
02.分库分表
数据库的拆分
单点容易出现故障,性能方面也可能成为瓶颈,因此需要将单点改造拆分成多个点。当单点数据库的每秒访问量达到数万级别,可能会发现数据库服务器的磁盘 IO、网络带宽、CPU 负载、内存消耗,都会达到非常高的情况,数据库所在服务器的整体负载会非常重,以至于 SQL 性能更差,接口响应缓慢,甚至造成数据库宕机。
阿里巴巴《Java 开发手册》提出单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。事实上,这个数值和实际记录的条数无关,而与 MySQL 的配置以及机器的硬件有关。因为,MySQL 为了提高性能,会将表的索引装载到内存中。InnoDB buffer size 足够的情况下,其能完成全加载进内存,查询不会有问题。但是,当单表数据库到达某个量级的上限时,导致内存无法存储其索引,使得之后的 SQL 查询会产生磁盘 IO,从而导致性能下降。当然,这个还有具体的表结构的设计有关,最终导致的问题都是内存限制。这里,增加硬件配置,可能会带来立竿见影的性能提升哈。
数据库层面的可靠性保障,通常的措施是通过主备来解决可用性问题,通过分片来解决性能问题。
拆分维度
数据库构架设计中主要有 Shared Everthting、Shared Nothing、和 Shared Disk:
-
Shared Everthting:一般是针对单个主机,完全透明共享 CPU/MEMORY/IO,并行处理能力是最差的,典型的代表 SQLServer
-
Shared Disk:各个处理单元使用自己的私有 CPU 和 Memory,共享磁盘系统。典型的代表 Oracle Rac,它是数据共享,可通过增加节点来提高并行处理的能力,扩展能力较好。其类似于 SMP(对称多处理)模式,但是当存储器接口达到饱和的时候,增加节点并不能获得更高的性能。
-
Shared Nothing:各个处理单元都有自己私有的 CPU/内存/硬盘等,不存在共享资源,类似于 MPP(大规模并行处理)模式,各处理单元之间通过协议通信,并行处理和扩展能力更好。典型代表 DB2 DPF 和 hadoop,各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。
我们常说的 Sharding 其实就是 Share Nothing 架构,它是把某个表从物理存储上被水平分割,并分配给多台服务器(或多个实例),每台服务器可以独立工作,具备共同的 schema,比如 MySQL Proxy 和 Google 的各种架构,只需增加服务器数就可以增加处理能力和容量。
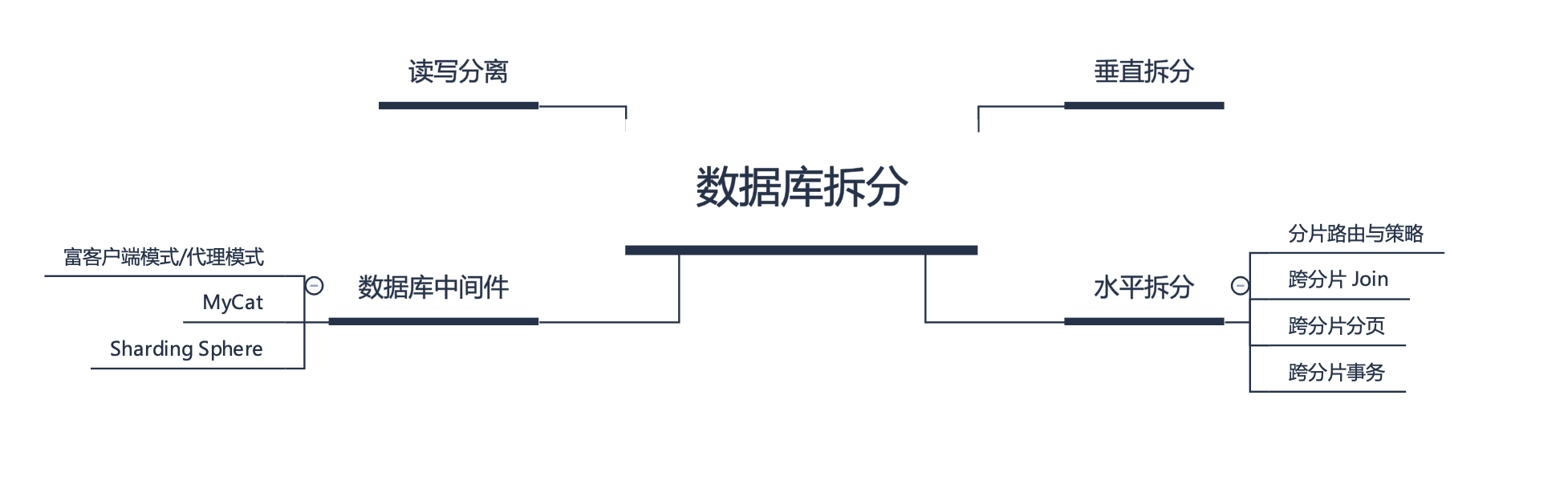
互联网当下的数据库拆分过程基本遵循的顺序是:垂直拆分、读写分离、分库分表(水平拆分)。每个拆分过程都能解决业务上的一些问题,但同时也面临了一些挑战。
