
2018-司徒正美-React Fiber 架构
React Fiber 架构
性能优化是一个系统性的工程,如果只看到局部,引入算法,当然是越快越好; 但从整体来看,在关键点引入缓存,可以秒杀 N 多算法,或另辟蹊径,探索事件的本质,可能用户要的并不是快……
React16 启用了全新的架构,叫做 Fiber,其最大的使命是解决大型 React 项目的性能问题,再顺手解决之前的一些痛点。
痛点
主要有如下几个:
- 组件不能返回数组,最见的场合是 UL 元素下只能使用 LI,TR 元素下只能使用 TD 或 TH,这时这里有一个组件循环生成 LI 或 TD 列表时,我们并不想再放一个 DIV,这会破坏 HTML 的语义。
- 弹窗问题,之前一直使用不稳定的 unstable_renderSubtreeIntoContainer。弹窗是依赖原来 DOM 树的上下文,因此这个 API 第一个参数是组件实例,通过它得到对应虚拟 DOM,然后一级级往上找,得到上下文。它的其他参数也很好用,但这个方法一直没有转正。。。
- 异常处理,我们想知道哪个组件出错,虽然有了 React DevTool,但是太深的组件树查找起来还是很吃力。希望有个方法告诉我出错位置,并且出错时能让我有机会进行一些修复工作
- HOC 的流行带来两个问题,毕竟是社区兴起的方案,没有考虑到 ref 与 context 的向下传递。
- 组件的性能优化全凭人肉,并且主要集中在 SCU,希望框架能干些事情,即使不用 SCU,性能也能上去。
解决进度
- 16.0 让组件支持返回任何数组类型,从而解决数组问题; 推出 createPortal API ,解决弹窗问题; 推出 componentDidCatch 新钩子, 划分出错误组件与边界组件, 每个边界组件能修复下方组件错误一次, 再次出错,转交更上层的边界组件来处理,解决异常处理问题。
- 16.2 推出 Fragment 组件,可以看作是数组的一种语法糖。
- 16.3 推出 createRef 与 forwardRef 解决 Ref 在 HOC 中的传递问题,推出 new Context API,解决 HOC 的 context 传递问题(主要是 SCU 作崇)
- 而性能问题,从 16.0 开始一直由一些内部机制来保证,涉及到批量更新及基于时间分片的限量更新。
一个小实验
我们可以通过以下实验来窥探 React16 的优化思想。
function randomHexColor() {
return (
"#" + ("0000" + ((Math.random() * 0x1000000) << 0).toString(16)).substr(-6)
);
}
setTimeout(function () {
var k = 0;
var root = document.getElementById("root");
for (var i = 0; i < 10000; i++) {
k += new Date() - 0;
var el = document.createElement("div");
el.innerHTML = k;
root.appendChild(el);
el.style.cssText = `background:${randomHexColor()};height:40px`;
}
}, 1000);
这是一个拥有 10000 个节点的插入操作,包含了 innerHTML 与样式设置,花掉 1000ms。
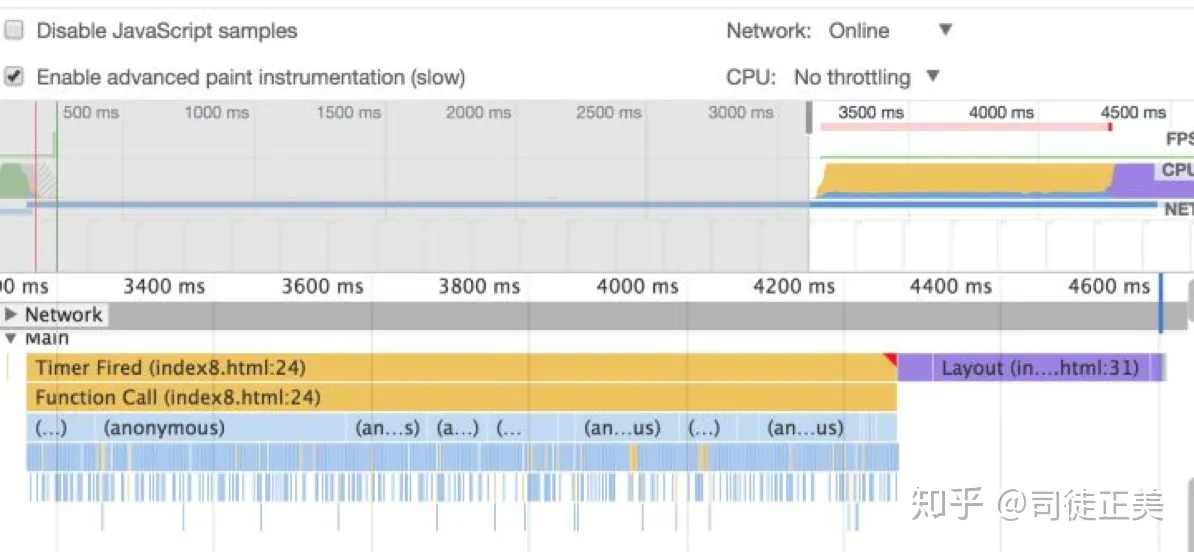
我们再改进一下,分派次插入节点,每次只操作 100 个节点,共 100 次,发现性能异常的好!
