
InnoDB 架构概览
MySQL Innodb 存储引擎详解
InnoDB 是事务安全的存储引擎,设计上借鉴了很多 Oracle 的架构思想,一般而言,在 OLTP 应用中,InnoDB 应该作为核心应用表的首先存储引擎。InnoDB 是由第三方的 Innobase Oy 公司开发,现已被 Oracle 收购,创始人是 Heikki Tuuri,芬兰赫尔辛基人,和著名的 Linux 创始人 Linus 是校友。
InnoDB 的整体架构分为两个部分:内存架构和磁盘架构,如图:
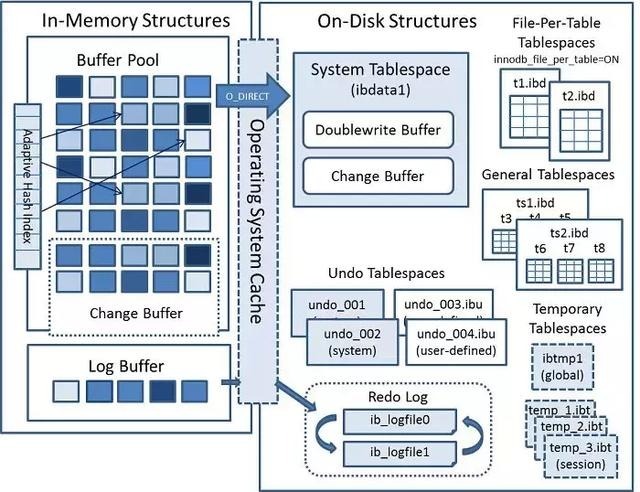
Memory Architecture | 内存架构
InnoDB 的内存主要有以下几个部分组成:缓冲池 (buffer pool)、重做日志缓冲池(Redo Log buffer)以及额外的内存池(additional memory pool),如下图所示:
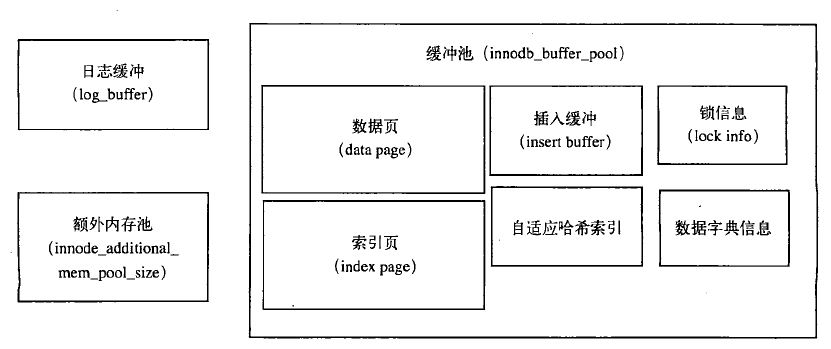
其中缓冲池占最大块内存,用来缓存各自数据,数据文件按页(每页 16K)读取到缓冲池,按最近最少使用算法(LRU)保留缓存数据。缓冲池缓冲的数据类型有:数据页、索引页、插入缓冲、自适应哈希索引、锁信息、数据字典信息等,其中数据页和索引页占了绝大部分内存。日志缓冲将重做日志信息先放入这个缓冲区,然后按一定频率(默认为 1s)将其刷新至重做日志文件。
InnoDB 通过一些列后台线程将相关操作进行异步处理,同时借助缓冲池来减小 CPU 和磁盘速度上的差异。当查询的时候会先通过索引定位到对应的数据页,然后检测数据页是否在缓冲池内,如果在就直接返回,如果不在就去聚簇索引中通过磁盘 IO 读取对应的数据页并放入缓冲池。一个数据页会包含多个数据行。缓存池通过 LRU 算法对数据页进行管理,也就是最频繁使用的数据页排在列表前面,不经常使用的排在队尾,当缓冲池满了的时候会淘汰掉队尾的数据页。从磁盘新读取到的数据页并不会放在队列头部而是放在中间位置,这个中间位置可以通过参数进行修。缓冲池也可以设置多个实例,数据页根据哈希算法决定放在哪个缓冲池。