垂直拆分能更清晰化模块划分,区分治理,水平切分能解决大数据量性能瓶颈问题,分布式改造主要是将这两者结合起来,对传统架构进行全面的改造。垂直拆分就是将原来一个整体的系统按业务模块拆分成多个系统,系统内部数据是自包含的,不会与别的系统共用数据库,系统与系统之间的交互通过暴露和调用服务来实现。前面讲的垂直拆分只是把系统按业务模块划分到不同的子系统,数据库也分到了不同系统,但没有解决单表大数据量的问题,而水平切分就是要把一个表按照某种规则把数据划分到不同表或数据库里。简单的说就是做分库分表。
数据模型分类
在做分库分表之前我们需对数据模型进行分类,分为“流水型数据”、“状态型数据”和“配置型数据”。
流水型数据:像流水一样不断增长的数据,各条数据间是独立的。如支付订单、交易流水、帐务流水(入帐/出帐)、会计流水等。
状态型数据:代表一个对象当前的状态的数据。如会员信息、客户信息、帐户信息、会计帐。
配置型数据:系统中用作为配置的数据。如产品、手续费率、分支机构信息、支付路由规则、会计科目等。
流水型数据会不断产生,且各条数据间是独立的,天然适合进行分库分表。
状态型数据读写比相当,每一次写操作必须基于前一个正确的状态,可以评估一下数据量的大小,数据量如果大或者要实现单元化架构,也需要进行分库分表,提高并发处理能力,同时方便隔离故障影响。
配置型数据,读多写少,强依赖读,弱依赖写,不要求严格的读一致性,且配置型数据一般数据量不会很大,不需要进行分库分表设计。但是业务处理中往往又需要用到,传统架构的老系统可能使用了一些关联表操作,关联到了配置数据,分库后其它数据与配置不在一个库,不能进行关联表操作,由于配置型数据不要求严格的读一致性的特点,可以将配置型数据加载到分布式缓存里,由业务代码来做“join”。
那么分库分表按照什么规则来拆分呢?通常不会按实体 id 进行 hash 取模的方式来拆分。因为希望同一个用户的数据能够在同一个数据库中,尽量避免产生分布式事务。业界普遍的做法是通过用户维度来进行拆分。由于不同实体 id 的值不同,且不能保证每个实体和请求中都包含用户 id,所以简单的用实体 id 或用户 id 进行 hash 取模将不能保证同一个用户的数据都落在同一个分片。

一种推荐做法是,在用户创建的时候给该用户随机或一定规则(如地区)生成一个两位的分片号 00~99(两位意味着可以分成百库百表,通常够用了),那么在生成与该用户相关的所有实体的 id 的时候,都约定把这个分片号拼接到这个 id 中。在分布式数据访问框架中进行路由选择时,就可以取 id 中的分片号进行路由,而不依赖于用户 id。且在排查问题的时候也非常方便定位数据的存储位置。
所以数据水平拆分除了需要一个强大的分库分表数据访问中间件,还需要一个分布式序列生成器。当然这个生成器也可以是集成在分库分表数据访问中间件中的一个功能。