function randomHexColor() {
return (
"#" + ("0000" + ((Math.random() * 0x1000000) << 0).toString(16)).substr(-6)
);
}
var root = document.getElementById("root");
setTimeout(function () {
function loop(n) {
var k = 0;
console.log(n);
for (var i = 0; i < 100; i++) {
k += new Date() - 0;
var el = document.createElement("div");
el.innerHTML = k;
root.appendChild(el);
el.style.cssText = `background:${randomHexColor()};height:40px`;
}
if (n) {
setTimeout(function () {
loop(n - 1);
}, 40);
}
}
loop(100);
}, 1000);
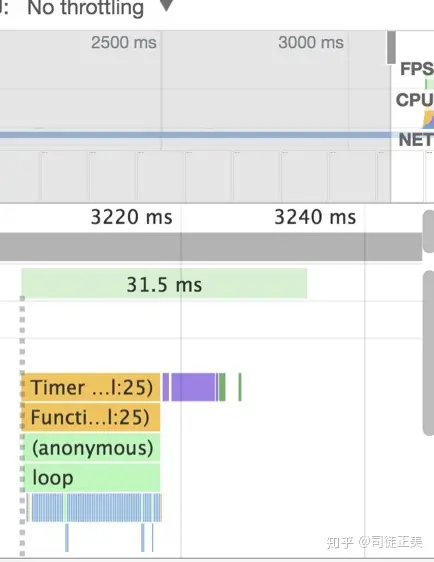
究其原因是因为浏览器是单线程,它将 GUI 描绘,时间器处理,事件处理,JS 执行,远程资源加载统统放在一起。当做某件事,只有将它做完才能做下一件事。如果有足够的时间,浏览器是会对我们的代码进行编译优化(JIT)及进行热代码优化,一些 DOM 操作,内部也会对 reflow 进行处理。reflow 是一个性能黑洞,很可能让页面的大多数元素进行重新布局。
浏览器的运作流程
渲染 -> tasks -> 渲染 -> tasks -> 渲染 -> tasks -> ….
这些 tasks 中有些我们可控,有些不可控,比如 setTimeout 什么时候执行不好说,它总是不准时; 资源加载时间不可控。但一些 JS 我们可以控制,让它们分派执行,tasks 的时长不宜过长,这样浏览器就有时间优化 JS 代码与修正 reflow!下图是我们理想中的渲染过程
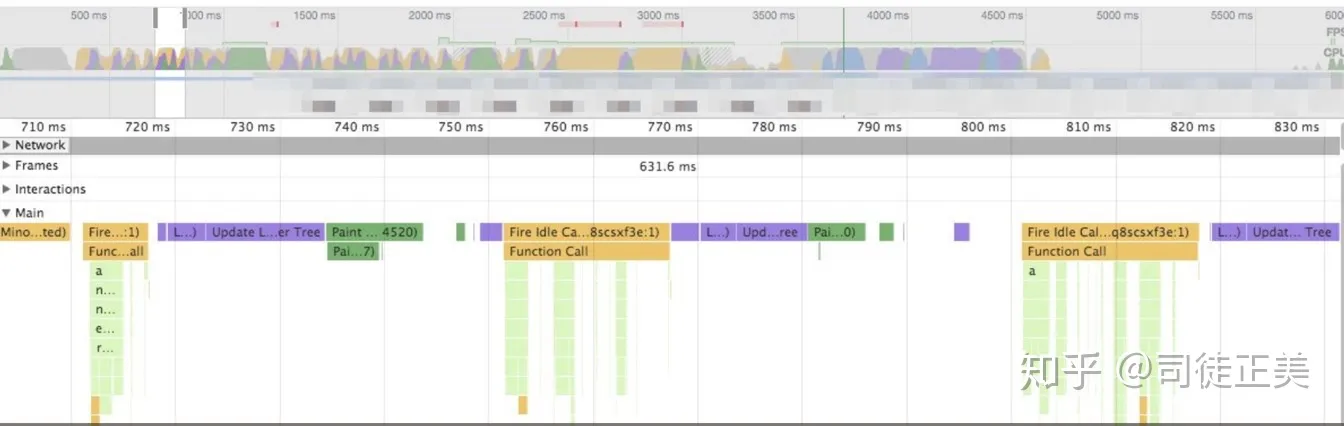
总结一句,就是让浏览器休息好,浏览器就能跑得更快。
如何让代码断开重连
JSX 是一个快乐出奇蛋,一下子满足你两个愿望:组件化与标签化。并且 JSX 成为组件化的标准化语言。
<div>
<Foo>
<Bar />
</Foo>
</div>
但标签化是天然套嵌的结构,意味着它会最终编译成递归执行的代码。因此 React 团队称 React16 之前的调度器为栈调度器,栈没有什么不好,栈显浅易懂,代码量少,但它的坏处不能随意 break 掉,continue 掉。根据我们上面的实验,break 后我们还要重新执行,我们需要一种链表的结构。
链表是对异步友好的。链表在循环时不用每次都进入递归函数,重新生成什么执行上下文,变量对象,激活对象,性能当然比递归好。
因此 Reat16 设法将组件的递归更新,改成链表的依次执行。如果页面有多个虚拟 DOM 树,那么就将它们的根保存到一个数组中。
ReactDOM.render(<A />, node1);
ReactDOM.render(<B />, node2);
//node1与node2不存在包含关系,那么这页面就有两棵虚拟DOM树
