
网卡设备
网卡设备
主流的数据中心基本上开始提供 10GbE 甚至 25GbE 的网络。为什么会变成这样?我们做一个简单的算术题就知道了。根据 Cisco 的文档介绍,一块千兆网卡的吞吐大概是: [1,000,000,000 b/s / (84 B * 8 b/B)] == 1,488,096 f/s (maximum rate)。那么万兆网卡的吞吐大概是它的十倍,也就是差不多每秒 1488 万帧,处理一个包的时间在百纳秒的级别,基本相当于一个 L2 Cache Miss 的时间。所以如何减小内核协议栈处理带来的内核-用户态频繁内存拷贝的开销,成为一个很重要的课题,这就是为什么现在很多高性能网络程序开始基于 DPDK 进行开发。
DPDK
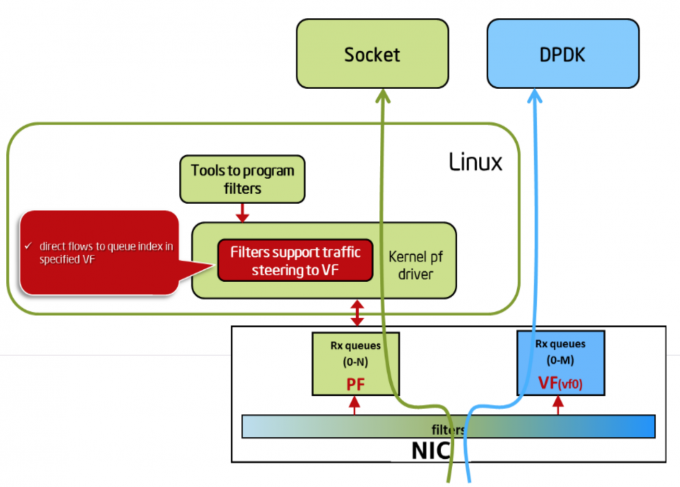
从上图可以看到,数据包直接从网卡到了 DPDK,绕过了操作系统的内核驱动、协议栈和 Socket Library。DPDK 内部维护了一个叫做 UIO Framework 的用户态驱动 (PMD),通过 ring queue 等技术实现内核到用户态的 zero-copy 数据交换,避免了 Syscall 和内核切换带来的 cache miss,而且在多核架构上通过多线程和绑核,极大提升了报文处理效率。如果你确定你的网络程序瓶颈在包处理效率上,不妨关注一下 DPDK。
另外 RDMA 对未来体系结构的影响也会很大,它会让一个分布式集群向一个超级 NUMA 的架构演进(它的通信延时/带宽已经跟现在 NUMA 架构中连接不同 socket node 的 QPI 的延时/带宽在一个量级),但是目前受限于成本和开发模型的变化,可能还需要等很长一段时间才能普及。