
05.索引
索引实现分类
从索引的实现上,我们可以将其分为聚集索引与非聚集索引,或称辅助索引或二级索引,这两大类;从索引的实际应用中,又可以细分为普通索引、唯一索引、主键索引、联合索引、外键索引、全文索引这几种。
聚集索引与非聚集索引
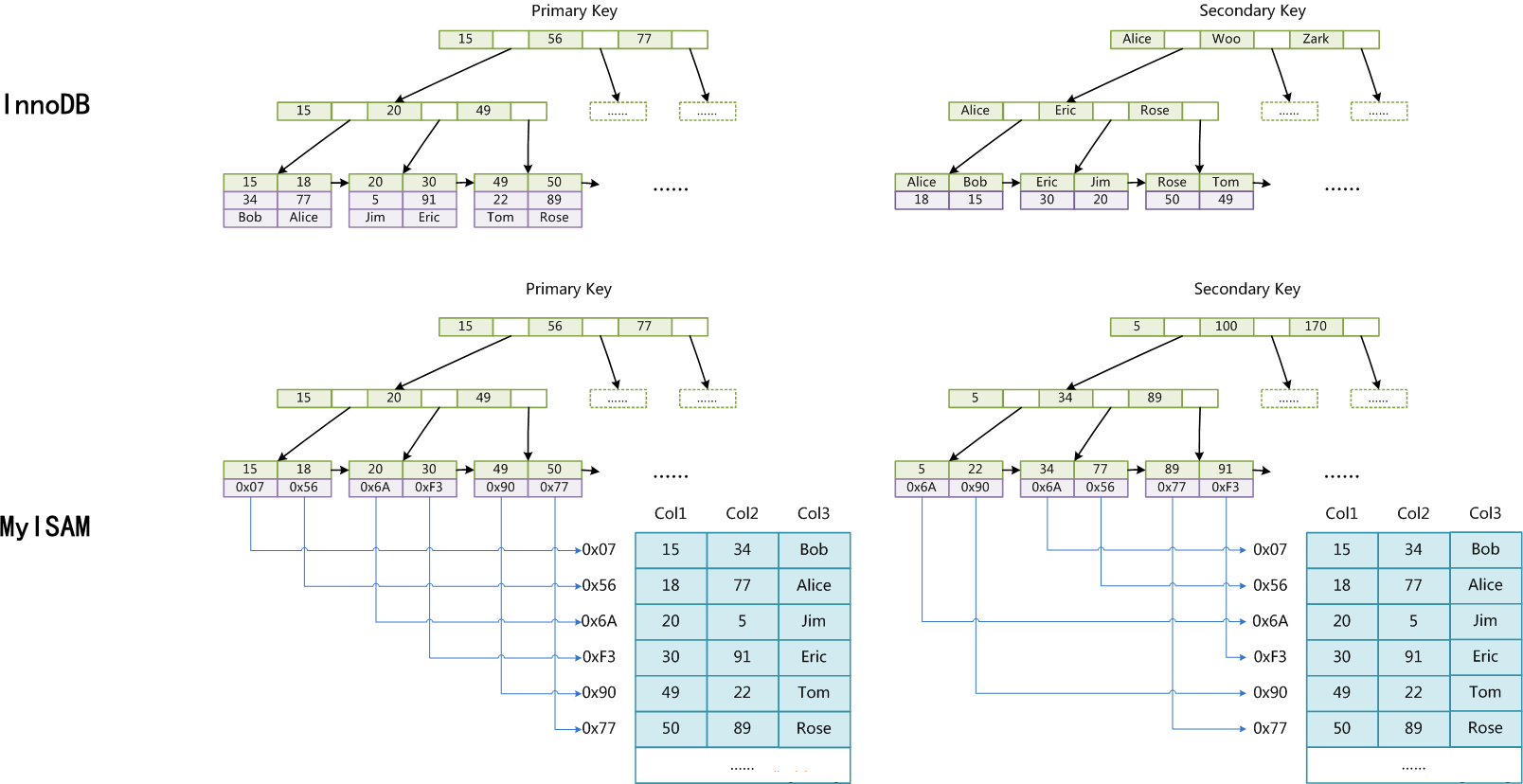
可以实现增删改查的数据结构非常多,包括:哈希表、二叉搜索树、AVL、红黑树、B 树、B+树等,这些都是可以作为索引的候选数据结构。结合 MySQL 的实际情况:磁盘和内存交互、随机磁盘 IO、排序和范围查找、增删改的复杂度等等,综合考量之下 B+ 树脱颖而出。MyISAM 是将数据和索引分开存储的,InnoDB 存储引擎的数据和索引没有分开存储,这也就是为什么有人说 Innodb 索引即数据,数据即索引,如图:

-
InnoDB 可以看做是聚集索引,因为它的 B+ 树的叶结点包含了完整的数据记录。InnoDB 的数据文件本身就是索引文件,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。换句话说,InnoDB 的所有辅助索引都引用主键作为 data 域。
-
而 MyISAM 方式 B+ 树的叶结点只是存储了数据的地址,故称为非聚集索引。MyISAM 引擎使用 B+Tree 作为索引结构,叶节点的 data 域存放的是数据记录的地址;在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。
聚簇索引与普通索引
在 InnoDB 中,又有聚簇索引和普通索引之分,聚簇索引根据主键来构建,叶子节点存放的是该主键对应的这一行记录,根据主键查询可以直接利用聚簇索引定位到所在记录。而普通索引根据申明这个索引时候的列来构建,叶子节点存放的是这一行记录对应的主键的值,根据普通索引查询需要先在普通索引上找到对应的主键的值,然后根据主键值去聚簇索引上查找记录,俗称回表。如果我们查询一整行记录的话,一定要去聚簇索引上查找,而如果我们只需要根据普通索引查询主键的值,由于这些值在普通索引上已经存在,所以并不需要回表,这个称为索引覆盖,在一定程度上可以提高查询效率。
普通索引中还有唯一索引和联合索引两个特例,唯一索引在插入和修改的时候会校验该索引对应的列的值是否已经存在,联合索引将两个列的值按照声明时候的顺序进行拼接后在构建索引。数据行并不是存储引擎管理的最小存储单位,索引只能够帮助我们定位到某个数据页,每一次磁盘读写的最小单位为也是数据页,而一个数据页内存储了多个数据行,我们需要了解数据页的内部结构才能知道存储引擎怎么定位到某一个数据行,可以参考《MySQL-Notes》系列。
聚簇索引
聚簇索引将索引和数据完美地融合在一起,是每个 Innodb 表都会有的一个特殊索引,一般来说是借助于表的主键来构建的 B+树。假设我们有 student 表,将 id 作为主键索引,那么聚簇索引的 B+树结构,如图:
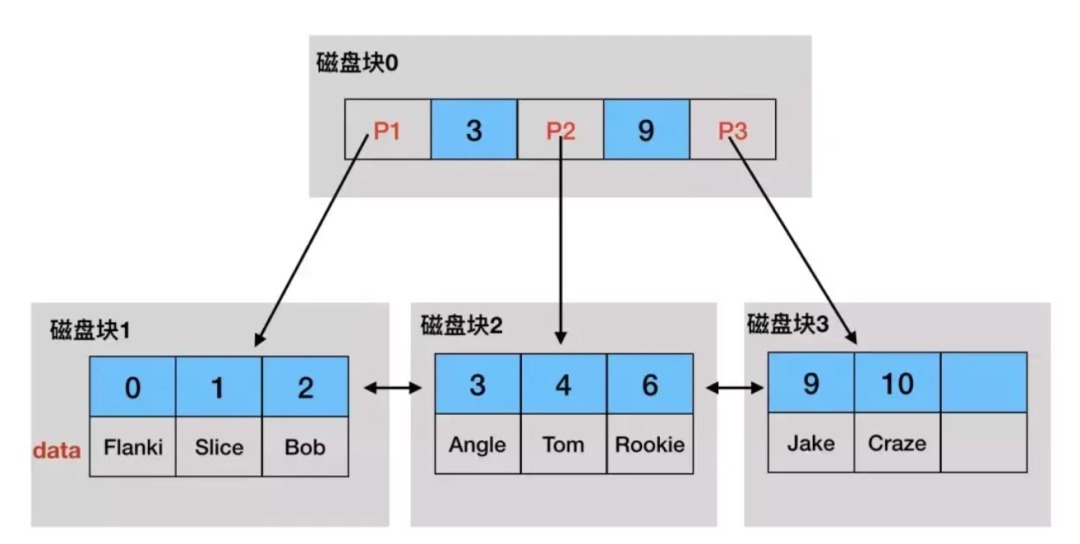
-非叶子节点不存数据,只有主键和相关指针
- 叶子节点包含主键、行数据、指针
- 叶子节点之间由双向指针串联形成有序双向链表,叶子节点内部也是有序的
聚簇索引按照如下规则创建:
- 有主键时 InnoDB 利用主键来生成
- 没有主键,InnoDB 会选择一个非空的唯一索引来创建
- 无主键且非 NULL 唯一索引时,InnoDB 会隐式创建一个自增的列来创建
假如我们要查找 id=10 的数据,大致过程如下:
- 索引的根结点在内存中,10>9 因此找到 P3 指针
- P3 指向的数据并没有在内存中,因此产生 1 次磁盘 IO 读取磁盘块 3 到内存
- 在内存中对磁盘块 3 进行二分查找,找到 ID=9 的全部值
普通索引
普通索引的叶子节点中存放的是二级索引值和主键键值,非叶子节点和叶子节点都没有存储整行数据值。假设我们有 student 表,将 name 作为二级索引,那么普通索引的 B+树结构,如图:
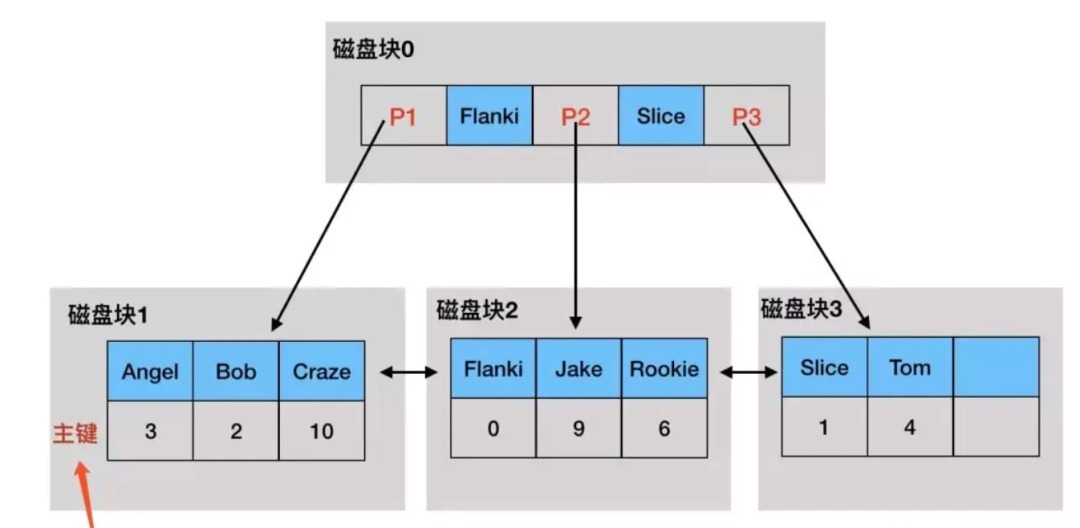
由于普通索引的叶子节点没有存储行数据,如果通过普通索引来查找非二级索引值,需要分为两步:
- 第一:通过普通索引的叶子节点来确定数据行对应的主键
- 第二:通过相应的主键值在聚簇索引中查询到对应的行记录
我们把通过普通索引找到主键值,再根据主键值从聚簇索引找对于行数据的过程称为:回表查询。换句话说:select * from student where name = 'Bob' 将产生回表查询,因为在 name 索引的叶子节点没有其他值,只能从聚簇索引获得。所以如果查找的字段在普通索引就可以完成,就可以避免一次回表过程,这种称为:覆盖索引,所以 select * 并不是好习惯,需要什么拿什么就好。
假如我们要查找 name=Tom 的记录的所有值,大致过程如下:
- 从普通索引开始,根节点在内存中,按照 name 的字典序找到 P3 指针
- P3 指针所指向的磁盘块不在内存中,产生 1 次磁盘 IO 加载到内存
- 在内存中对磁盘块 3 的数据进行搜索,获得 name=tom 的记录的主键值为 4
- 根据主键值 4 从聚簇索引的根节点中获得 P2 指针
- P2 指针所指向的磁盘块不在内存中,产生第 2 次磁盘 IO 加载到内存
- 将上一步获得的数据,在内存中进行二分查找获得全部行数据
上述查询就包含了一次回表过程,因此性能比主键查询慢了一倍,因此尽量使用主键查询,一次完事。
Links
- https://mp.weixin.qq.com/s/os-kSr3NQkj4B7hkc2sZ3g 原来这就是 MySQL 中的索引