如果仔细阅读源码,React 这个纯视图库其实也是三层架构。在 React15 有虚拟DOM层,它只负责描述结构与逻辑;内部组件层,它们负责组件的更新, ReactDOM.render、 setState、 forceUpdate 都是与它们打交道,能让你多次 setState,只执行一次真实的渲染, 在适合的时机执行你的组件实例的生命周期钩子; 底层渲染层, 不同的显示介质有不同的渲染方法,比如说浏览器端,它使用元素节点,文本节点,在 Native 端,会调用 oc, java 的 GUI, 在 canvas 中,有专门的 API 方法。。。
虚拟 DOM 是由 JSX 转译过来的,JSX 的入口函数是 React.createElement, 可操作空间不大, 第三大的底层 API 也非常稳定,因此我们只能改变第二层。
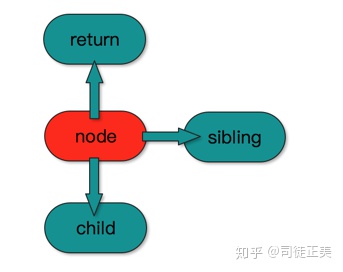
React16 将内部组件层改成 Fiber 这种数据结构,因此它的架构名也改叫 Fiber 架构。Fiber 节点拥有 return, child, sibling 三个属性,分别对应父节点, 第一个孩子, 它右边的兄弟, 有了它们就足够将一棵树变成一个链表, 实现深度优化遍历。
如何决定每次更新的数量
在 React15 中,每次更新时,都是从根组件或 setState 后的组件开始,更新整个子树,我们唯一能做的是,在某个节点中使用 SCU 断开某一部分的更新,或者是优化 SCU 的比较效率。
React16 则是需要将虚拟 DOM 转换为 Fiber 节点,首先它规定一个时间段内,然后在这个时间段能转换多少个 FiberNode,就更新多少个。
因此我们需要将我们的更新逻辑分成两个阶段,第一个阶段是将虚拟 DOM 转换成 Fiber, Fiber 转换成组件实例或真实 DOM(不插入 DOM 树,插入 DOM 树会 reflow)。Fiber 转换成后两者明显会耗时,需要计算还剩下多少时间。并且转换实例需要调用一些钩子,如 componentWillMount, 如果是重复利用已有的实例,这时就是调用 componentWillReceiveProps, shouldComponentUpdate, componentWillUpdate,这时也会耗时。
为了让读者能直观了解 React Fiber 的运作过程,我们简单实现一下 ReactDOM.render, 但不保证会跑起来。
首先是一些简单的方法:
var queue = [];
ReacDOM.render = function (root, container) {
queue.push(root);
updateFiberAndView();
};
function getVdomFormQueue() {
return queue.shift();
}
function Fiber(vnode) {
for (var i in vnode) {
this[i] = vnode[i];
}
this.uuid = Math.random();
}
//我们简单的Fiber目前来看,只比vdom多了一个uuid属性
function toFiber(vnode) {
if (!vnode.uuid) {
return new Fiber(vnode);
}
return vnode;
}
updateFiberAndView 要实现 React 的时间分片,我们先用 setTimeout 模拟。我们暂时不用理会 updateView 怎么实现,可能它就是 updateComponentOrElement 中将它们放到又一个列队,需再出来执行 insertBefore, componentDidMount 操作呢!
