
特征降维
特征降纬
维度变换是将现有数据降低到更小的维度,尽量保证数据信息的完整性。楼主将介绍常用的几种有损失的维度变换方法,将大大地提高实践中建模的效率:
-
主成分分析(PCA)和因子分析(FA):PCA 通过空间映射的方式,将当前维度映射到更低的维度,使得每个变量在新空间的方差最大。FA 则是找到当前特征向量的公因子(维度更小),用公因子的线性组合来描述当前的特征向量。
-
奇异值分解(SVD):SVD 的降维可解释性较低,且计算量比 PCA 大,一般用在稀疏矩阵上降维,例如图片压缩,推荐系统。
-
聚类:将某一类具有相似性的特征聚到单个变量,从而大大降低维度。
-
线性组合:将多个变量做线性回归,根据每个变量的表决系数,赋予变量权重,可将该类变量根据权重组合成一个变量。
-
流行学习:流行学习中一些复杂的非线性方法,可参考 skearn:LLE Example
Dimensionality Reduction(降维)

Like clustering methods, dimensionality reduction seek and exploit the inherent structure in the data, but in this case in an unsupervised manner or order to summarise or describe data using less information.
This can be useful to visualize dimensional data or to simplify data which can then be used in a supervized learning method. Many of these methods can be adapted for use in classification and regression.
- Principal Component Analysis (PCA)
- Principal Component Regression (PCR)
- Partial Least Squares Regression (PLSR)
- Sammon Mapping
- Multidimensional Scaling (MDS)
- Projection Pursuit
- Linear Discriminant Analysis (LDA)
- Mixture Discriminant Analysis (MDA)
- Quadratic Discriminant Analysis (QDA)
- Flexible Discriminant Analysis (FDA)
降维的必要性:
1.多重共线性–预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。2.高维空间本身具有稀疏性。一维正态分布有 68%的值落于正负标准差之间,而在十维空间上只有 0.02%。3.过多的变量会妨碍查找规律的建立。4.仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。 降维的目的:1.减少预测变量的个数 2.确保这些变量是相互独立的 3.提供一个框架来解释结果 降维的方法有:主成分分析、因子分析、用户自定义复合等。
数据的向量表示
一般情况下,在数据挖掘和机器学习中,数据被表示为向量。例如某个淘宝店 2012 年全年的流量及交易情况可以看成一组记录的集合,其中每一天的数据是一条记录,格式如下: (日期, 浏览量, 访客数, 下单数, 成交数, 成交金额) 其中“日期”是一个记录标志而非度量值,而数据挖掘关心的大多是度量值,因此如果我们忽略日期这个字段后,我们得到一组记录,每条记录可以被表示为一个五维向量,其中一条看起来大约是这个样子: $ (500,240,25,13,2312.15)^T $ 注意这里我用了转置,因为习惯上使用列向量表示一条记录(后面会看到原因),本文后面也会遵循这个准则。