
案例:Istio
案例:Istio 化繁为简
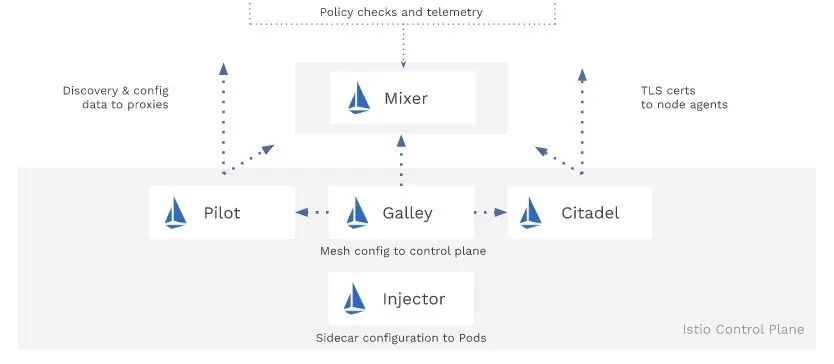
lstio 作为 Service Mesh(服务网格)领域最具权威的控制面,基本上提到服务网格,所有人都会不自觉地想到它,从 2017 年发布第一个版本以来,lstio 就有着一个堪称非常优雅的架构设计。服务网格整个系统分为数据面和控制面,前者通过同样是开源的智能代理组件 Envoy 负责进行流量处理。而之所以称之为智能,是因为 Envoy 相对比其它代理比如 Nginx 有着更丰富的治理能力和灵活的配置方式,并且支持各种插件可用于扩展流量治理能力;而控制面在网格系统里则根据功能职能的不同,被划分成以下 5 个核心组件:
-
Pilot:控制面的核心组件,负责对接 Envoy 数据面,也可以解析上层抽象出来的 lstio 配置,转换成数据面可以识别的 xDS 协议配置并分发到各个 Envoy;
-
Galley:为更好的解耦职责,它在 lstio 1.1 后由仅负责配置验证升级成了控制面的配置管理中心,可以对接不同注册中心,用于为服务网格提供配置输入能力;
-
Injector:在 K8s 体系里负责数据面的初始化相关工作,其中 lstio 的核心特性之一 Sidecar 自动注入正是依赖该组件;
-
Mixer:是 ilstio 里负责提供策略控制和遥测收集的组件,内部包含两个子组件 —— Telemetry 和 Policy,其中 Telemetry 前者负责监控相关的采集信息的数据聚合以用于对接各种监控后端,而 Policy 负责在服务相互调用过程中对请求进行策略检查,例如鉴权;
-
Citadel:负责服务网格里安全相关功能,为服务和用户提供认证和鉴权、管理凭据和 RBAC 等相关能力;
服务网格控制面各个组件被定义得清楚了然,设计之初就已经考虑到各种组件职责解耦、扩展性、安全性等,架构上看起来也非常清晰优雅。在这个架构设计中,究竟存在着什么样的难解之题,迫使 istio 开发团队在 istio 推出将近 3 年之时,决定推翻这个架构设计,重新用起“复古的”单体应用设计?
如果有人问 lstio 在回归单体架构设计后,谁最应该开香槟庆祝的话,我可能会不假思索的说是服务网格的运维人员,如果还要再加一类人,那必须算上 lstio 的开发人员。长期以来,服务网格的运维人员饱受折磨,而这种难言之苦,估计也只有 lstio 的开发同学才能感同深受,试想一下如下场景:正常非服务网格的环境下,当用户部署的一个应用出现调用异常时,只需要简单排查下这个应用自身以及被调用服务端即可,排除网络等基础组件异常的话,问题基本上跑不出这两个应用,原因自然也很容易被定位出来;
现在当用户的应用接入服务网格后,众所周知,在服务网格里的调用模型应该是如下图所示的:
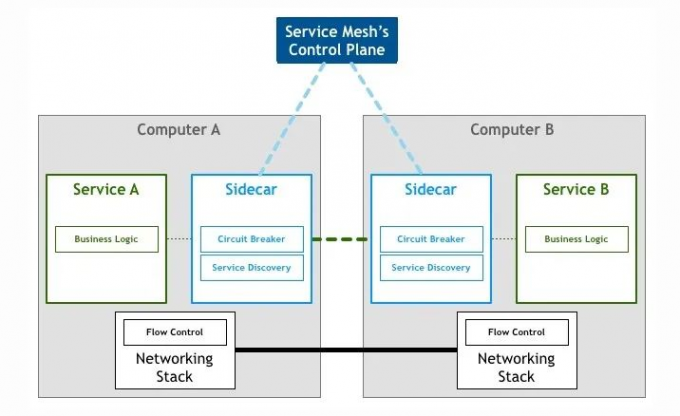
此时,如果业务出现调用异常,由于接入服务网格,问题处理人员要确认 lstio 系统是否正常工作,还记得之前介绍过的控制面组件吗,首先需要检查 pilot 是否正常工作,配置是否能下发到 sidecar,然后可能还要检查 galley 组件是否正常同步到服务实例信息,也有可能是 sidecar 注入问题,还需要检查 injector 组件是否正常工作…… 这还只是控制面的排查,涉及到数据面还可能需要排查 Envoy 日志等,不过这不是这次关注的点,暂且先不展开介绍。lstio 控制面的各个组件异常都可能会导致数据面在发起请求调用时出现问题,而控制面组件越多,意味着在排查问题的时候要检查的故障点越多,当然过多的组件设计导致部署难度会增加这点也是毋庸置疑。
在这这份公开的设计文档里,作者一开始便非常明确地提出 istiod 的设计目标:
- 降低安装复杂度。单一的二进制文件在安装部署时将会更加简单;
- 降低配置复杂度。之前的很大一部分配置文件是用于编排控制面组件,而单体化设计后这部分配置可以被移除,而且新版本的 Istiod 在配置上可能更精简,只需保留一个 mesh.yaml 文件,并且能提供最佳实践配置;
- 增加控制面可运维性。通过单体设计后的控制面在类似于金丝雀发布的多控制面场景里显得更加简单;不同的工作负载可以通过 namespace 或者 pod 上的标签设置(也可以是组合匹配)来选择对接不同的控制平面;