function updateFiberAndView() {
var now = new Date() - 0;
var deadline = new Date() + 100;
updateView(); //更新视图,这会耗时,因此需要check时间
if (new Date() < deadline) {
var vdom = getVdomFormQueue();
var fiber = vdom,
firstFiber;
var hasVisited = {};
do {
//深度优先遍历
var fiber = toFiber(fiber); //A处
if (!firstFiber) {
fibstFiber = fiber;
}
if (!hasVisited[fiber.uuid]) {
hasVisited[fiber.uuid] = 1;
//根据fiber.type实例化组件或者创建真实DOM
//这会耗时,因此需要check时间
updateComponentOrElement(fiber);
if (fiber.child) {
//向下转换
if (newDate - 0 > deadline) {
queue.push(fiber.child); //时间不够,放入栈
break;
}
fiber = fiber.child;
continue; //让逻辑跑回A处,不断转换child, child.child, child.child.child
}
}
//如果组件没有children,那么就向右找
if (fiber.sibling) {
fiber = fiber.sibling;
continue; //让逻辑跑回A处
}
// 向上找
fiber = fiber.return;
if (fiber === fibstFiber || !fiber) {
break;
}
} while (1);
}
if (queue.length) {
setTimeout(updateFiberAndView, 40);
}
}
里面有一个 do while 循环,每一次都是小心翼翼进行计时,时间不够就将来不及处理的节点放进列队。
updateComponentOrElement 无非是这样:
function updateComponentOrElement(fiber) {
var { type, stateNode, props } = fiber;
if (!stateNode) {
if (typeof type === "string") {
fiber.stateNode = document.createElement(type);
} else {
var context = {}; //暂时免去这个获取细节
fiber.stateNode = new type(props, context);
}
}
if (stateNode.render) {
//执行componentWillMount等钩子
children = stateNode.render();
} else {
children = fiber.childen;
}
var prev = null; //这里只是mount的实现,update时还需要一个oldChildren, 进行key匹配,重复利用已有节点
for (var i = 0, n = children.length; i < n; i++) {
var child = children[i];
child.return = fiber;
if (!prev) {
fiber.child = child;
} else {
prev.sibling = child;
}
prev = child;
}
}
因此这样 Fiber 的 return, child, sibling 就有了,可以 happy 地进行深度优先遍历了。
如何调度时间才能保证流畅
刚才的 updateFiberAndView 其实有一个问题,我们安排了 100ms 来更新视图与虚拟 DOM,然后再安排 40ms 来给浏览器来做其他事。如果我们的虚拟 DOM 树很小,其实不需要 100ms; 如果我们的代码之后, 浏览器有更多其他事要干, 40ms 可能不够。IE10 出现了 setImmediate,requestAnimationFrame 这些新定时器,让我们这些前端,其实浏览器有能力让页面更流畅地运行起来。
浏览器本身也不断进化中,随着页面由简单的展示转向 WebAPP,它需要一些新能力来承载更多节点的展示与更新。
下面是一些自救措施:
- requestAnimationFrame
- requestIdleCallback
- web worker
- IntersectionObserver
我们依次称为浏览器层面的帧数控制调用,闲时调用,多线程调用, 进入可视区调用。
requestAnimationFrame 在做动画时经常用到,jQuery 新版本都使用它。web worker 在 angular2 开始就释出一些包,实验性地用它进行 diff 数据。IntersectionObserver 可以用到 ListView 中。而 requestIdleCallback 是一个生脸孔,而 React 官方恰恰看上它。
刚才说 updateFiberAndView 有出两个时间段,一个给自己的,一个给浏览器的。requestAnimationFrame 能帮我们解决第二个时间段,从而确保整体都是 60 帧或 75 帧(这个帧数可以在操作系统的显示器刷新频率中设置)流畅运行。
我们看 requestIdleCallback 是怎么解决这问题的

它的第一个参数是一个回调,回调有一个参数对象,对象有一个 timeRemaining 方法,就相当于new Date - deadline,并且它是一个高精度数据, 比毫秒更准确, 至少浏览器到底安排了多少时间给更新 DOM 与虚拟 DOM,我们不用管。第二个时间段也不用管,不过浏览器可能 1,2 秒才执行这个回调,因此为了保险起见,我们可以设置第二个参数,让它在回调结束后 300ms 才执行。要相信浏览器,因为都是大牛们写的,时间的调度比你安排更有效率。
于是我们的 updateFiberAndView 可以改成这样:
function updateFiberAndView(dl) {
updateView(); //更新视图,这会耗时,因此需要check时间
if (dl.timeRemaining() > 1) {
var vdom = getVdomFormQueue();
var fiber = vdom,
firstFiber;
var hasVisited = {};
do {
//深度优先遍历
var fiber = toFiber(fiber); //A处
if (!firstFiber) {
fibstFiber = fiber;
}
if (!hasVisited[fiber.uuid]) {
hasVisited[fiber.uuid] = 1;
//根据fiber.type实例化组件或者创建真实DOM
//这会耗时,因此需要check时间
updateComponentOrElement(fiber);
if (fiber.child) {
//向下转换
if (dl.timeRemaining() > 1) {
queue.push(fiber.child); //时间不够,放入栈
break;
}
fiber = fiber.child;
continue; //让逻辑跑回A处,不断转换child, child.child, child.child.child
}
}
//....略
} while (1);
}
if (queue.length) {
requetIdleCallback(updateFiberAndView, {
timeout: new Date() + 100,
});
}
}
到这里,ReactFiber 基于时间分片的限量更新讲完了。实际上 React 为了照顾绝大多数的浏览器,自己实现了 requestIdleCallback。
批量更新
但 React 团队觉得还不够,需要更强大的东西。因为有的业务对视图的实时同步需求并不强烈,希望将所有逻辑都跑完才更新视图,于是有了 batchedUpdates,目前它还不是一个稳定的 API,因此大家使用它时要这样用 ReactDOM.unstable_batchedUpdates。
这个东西怎么实现呢?就是搞一个全局的开关,如果打开了,就让 updateView 不起作用。
var isBatching = false
function batchedUpdates(callback, event) {
let keepbook = isBatching;
isBatching = true;
try {
return callback(event);
} finally {
isBatching = keepbook;
if (!isBatching) {
requetIdleCallback(updateFiberAndView, {
timeout:new Date + 1
}
}
}
};
function updateView(){
if(isBatching){
return
}
//更新视图
}
事实上,当然没有这么简单,考虑到大家看不懂 React 的源码,大家可以看一下 anujs 是怎么实现的:
https://github.com/RubyLouvre/anu/blob/master/packages/fiber/scheduleWork.js#L94-L113
React 内部也大量使用 batchedUpdates 来优化用户代码,比如说在事件回调中 setState,在 commit 阶段的钩子(componentDidXXX)中 setState 。
可以说,setState是对单个组件的合并渲染,batchedUpdates是对多个组件的合并渲染。合并渲染是 React 最主要的优化手段。
为什么使用深度优化遍历
React 通过 Fiber 将树的遍历变成了链表的遍历,但遍历手段有这么多种,为什么偏偏使用 DFS?!