Storage Architecture | 存储结构
InnoDB 存储引擎的逻辑存储结构和 Oracle 大致相同,所有数据都被逻辑地存放在一个空间中,我们称之为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block),1 extent = 64 pages,InnoDB 存储引擎的逻辑存储结构大致如图所示:
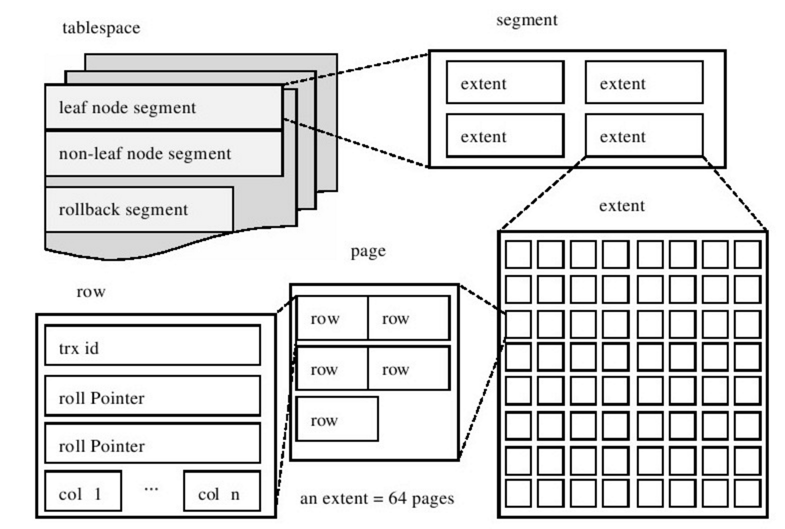
表空间作为存储结构的最高层,所有数据都存放在表空间中,默认情况下用一个共享表空间 ibdata1,如果开启了 innodb_file_per_table 则每张表的数据将存储在单独的表空间中,也就是每张表都会有一个文件,
表空间由各个段构成,InnoDB 存储引擎由索引组织的,而索引中的叶子节点用来记录数据,存储在数据段,而非叶子节点用来构建索引,存储在索引段。区是由连续的页组成,任何情况下一个区都是 1MB,一个区中可以有多个页,每个页默认为 16KB,所以默认情况下一个区中可以包含 64 个连续的页,页的大小是可以通过 innodb_page_size 设置,页中存储的是具体的行记录。一行记录最终以二进制的方式存储在文件里。
从物理意义上来看,InnoDB 表由共享表空间、日志文件组(更准确地说,应该是 Redo 文件组)、表结构定义文件组成。若将 innodb_file_per_table 设置为 on,则每个表将独立地产生一个表空间文件,以 ibd 结尾,数据、索引、表的内部数据字典信息都将保存在这个单独的表空间文件中。表结构定义文件以 frm 结尾,这个是与存储引擎无关的,任何存储引擎的表结构定义文件都一样,为 .frm 文件。