不过为了方便有时我会省略转置符号,但我们说到向量默认都是指列向量。 我们当然可以对这一组五维向量进行分析和挖掘,不过我们知道,很多机器学习算法的复杂度和数据的维数有着密切关系,甚至与维数呈 指数级关联。当然,这里区区五维的数据,也许还无所谓,但是实际机器学习中处理成千上万甚至几十万维的情况也并不罕见,在这种情况下,机器学习的资源消耗 是不可接受的,因此我们必须对数据进行降维。 降维当然意味着信息的丢失,不过鉴于实际数据本身常常存在的相关性,我们可以想办法在降维的同时将信息的损失尽量降低。 举个例子,假如某学籍数据有两列 M 和 F,其中 M 列的取值是如何此学生为男性取值 1,为女性取值 0;而 F 列是学生为女性取值 1,男 性取值 0。此时如果我们统计全部学籍数据,会发现对于任何一条记录来说,当 M 为 1 时 F 必定为 0,反之当 M 为 0 时 F 必定为 1。在这种情况下,我们将 M 或 F 去 掉实际上没有任何信息的损失,因为只要保留一列就可以完全还原另一列。 当然上面是一个极端的情况,在现实中也许不会出现,不过类似的情况还是很常见的。例如上面淘宝店铺的数据,从经验我们可以知道,“浏览量”和“访客数”往往具有较强的相关关系,而“下单数”和“成交数”也具有较强的相关关系。这里我们非正式的使用“相关关系”这个词,可以直观理解 为“当某一天这个店铺的浏览量较高(或较低)时,我们应该很大程度上认为这天的访客数也较高(或较低)”。后面的章节中我们会给出相关性的严格数学定义。 这种情况表明,如果我们删除浏览量或访客数其中一个指标,我们应该期待并不会丢失太多信息。因此我们可以删除一个,以降低机器学习算法的复杂度。 上面给出的是降维的朴素思想描述,可以有助于直观理解降维的动机和可行性,但并不具有操作指导意义。例如,我们到底删除哪一列损 失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始 数据决定具体的降维操作步骤? 要回答上面的问题,就要对降维问题进行数学化和形式化的讨论。而 PCA 是一种具有严格数学基础并且已被广泛采用的降维方法。下面我不会直接描述 PCA,而是通过逐步分析问题,让我们一起重新“发明”一遍 PCA。
向量的表示及基变换
内积与投影
两个维数相同的向量的内积被定义为:
$$ (a_1,a_2,\cdots,a_n)^{T}\cdot (b_1,b_2,\cdots,b_n)^{T}=a_1b_1+a_2b_2+\cdots+a_nb_n $$
内积运算将两个向量映射为一个实数。其计算方式非常容易理解,但是其意义并不明显。下面我们分析内积的几何意义。假设 A 和 B 是两个 n 维向量,我们知道 n 维向量可以等价表示为 n 维空间中的一条从原点发射的有向线段,为了简单起见我们假设 A 和 B 均为二维向量,则 A=(x_1,y_1),B=(x_2,y_2)。则在二维平面上 A 和 B 可以用两条发自原点的有向线段表示,见下图:
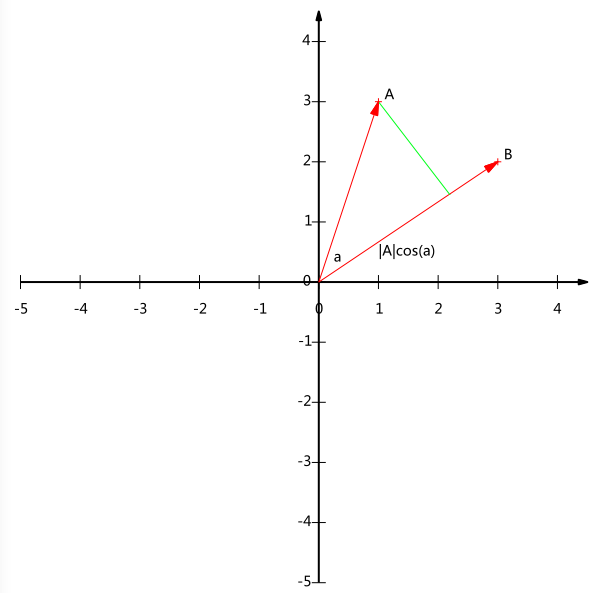
现在事情似乎是有点眉目了:A 与 B 的内积等于 A 到 B 的投影长度乘以 B 的模。再进一步,如果我们假设 B 的模为 1,即让|B|=1,那么就变成了: $A\cdot B=|A|cos(a)$ 也就是说,设向量 B 的模为 1,则 A 与 B 的内积值等于 A 向 B 所在直线投影的矢量长度!这就是内积的一种几何解释,也是我们得到的第一个重要结论。在后面的推导中,将反复使用这个结论。
基
一个二维向量可以对应二维笛卡尔直角坐标系中从原点出发的一个有向线段。例如下面这个向量:
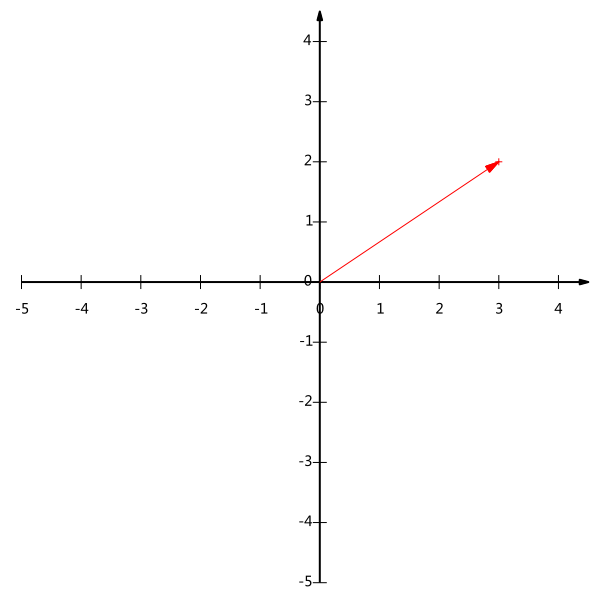
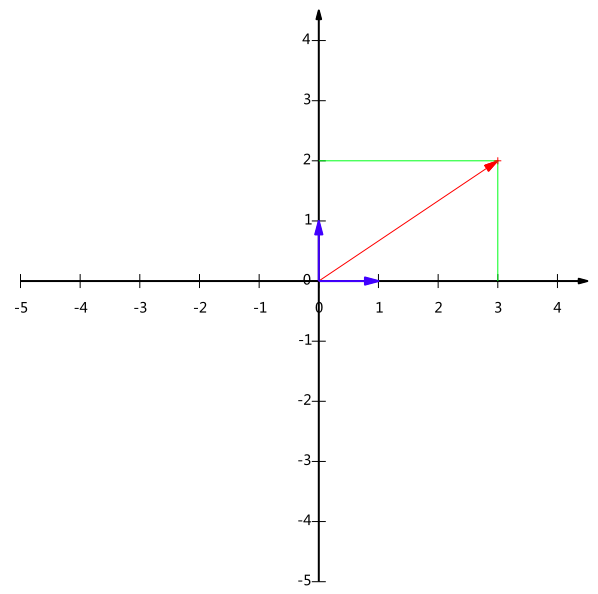
不难证明所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。
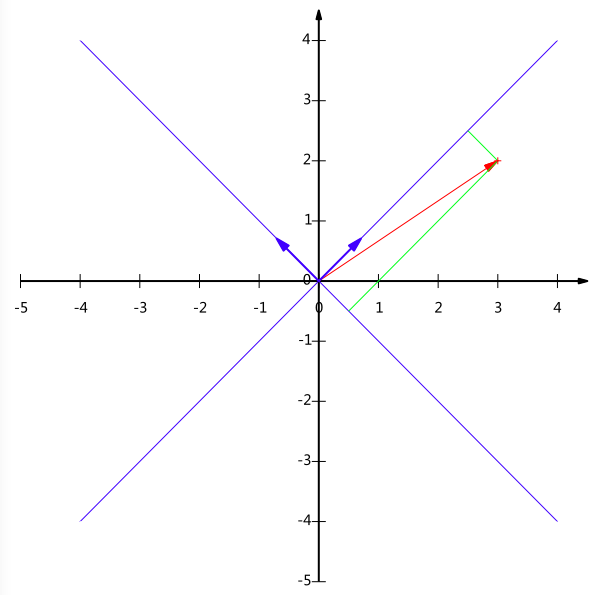
基变换的矩阵表示