这涉及一个很经典的消息通信问题。如果是父子通信,我们可以通过 props 进行通信,子组件可以保存父的引用,可以随时 call 父组件。如果是多级组件间的通信,或不存在包含关系的组件通信就麻烦了,于是 React 发明了上下文对象(context)。
context 一开始是一个空对象,为了方便起见,我们称之为unmaskedContext。
当它遇到一个有 getChildContext 方法的组件时,那个方法会产生一个新 context,与上面的合并,然后将新 context 作为 unmaskedContext 往下传。
当它遇到一个有 contextTypes 的组件,context 就抽取一部分内容给这个组件进行实例化。这个只有部分内容的 context,我们称之为maskedContext。
组件总是从 unmaskedContext 中割一块肉下来作为自己的 context。可怜!
如果子组件没有 contextTypes,那么它就没有任何属性。
在 React15 中,为了传递 unmaskedContext,于是大部分方法与钩子都留了一个参数给它。但这么大架子的 context 竟然在文档中没有什么地位。那时 React 团队还没有想好如何处理组件通信,因此社区一直用舶来品 Redux 来救命。这情况一直到 Redux 的作者入主 React 团队。
还有一个隐患,它可能被 SCU 比较时是用 maskedContext,而不是 unmaskedContext。
基于这些问题,终于 new Context API 出来了。首先, unmaskedContext 不再像以前那样各个方法中来往穿梭了,有一个独立的 contextStack。开始时就 push 进一个空对象,到达某个组件需要实例化时,就取它第一个。当再次访问这个组件时, 就像它从栈中弹出。因此我们需要深度优先遍历,保证每点节点都访问两次。
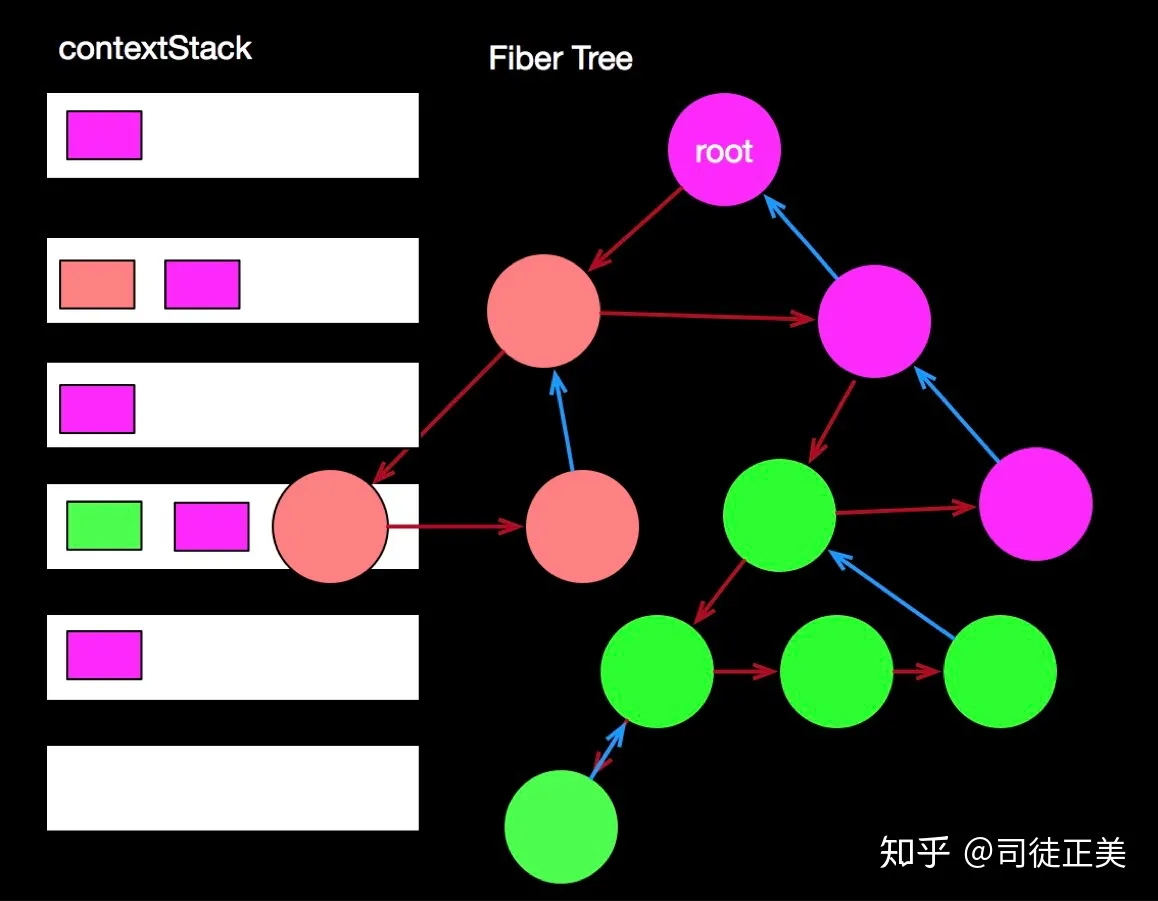
相同的情况还有 container,container 是我们某个元素虚拟 DOM 需要用到的真实父节点。在 React15 中,它会装在一个 containerInfo 对象也层层传送。
我们知道,虚拟 DOM 分成两大类,一种是组件虚拟 DOM,type 为函数或类,它本身不产生节点,而是生成组件实例,而通过 render 方法,产生下一级的虚拟 DOM。一种是元素虚拟 DOM,type 为标签名,会产生 DOM 节点。上面的元素虚拟 DOM 的 stateNode(DOM 节点),就是下方的元素虚拟 DOM 的 contaner。
这种独立的栈机制有效地解决了内部方法的参数冗余问题。
但有一个问题,当第一次渲染完毕后,contextStack 置为空了。然后我们位于虚拟 DOM 树的某个组件 setState,这时它的 context 应该如何获取呢?React 的解决方式是,每次都是从根开始渲染,通过 updateQueue 加速跳过没有更新的 节点——每个组件在 setState 或 forceUpdate 时,都会创建一个 updateQueue 属性在它的上面。anujs 则是保存它之前的 unmaskedContext 到实例上,unmaskedContext 可以看作是上面所有 context 的并集,并且一个可以当多个使用。
当我们批量更新时,可能有多少不连续的子组件被更新了,其中两个组件之间的某个组件使用了 SCU return false,这个 SCU 应该要被忽视。 因此我们引用一些变量让它透明化。就像 forceUpdate 能让组件无视 SCU 一样。
为什么要对生命周期钩子大换血
React 将虚拟 DOM 的更新过程划分两个阶段,reconciler 阶段与 commit 阶段。reconciler 阶段对应早期版本的 diff 过程,commit 阶段对应早期版本的 patch 过程。
一些迷你 React,如 preact 会将它们混合在一起,一边 diff 一边 patch(幸好它使用了 Promise.then 来优化,确保每次只更新一个组件) 。
有些迷你 React 则是通过减少移动进行优化,于是绞尽脑汁,用上各种算法,最短编辑距离,最长公共子序列,最长上升子序列。。。
其实基于算法的优化是一种绝望的优化,就类似玛雅文明因为找不到铜矿一直停留于石器时代,诞生了伟大的工匠精神把石器打磨得美伦美奂。
之所以这么说,因为 diff 算法都用于组件的新旧 children 比较,children 一般不会出现过长的情况,有点大炮打蚊子。况且当我们的应用变得非常庞大,页面有上万个组件,要 diff 这么多组件,再卓绝的算法也不能保证浏览器不会累趴。因为他们没想到浏览器也会累趴,也没有想到这是一个长跑的问题。如果是 100 米短跑,或者 1000 米竞赛,当然越快越好。如果是马拉松,就需要考虑到保存体力了,需要注意休息了。性能是一个系统性的工程。
在我们的代码里面,休息就是检测时间然后断开 Fiber 链。
updateFiberAndView 里面先进行 updateView,由于节点的更新是不可控,因此全部更新完,才检测时间。并且我们完全不用担心 updateView 会出问题,因为 updateView 实质上是在 batchedUpdates 中,里面有 try catch。而接下来我们基于 DFS 更新节点,每个节点都要 check 时间,这个过程其实很害怕出错的, 因为组件在挂载过程中会调三次钩子/方法(constructor, componentWillMount, render), 组件在更新过程中会调 4 次钩子 (componentWillReceiveProps, shouldUpdate, componentWillUpdate), 总不能每个方法都用 try catch 包起来,这样会性能很差。而 constructor, render 是不可避免的,于是对三个 willXXX 动刀了。
在早期版本中,componentWillMount 与 componentWillReceiveProps 会做内部优化,执行多次 setState 都会延后到 render 时进行合并处理。因此用户就肆意 setState 了。这些 willXXX 还可以让用户任意操作 DOM。 操作 DOM 会可能 reflow,这是官方不愿意看到的。于是官方推出了 getDerivedStateFromProps,让你在 render 设置新 state,你主要返回一个新对象,它就主动帮你 setState。由于这是一个静态方法,你不能操作 instance,这就阻止了你多次操作 setState。由于没有 instance,也就没有http://instance.refs.xxx,你也没有机会操作 DOM 了。这样一来,getDerivedStateFromProps 的逻辑应该会很简单,这样就不会出错,不会出错,就不会打断 DFS 过程。
getDerivedStateFromProps 取代了原来的 componentWillMount 与 componentWillReceiveProps 方法,而 componentWillUpdate 本来就是可有可无,以前完全是为了对称好看。
在即使到来的异步更新中,reconciler 阶段可能执行多次,才执行一次 commit,这样也会导致 willXXX 钩子执行多次,违反它们的语义,它们的废弃是不可逆转的。
在进入 commi 阶段时,组件多了一个新钩子叫 getSnapshotBeforeUpdate,它与 commit 阶段的钩子一样只执行一次。
如果出错呢,在 componentDidMount/Update 后,我们可以使用 componentDidCatch 方法。于是整个流程变成这样:
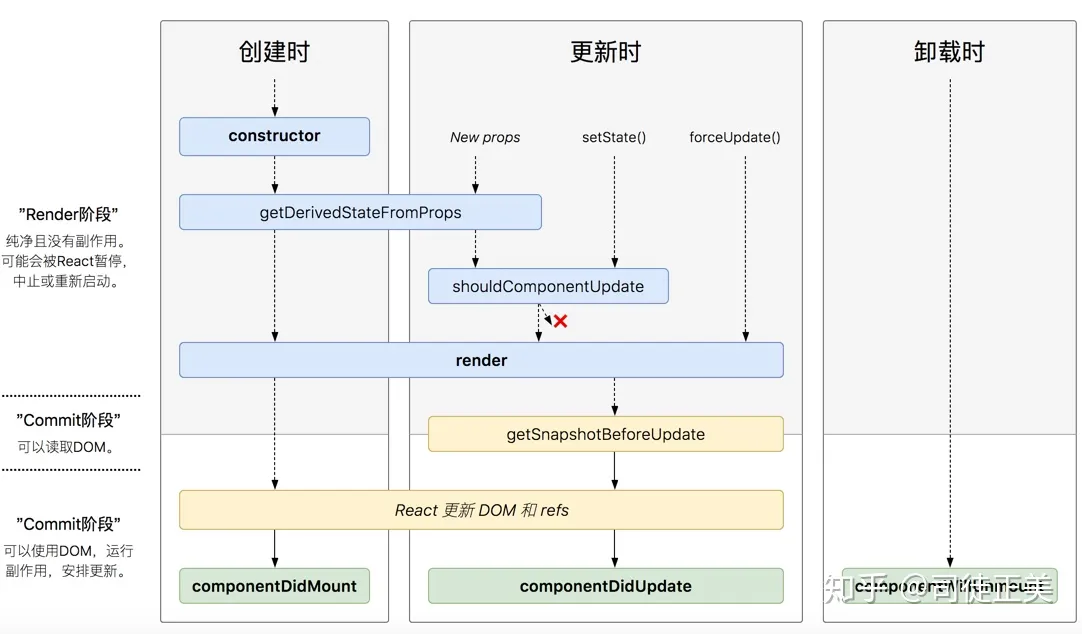
reconciler 阶段的钩子都不应该操作 DOM,最好也不要 setState,我们称之为***轻量钩子**。commit 阶段的钩子则对应称之为**重量钩子**。
任务系统
updateFiberAndView 是位于一个 requestIdleCallback 中,因此它的时间很有限,分给 DFS 部分的时间也更少,因此它们不能做太多事情。这怎么办呢,标记一下,留给 commit 阶段做。于是产生了一个任务系统。
每个 Fiber 分配到新的任务时,就通过位操作,累加一个 sideEffect。sideEffect 字面上是副作用的意思,非常重 FP 流的味道,但我们理解为任务更方便我们的理解。
每个 Fiber 可能有多个任务,比如它要插入 DOM 或移动,就需要加上 Replacement,需要设置样式,需要加上 Update。
怎么添加任务呢?
fiber.effectTag |= Update;
怎么保证不会重复添加相同的任务?
fiber.effectTag &= ~DidCapture;
在 commit 阶段,怎么知道它包含了某项任务?
if (fiber.effectTag & Update) {
/*操作属性*/
}
React 内置这么多任务,从 DOM 操作到 Ref 处理到回调唤起。。。

顺便说一下 anu 的任务名,是基于素数进行乘除。
https://github.com/RubyLouvre/anu/blob/master/packages/fiber/commitWork.js
无论是位操作还是素数,我们只要保证某个 Fiber 的相同性质任务只执行一次就行了。
此外,任务系统还有另一个存在意义,保证一些任务优先执行,某些任务是在另一些任务之前。我们称之为任务分拣。这就像快递的仓库管理一样,有了归类才好进行优化。比如说,元素虚拟 DOM 的插入移动操作必须在所有任务之前执行,移除操作必须在 componentWillUnmount 后执行。这些任务之所以是这个顺序,因为这样做才合理,都经过高手们的严密推敲,经过 React15 时代的大众验证。
Fiber 的连体婴结构
连体婴是一个可怕的名词,想想就不舒服,因为事实上 Fiber 就是一个不寻常的结构,直到现在我的 anujs 还没有很好实现这结构。Fiber 有一个叫 alternate 的属性,你们称之为备胎,替死鬼,替身演员。你也可以视它为 git 的开发分支,稳定没错的那个则是 master。每次 setState 时,组件实例 stateNode 上有一个_reactInternalFiber 的对象,就是 master 分支,然后立即复制一个一模一样的专门用来踩雷的 alternate 对象。
alternate 对象会接受上方传递下来的新 props,然后从 getDerivedStateFromProps 得到新 state,于是 render 不一样的子组件,子组件再 render,渐渐的,master 与 alternate 的差异越来越大,当某一个子组件出错,于是我们又回滚到该边界组件的 master 分支。
可以说,React16 通过 Fiber 这种数据结构模拟了 git 的三种重要操作, git add, git commit, git revert。
有关连体婴结构的思考,可以参看我另一篇文章《从错误边界到回滚到 MWI》,这里就不再展开。
中间件系统
说起中间件系统,大家可能对 koa 与 redux 里面的洋葱模型比较熟悉。
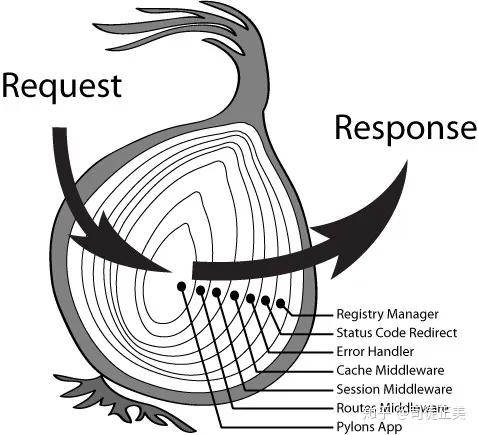
早在 React15 时代,已经有一个叫 Transaction 的东西,与洋葱模型一模一样。在 Transaction 的源码中有一幅特别的 ASCII 图,形象的解释了 Transaction 的作用。
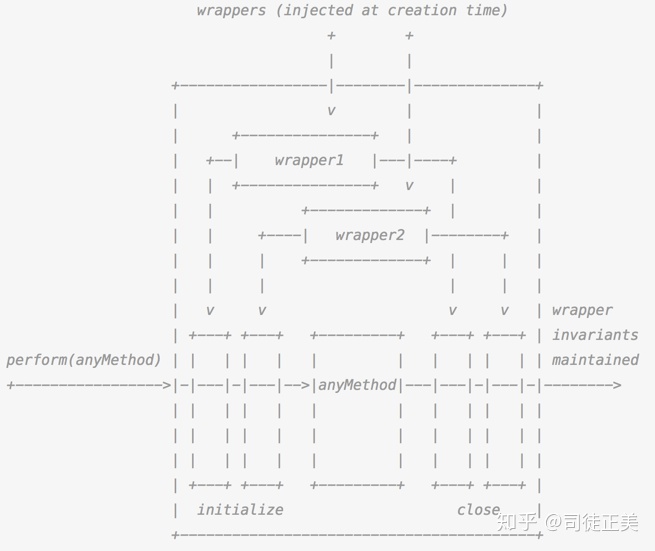
简单地说,一个 Transaction 就是将需要执行的 method 使用 wrapper 封装起来,再通过 Transaction 提供的 perform 方法执行。而在 perform 之前,先执行所有 wrapper 中的 initialize 方法;perform 完成之后(即 method 执行后)再执行所有的 close 方法。一组 initialize 及 close 方法称为一个 wrapper,从上面的示例图中可以看出 Transaction 支持多个 wrapper 叠加。
这个东西有什么用呢? 最少有两个用处,在更新 DOM 时,收集当前获取焦点的元素与选区,更新结束后,还原焦点与选区(因为插入新节点会引起焦点丢失,document.activeElement 变成 body,或者是 autoFocus,让焦点变成其他 input,导致我们正在输入的 input 的光标不见了,无法正常输入)。在更新时,我们需要保存一些非受控组件,在更新后,对非受控组件进行还原(非受控组件是一个隐涩的知识点,目的是让那些没有设置 onChange 的表单元素无法手动改变它的值)。当然了,contextStack, containerStack 的初次入栈与清空也可以做成中间件。中间件就是分布在 batchedUpdates 的两侧,一种非常易于扩展的设计,为什么不多用用呢!
总结
React Fiber 是对 React 来说是一次革命,解决了 React 项目严重依赖于手工优化的痛点,通过系统级别的时间调度,实现划时代的性能优化。鬼才般的 Fiber 结构,为异常边界提供了退路,也为限量更新提供了下一个起点。React 团队的人才济济,创造力非凡,别出心裁,从更高的层次处理问题,这是其他开源团队不可多见。这也是我一直选择与学习 React 的原因所在。
但是和所有人一样,我最初学习 React16 的源码是非常痛苦的。后来观看他们团队的视频,深刻理解时间分片与 Fiber 的链表结构后,渐渐明确整个思路,不需要对 React 源码进行断点调试,也能将大体流程复制出来。俗话说,看不如写(就是写 anujs,欢迎大家加 star, https://github.com/RubyLouvre/anu),与不如再复述出教会别人。于是便有了本文。