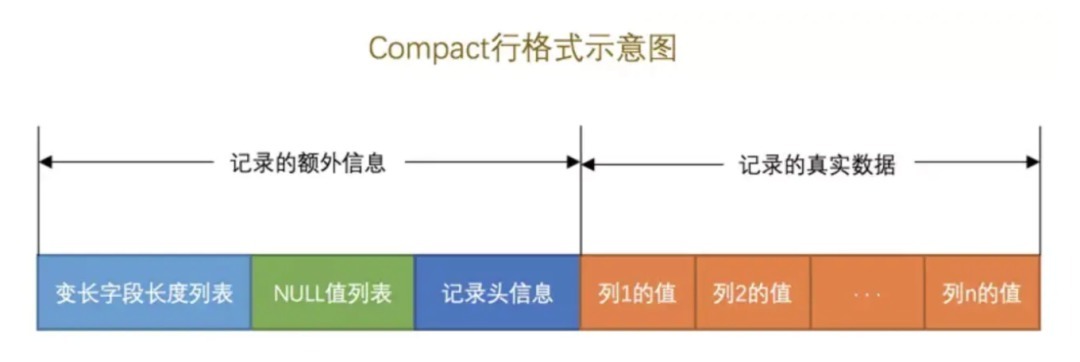
行存储
InnoDB 引擎是面向行存储的,数据都是存储在磁盘的数据页中,数据页里面按照固定的行格式存储着每一行数据。行格式主要分为四种类型 Compact、Redundant、Dynamic 和 Compressed,默认为 Compact 格式。
磁盘预读机制和局部性原理
当计算机访问一个数据时,不仅会加载当前数据所在的数据页,还会将当前数据页相邻的数据页一同加载到内存,磁盘预读的长度一般为页的整倍数,从而有效降低磁盘 IO 的次数。
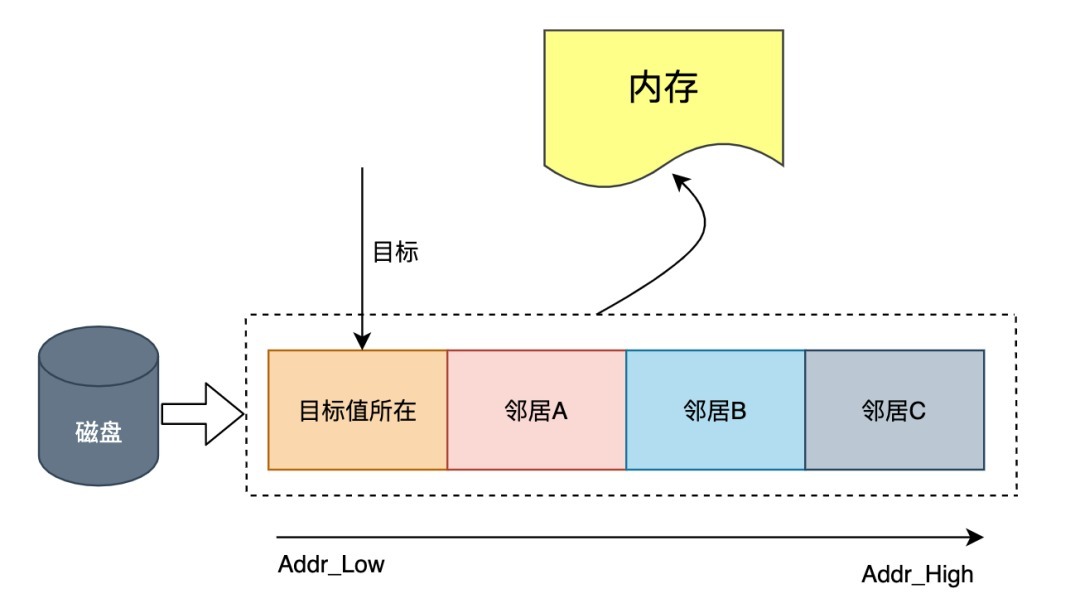
磁盘和内存的交互
MySQL 中磁盘的数据需要被交换到内存,才能完成一次 SQL 交互,大致如图:
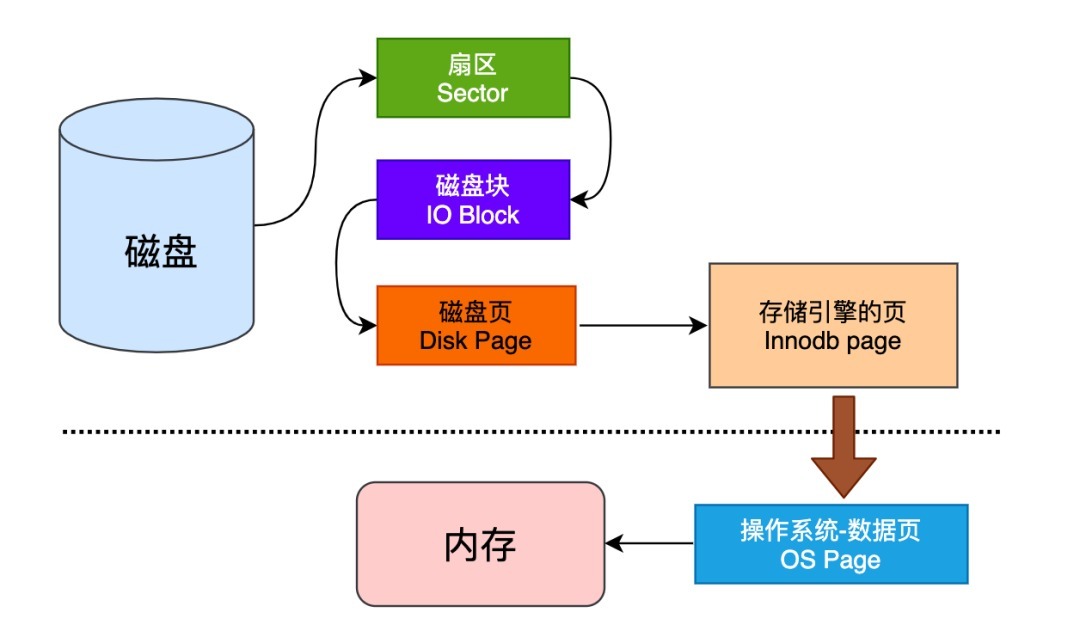
- 扇区是硬盘的读写的基本单位,通常情况下每个扇区的大小是 512B
- 磁盘块文件系统读写数据的最小单位,相邻的扇区组合在一起形成一个块,一般是 4KB
- 页是内存的最小存储单位,页的大小通常为磁盘块大小的 2^n 倍
- InnoDB 页面的默认大小是 16KB,是数倍个操作系统的页
随机磁盘 IO
MySQL 的数据是一行行存储在磁盘上的,并且这些数据并非物理连续地存储,这样的话要查找数据就无法避免随机在磁盘上读取和写入数据。对于 MySQL 来说,当出现大量磁盘随机 IO 时,大部分时间都被浪费到寻道上,磁盘呼噜呼噜转,就是传输不了多少数据。
一次磁盘访问由三个动作组成:
- 寻道:磁头移动定位到指定磁道
- 旋转:等待指定扇区从磁头下旋转经过
- 数据传输:数据在磁盘与内存之间的实际传输
对于存储引擎来说,如何有效降低随机 IO 是个非常重要的问题。
Process Architecture | 进程架构