下面我们找一种简便的方式来表示基变换。还是拿上面的例子,想一下,将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个 新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:
$$ \begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 3 \ 2 \end{pmatrix} = \begin{pmatrix} 5/\sqrt{2} \ -1/\sqrt{2} \end{pmatrix} $$
太漂亮了!其中矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标。可以稍微推广一下,如果我们有 m 个二维向量,只要 将二维向量按列排成一个两行 m 列矩阵,然后用“基矩阵”乘以这个矩阵,就得到了所有这些向量在新基下的值。例如(1,1),(2,2),(3,3),想变 换到刚才那组基上,则可以这样表示:
$$ \begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \ 1 & 2 & 3 \end{pmatrix} = \begin{pmatrix} 2/\sqrt{2} & 4/\sqrt{2} & 6/\sqrt{2} \ 0 & 0 & 0 \end{pmatrix} $$
aj 于是一组向量的基变换被干净的表示为矩阵的相乘。 一般的,如果我们有 M 个 N 维向量,想将其变换为由 R 个 N 维向量表示的新空间中,那么首先将 R 个基按行组成矩阵 A,然后将向量按列组成矩阵 B,那么两矩阵的乘积 AB 就是变换结果,其中 AB 的第 m 列为 A 中第 m 列变换后的结果。 数学表示为:
$$ \begin{pmatrix} p_1 \ p_2 \ \vdots \ p_R \end{pmatrix} \begin{pmatrix} a_1 & a_2 & \cdots & a_M \end{pmatrix} = \begin{pmatrix} p_1a_1 & p_1a_2 & \cdots & p_1a_M \ p_2a_1 & p_2a_2 & \cdots & p_2a_M \ \vdots & \vdots & \ddots & \vdots \ p_Ra_1 & p_Ra_2 & \cdots & p_Ra_M \end{pmatrix} $$
(1124213344) 其中$p_i $是一个行向量,表示第 i 个基,$a_j$是一个列向量,表示第 j 个原始数据记录。 特别要注意的是,这里 R 可以小于 N,而 R 决定了变换后数据的维数。也就是说,我们可以将一 N 维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示降维变换。 最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。很多同学在学线性代数时对矩阵相乘的方法感到奇怪,但是如果明白了矩阵相乘的物理意义,其合理性就一目了然了。
协方差矩阵及优化目标
上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但 是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组 N 维向量,现在要将其降到 K 维(K 小于 N),那么我们应该如何选择 K 个基才能最大程度保留原有的信息? 要完全数学化这个问题非常繁杂,这里我们用一种非形式化的直观方法来看这个问题。 为了避免过于抽象的讨论,我们仍以一个具体的例子展开。假设我们的数据由五条记录组成,将它们表示成矩阵形式:
$$ \begin{pmatrix} 1 & 1 & 2 & 4 & 2 \ 1 & 3 & 3 & 4 & 4 \end{pmatrix} $$
