types used on this code section (among other data). When this code section is executed (on our hypothetical example return x + y;), the JIT only needs to take this compiled piece again. When a warm code is called several times in the same manner (like same types), it’s marked as hot.
Optimizer Compiler
JIT 本身并不能带来必然的性能优化
The optimizer compiler generates an even faster version of this code, which is marked as hot. It is only possible based on some assumptions that the optimizer compiler makes like the type of the variables or the shape of objects used in this code. On our example, we can say that a hot code of return x + y; will assume that both x and y are typed as anumber.
The problem is when this code has been hit with something not expected by this optimized compiler, in our case the sum(15, ‘6’) call, since y is a string. When this happens, the Profiler assumes that its assumptions were wrong throwing everything out returning to the base compiled (or interpreted) version again. This phase is called deoptimization. Sometimes this happens so often that it makes the optimized version slower than using the base compiled code.