默认情况下,InnoDB 的后台线程有 7 个,其中 4 个 IO thread, 1 个 Master thread, 1 个 Lock monitor thread, 一个 Error monitor thread。InnoDB 的主要工作都是在一个单独的 Master 线程里完成的。Master 线程的优先级最高,它主要分为以下几个循环:主循环(loop)、后台循环(background loop)、刷新循环(flush loop)、暂停循环(suspend loop)。
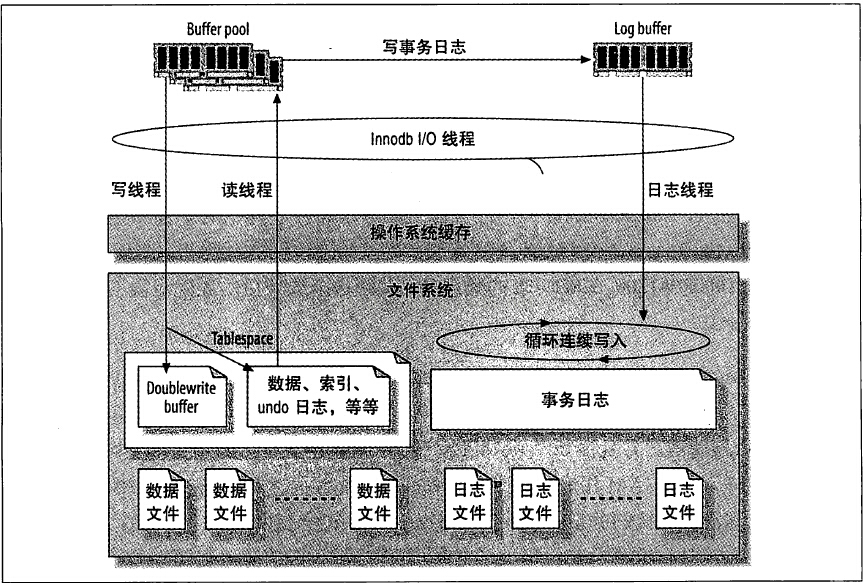
其中主循环的伪代码如下:
void master_thread() (
loop:
for (int i =0; i <10; i++){
do thing once per second
sleep 1 second if necessary
}
do things once per ten seconds
goto loop;
}
- 其中每秒一次的操作包括:刷新日志缓冲区(总是),合并插入缓冲(可能),至多刷新 100 个脏数据页(可能),如果没有当前用户活动,切换至 background loop(可能)。
- 其中每 10 秒一次的操作包括:合并至多 5 个插入缓冲(总是),刷新日志缓冲(总是),刷新 100 个或 10 个脏页到磁盘(总是),产生一个检查点(总是),删除无用 Undo 页(总是)。
- 后台循环,若当前没有用户活动或数据库关闭时,会切换至该循环执行以下操作:删除无用的 undo 页(总是),合并 20 个插入缓冲(总是),跳回到主循环(总是),不断刷新 100 个页,直到符合条件跳转到 flush loop(可能)。
- 如果 flush loop 中也没有什么事情可做,边切换到 suspend loop,将 master 线程挂起。