其中每一列为一条数据记录,而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为 0(这样做的道理和好处后面会看到)。 我们看上面的数据,第一个字段均值为 2,第二个字段均值为 3,所以变换后:
$$ \begin{pmatrix} -1 & -1 & 0 & 2 & 0 \ -2 & 0 & 0 & 1 & 1 \end{pmatrix} $$
方差
上文说到,我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。此处,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即: $Var(a)=\frac{1}{m}\sum_{i=1}^m{(a_i-\mu)^2}$ X=(a1a2⋯amb1b2⋯bm) 由于上面我们已经将每个字段的均值都化为 0 了,因此方差可以直接用每个元素的平方和除以元素个数表示: $Var(a)=\frac{1}{m}\sum_{i=1}^m{a_i^2}$ 1mXXT=(1m∑i=1mai21m∑i=1maibi1m∑i=1maibi1m∑i=1mbi2) 于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
协方差
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。 如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因 此,应该有其他约束条件。从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完 全独立,必然存在重复表示的信息。 数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为 0,则: $Cov(a,b)=\frac{1}{m}\sum_{i=1}^m{a_ib_i}$ D=1mYYT=1m(PX)(PX)T=1mPXXTPT=P(1mXXT)PT=PCPT 可以看到,在字段均值为 0 的情况下,两个字段的协方差简洁的表示为其内积除以元素数 m。 当协方差为 0 时,表示两个字段完全独立。为了让协方差为 0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。 至此,我们得到了降维问题的优化目标:将一组 N 维向量降为 K 维(K 大于 0,小于 N),其目标是选择 K 个单位(模为 1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为 0,而字段的方差则尽可能大(在正交的约束下,取最大的 K 个方差)。
协方差矩阵
上面我们导出了优化目标,但是这个目标似乎不能直接作为操作指南(或者说算法),因为它只说要什么,但根本没有说怎么做。所以我们要继续在数学上研究计算方案。 我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是我们来了灵感: 假设我们只有 a 和 b 两个字段,那么我们将它们按行组成矩阵 X: $X=\begin{pmatrix} a_1 & a_2 & \cdots & a_m \ b_1 & b_2 & \cdots & b_m \end{pmatrix}$ (e1e2⋯en) 然后我们用 X 乘以 X 的转置,并乘上系数 1/m: $\frac{1}{m}XX^\mathsf{T}=\begin{pmatrix} \frac{1}{m}\sum_{i=1}^m{a_i^2} & \frac{1}{m}\sum_{i=1}^m{a_ib_i} \ \frac{1}{m}\sum_{i=1}^m{a_ib_i} & \frac{1}{m}\sum_{i=1}^m{b_i^2} \end{pmatrix}$ (λ1λ2⋱λn) 奇迹出现了!这个矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是 a 和 b 的协方差。两者被统一到了一个矩阵的。 根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况: 设我们有 m 个 n 维数据记录,将其按列排成 n 乘 m 的矩阵 X,设 C=\frac{1}{m}XX^\mathsf{T},则 C 是一个对称矩阵,其对角线分别个各个字段的方差,而第 i 行 j 列和 j 行 i 列元素相同,表示 i 和 j 两个字段的协方差。
