
框架对比
Google 的 Drapper
Dapper 是 Google 生产环境下的分布式跟踪系统,Dapper 有三个设计目标:
- 低消耗:跟踪系统对在线服务的影响应该做到足够小。
- 应用级的透明:对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统显然是侵入性太强的。
- 延展性:Google 至少在未来几年的服务和集群的规模,监控系统都应该能完全把控住。
Drapper 的日志格式,用 span 来表示一个服务调用开始和结束的时间,也就是时间区间。Dapper 记录了 span 的名称以及每个 span 的 ID 和父 ID,如果一个 span 没有父 ID 被称之为 root span。所有的 span 都挂在一个特定的 trace 上,共用一个 traceID,这些 ID 用全局 64 位整数标示。

Drapper 如何进行跟踪收集:

分为 3 个阶段:各个服务将 span 数据写到本机日志上;Dapper 守护进程进行拉取,将数据读到 dapper 收集器里;Dapper 收集器将结果写到 bigtable 中,一次跟踪被记录为一行。
淘宝的鹰眼
关于淘宝的鹰眼系统,主要资料来自于内部分享,

鹰眼埋点和生成日志:

如何抓取和存储日志:
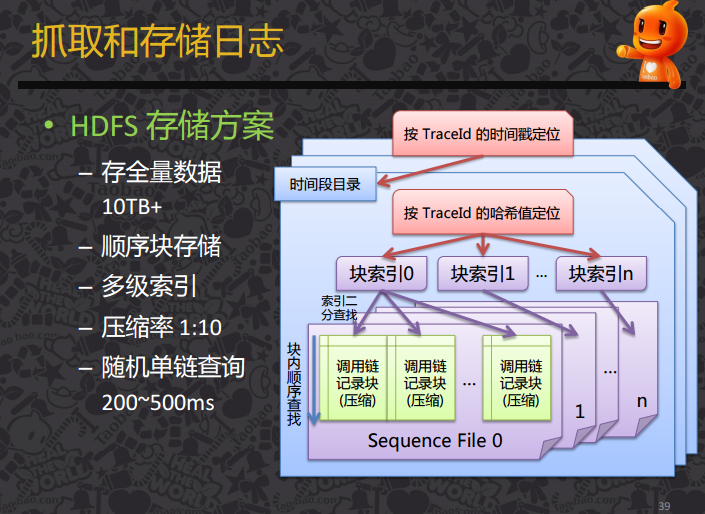
鹰眼的实现小结:
