
读写分离
读写分离
随着业务的不断发展,用户数量和并发量不断上升。这时如果仅靠单个数据库实例来支撑所有访问压力,几乎是在 自寻死路。以产品库为例,可能库中包含了几万种商品,并且每天新增几十种,而产品库每天的访问了可能有几亿甚至几十亿次。数据库读的压力太大,单台 mysql 实例扛不住,此时大部分 Mysql DBA 就会将数据库设置成 读写分离状态。也就是一个 Master 节点(主库)对应多个 Salve 节点(从库)。可以将 slave 节点的数据理解为 master 节点数据的全量备份。
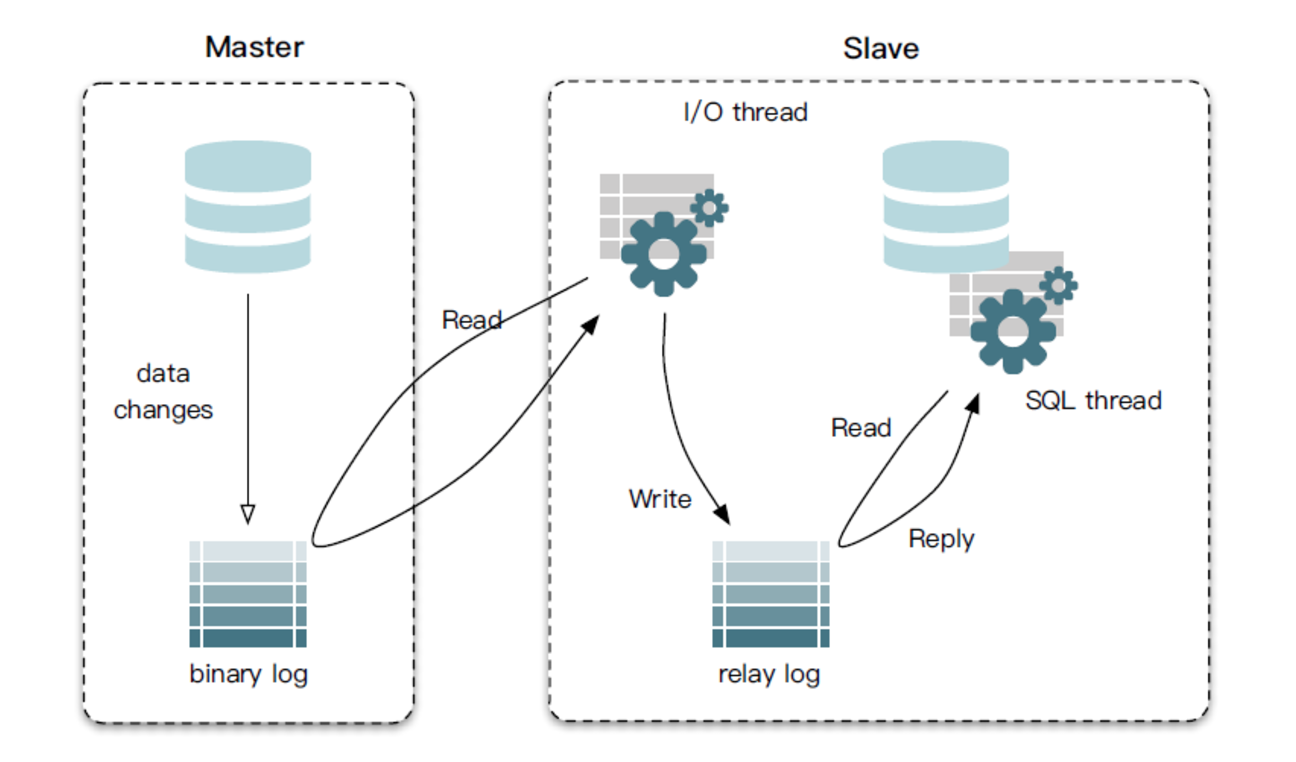
master 节点接收用户的写请求,并写入到本地二进制文件(binary log)中。slave 通过一个 IO 线程与 Master 建立连接,发送 Binlog dump 指令。Master 会将 Binlog 数据推送给 slave,slave 将接收到的 Binlog 保存到本地的中继日志(relay log)中,最后,slave 通过另一个线程 SQL thread 应用本地的 relay log,将数据同步到 slave 库中。
当更新数据时,应用将数据写入 master 主库,主库将数据同步给多个 slave 从库。当查询数据时,应用选择某个 slave 节点读取数据。当更新数据时,应用将数据写入 master 主库,主库将数据同步给多个 slave 从库。当查询数据时,应用选择某个 slave 节点读取数据。
读写分离的挑战
-
主从数据同步延迟问题:因为数据是从 master 节点通过网络同步给多个 slave 节点,因此必然存在延迟。因此有可能出现我们在 master 节点中已经插入了数据,但是从 slave 节点却读取不到的问题。对于一些强一致性的业务场景,要求插入后必须能读取到,因此对于这种情况,我们需要提供一种方式,让读请求也可以走主库,而主库上的数据必然是最新的。
-
事务问题:如果一个事务中同时包含了读请求(如 select)和写请求(如 insert),如果读请求走从库,写请求走主库,由于跨了多个库,那么本地事务已经无法控制,属于分布式事务的范畴。而分布式事务非常复杂且效率较低。因此对于读写分离,目前主流的做法是,事务中的所有 sql 统一都走主库,由于只涉及到一个库,本地事务就可以搞定。
-
感知集群信息变更:如果访问的数据库集群信息变更了,例如主从切换了,写流量就要到新的主库上;又例如增加了从库数量,流量需要可以打到新的从库上;又或者某个从库延迟或者失败率比较高,应该将这个从库进行隔离,读流量尽量打到正常的从库上。
主从路由
基本路由路功能主要是解决,在读写分离的情况下,如何实现一些基本的路由功能,这个过程通常可以通过下图进行描述:

主库路由策略
主要是判断出来 sql 是读还是写 sql,将读 sql 到从库上去执行,写 sql 去主库上执行 write 语句:insert、update、delete、create、alter、truncate… query 语句:select、show、desc、explain…
有的时候,对于一些强一致性的场景,需要写入后,必须能读取到数据。由于主从同步存在延迟,可能会出现主库写入,而从库查不到的情况。这次时候,我们需要使用强制走主库的功能。具体实现上有 2 种方案:hint 或 API
hint,就是开发人员在 sql 上做一些特殊的标记,数据库中间件识别到这个标记,就知道这个 sql 需要走主库,如:
/*master*/select * from table_xx
这里的/master/就是一个 hint,表示需要走主库。不同的数据库中间件强制走主库的 hint 可能不同,例如 zebra 的 hint 为/zebra:w+/,hint 到底是什么样是无所谓的,其作用仅仅就是一个标记而已。之所以将 hint 写在/…/中,是因为这是标准的 sql 注释语法。即使数据库中间件未能识别这个 hint,也不会导致 sql 语法错误。
api 方式主要是通过代码的方式来添加 sql 走主库的标识,hint 通常只能加在某个 sql 上。如果我们希望多个 sql 同时都走主库,也不希望加 hint,则可以通过 api 的方式,其内部主要利用语言的 thread local 线程上下文特性,如:
ForceMasterHelper.forceMaster()
//…执行多条sql
ForceMasterHelper.clear()
在 api 标识范围内执行的 sql,都会走主库。具体 API 到底应该是什么样,如何使用,也是由相应的数据库中间件来决定的。特别的,对于一些特殊的 sql,例如 select last_insert_id;或者 select @@identity 等,这类 sql 总是需要走主库。这些 sql 是要获得最后一个插入记录的 id,插入操作只可能发生在主库上。
从库路由策略
通常在一个集群中,只会有一个 master,但是有多个 slave。当判断是一个读请求时,如何判断选择哪个 slave。一些简单的选择策略包括:随机选择(random),按照权重进行选择(weight),或者轮训(round-robin),等。特别的,对于一些跨 IDC(数据中心)部署的数据库集群,通常需要有就近路由的策略。
当然一个数据中心内,可能会部署多个 slave,也需要进行选择,因此就近路由通常和一些基本的路由策略结合使用。另外,对于就近路由,通常也会有一个层级,例如同机房、同中心、同区域、跨区域等。
高可用保障
数据库中间件除了需要具备上述提到的读写分离功能来访问底层的数据库集群。也需要一套支持高可用、动态扩展的体系:
-
从 HA 的角度来说,例如主库宕机了,那么应该从从库选择一个作为新的主库。开源的 MHA 可以帮助我们完成这个事;然而,MHA 只能在主库宕机的情况下,完成主从切换,对于仅仅是一个从库宕机的情况下,MHA 通常是无能为力的。因此,通常都会在 MHA 进行改造,使其支持更多的 HA 能力要求。
-
从 Scalable 角度来说,例如读 qps 实在太高,需要加一些从库,来分担读流量。
事实上,无论是 HA,还是 Scalable,对于数据库中间件(不论是 proxy 或者 smart-client)来说,只是配置信息发生了变更。因此,通常我们会将所有的配置变更信息写到一个配置中心,然后配置心中监听这个配置的变更,例如主从切换,只需要把最新的主从信息设置到配置中心;增加从库,把新从库 ip、port 等信息放到配置中心。数据库中间件通过对这些配置信息变更进行监听,当配置发生变更时,实时的应用最新的配置信息即可。
一个简化的数据库中间件的高可用架构通常如下所示:
配置中心
监控服务对集群进行监控,当发生变更时,将变更的信息 push 到配置中心中,数据库中间件(proxy 或 smart-client)接收到配置变更,应用最新的配置。而整个过程,对于业务代码基本是无感知的。 对于配置中心的选择,有很多,例如百度的 disconf、阿里的 diamond、点评开源的 lion、携程开源的 apollo 等,也可以使用 etcd、consul。通常如果没有历史包袱的话,建议使用携程开源的 apollo。 特别需要注意的一点是,通常监控服务监控到集群信息变更,推送到配置中心,再到数据库中间件,必然存在一些延迟。对于一些场景,例如主从切换,没有办法做到彻底的业务无感知。当然,对于多个从库中,某个从库宕机的情况下,是可以做到业务无感知的。例如,某个从库失败,数据库中间件,自动从其他正常的从库进行重试。
端兜底
上图中的 HA 方案强依赖于配置中心,如果某个数据库集群上建立了很多库,这个集群发生变更时,将会存在大量的配置信息需要推送。又或者,如果数据库集群是多机房部署的,在某个机房整体宕机的情况下(例如光纤被挖断了,或者机房宕机演练),也会存在大量的配置信息需要推送。如果配置中心,推送有延迟,业务会有非常明显的感知。 因此,通常我们会在客户端进行一些轻量级的 HA 保障。例如,根据数据库返回异常的 sqlstate 和 vendor code,判断异常的严重级别,确定数据库实例能否正常提供服务,如果不能正常提供服务,则自动将其进行隔离,并启动异步线程进行检测数据库实例是否恢复。 最后,很多数据库中间件,也会提供一些限流和降级的功能,计算 sql 的唯一标识(有些称之为 sql 指纹),对于一些烂 sql,导致数据库压力变大的情况,可以实时的进行拦截,直接抛出异常,不让这些 sql 打到后端数据库上去。