协方差矩阵对角化
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为 0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系: 设原始数据矩阵 X 对应的协方差矩阵为 C,而 P 是一组基按行组成的矩阵,设 Y=PX,则 Y 为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D,我们推导一下 D 与 C 的关系: \begin{array}{l l l} D & = & \frac{1}{m}YY^\mathsf{T} \ & = & \frac{1}{m}(PX)(PX)^\mathsf{T} \ & = & \frac{1}{m}PXX^\mathsf{T}P^\mathsf{T} \ & = & P(\frac{1}{m}XX^\mathsf{T})P^\mathsf{T} \ & = & PCP^\mathsf{T} \end{array} 现在事情很明白了!我们要找的 P 不是别的,而是能让原始协方差矩阵对角化的 P。换句话说,优化目标变成了寻找一个矩阵 P,满足 PCP^\mathsf{T}是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基,用 P 的前 K 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 K 维并满足上述优化条件。 至此,我们离“发明”PCA 还有仅一步之遥! 现在所有焦点都聚焦在了协方差矩阵对角化问题上,有时,我们真应该感谢数学家的先行,因为矩阵对角化在线性代数领域已经属于被玩烂了的东西,所以这在数学上根本不是问题。 由上文知道,协方差矩阵 C 是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:1)实对称矩阵不同特征值对应的特征向量必然正交。2)设特征向量\lambda 重数为 r,则必然存在 r 个线性无关的特征向量对应于\lambda,因此可以将这 r 个特征向量单位正交化。 由上面两条可知,一个 n 行 n 列的实对称矩阵一定可以找到 n 个单位正交特征向量,设这 n 个特征向量为 e_1,e_2,\cdots,e_n,我们将其按列组成矩阵: E=\begin{pmatrix} e_1 & e_2 & \cdots & e_n \end{pmatrix} 则对协方差矩阵 C 有如下结论: E^\mathsf{T}CE=\Lambda=\begin{pmatrix} \lambda_1 & & & \ & \lambda_2 & & \ & & \ddots & \ & & & \lambda_n \end{pmatrix} 其中\Lambda 为对角矩阵,其对角元素为各特征向量对应的特征值(可能有重复)。 以上结论不再给出严格的数学证明,对证明感兴趣的朋友可以参考线性代数书籍关于“实对称矩阵对角化”的内容。 到这里,我们发现我们已经找到了需要的矩阵 P: P=E^\mathsf{T} P 是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是 C 的一个特征向量。如果设 P 按照\Lambda 中特征值的从大到小,将特征向量从上到下排列,则用 P 的前 K 行组成的矩阵乘以原始数据矩阵 X,就得到了我们需要的降维后的数据矩阵 Y。 至此我们完成了整个 PCA 的数学原理讨论。在下面的一节,我们将给出 PCA 的一个实例。