- 提高问题诊断能力。单个控制面组件意味着出了问题后无需在不同的组件间切换来切换去,排查各种问题,显然这有助于提升问题排查效率;
- 提高效率和响应速度。再也不用在各个组件间通过远程调用来传递数据,而且原本不同组件间需要共享的数据,现在也可以安全被共享,而且也会一定程度上加快控制面的启动速度;
- 消除不必要的耦合。通过把 Envoy 的启动配置生成移到控制面可以避免 pilot agent 的访问权限问题。(这个设计目标存在争议,有人提出 Envoy 的启动配置跟 pilot 或者 galley 没有直接关系应该单独出文档介绍,也有人认为作者的意图是指说将 injector 组件也合并入 Istiod 组件内)。
系统越简单,宕机时间越少。使用简单系统的船舶,更易于操作和理解,这使得它们易于修复,因此停机时间更少。考虑到船舶的“停机”可能是被困于千里之外,因此不停机这是一项重要的指标。
以船舶的转向系统为例,方向舵由金属杆向左或向右推动,这些杆通过液压移动,压力由液压泵控制,泵由来自驾驶室的电子信号控制,信号由自动驾驶仪控制。不需要火箭科学家或海军架构师,就可以找到问题的原因和解决方案:
- 如果自动驾驶仪出现故障,可以在驾驶室手动驾驶船舶。
- 如果电子信号故障,可以前往控制室手动控制泵,并通过简单的声控电话与桥交谈。
- 如果液压故障,请使用机械连接的紧急方向盘。
- 如果机械连接失败,可以用链条钩在舵的两侧,然后向所需方向拖!
像船运这样的初创公司承受不起系统故障的停顿。销售、市场营销、网络,客户支持、招聘、产品和其他系统的不正常,可能会对业务增长造成无法弥补的损害。
为什么简单性可以减少宕机时间
- 熟练系统所需时间更少
如果负责系统的人员离开、掉落、被车撞了或被拉入另一个项目,则另一个人可以在不需要太多学习或培训的情况下接手。这意味着可以有更多的人可以介入故障排除和修复工作。
例如,使用 Tableau 构建的分析仪表盘,可能比由定制脚本和 API 拼凑而成的分析仪表盘,有更多符合资格的人员来修复。谁都不想去找数据科学家或产品开发人员来修复一个条形图的小问题。
- 故障排除花费时间更少
如果一个系统中每个组件的行为与其他组件的关系易于理解,排查问题并找到损坏的组件(以及根本原因)就更加容易。
例如,如果一家公司在其网站上有许多可下载的白皮书,并且都被封闭在一个表格中(而不是为每个一个表格),那么如果下载白皮书,则他们仅需要对一种表格和一种自动化工作流程进行故障排除。
- 更多替代解决方案
当系统的每个部分都具有明确的功能时,更容易找到替代方案。
例如,假设有一个 Salesforce 流程,该流程使用大量自动化和第三方工具来对得分、筛选、分类和分配新的销售线索进行评分。如果出现问题,则没有明显的替代方法。一切将被搁置,直到该问题解决或被类似的复杂解决方案替代。
现在想象一下一个销售过程,在该过程中,销售团队会被简单地通知每个新的销售线索以及相关的详细信息,让他们决定是否跟进该线索。如果 Salesforce 通知步骤失败,很容易想出其他一百种方法来将这些信息发送给销售团队:报告,Slack 通知,列表导出,手动观察,或者使用 Zapier 通过几乎任何媒介发送警报。停机时间最多只能持续几分钟。
淘汰和替换项目是痛苦的,也具有破坏性,即使从长期看它的收益可观。许多初创公司(如轮船那样)一旦启航,就没有时间和资源进行大修。
以下是我评估或实施新系统时遵循的三个原则:
-
功能需求不能证明系统复杂的合理性。如果一个复杂的飞行控制系统导致整个机队停飞,或者像 Marketo 这样的企业营销平台导致无法进行市场营销活动,那么复杂的系统对大家有什么好处?选择易于操作的工具,而不是承诺最多功能的工具。我对初创企业的常见建议是选择 HubSpot 作为其营销平台,而不是诸如 Marketo,Eloqua 或 Pardot 之类的企业平台。
-
复杂的想法导致复杂的实现。如果解释或掌握一个想法花的时间太长,那么它的实现将会很复杂,并且当不可避免地发生问题时,修复它所需时间将会很长。例如,一个新提议的销售流程需要一个小时来作展示,那将是一场噩梦,无论它看起来多么强大。
-
先考虑修改,再考虑堆砌。当出现新需求时,常规的做法是在已有系统上堆砌新功能。但是,可以尝试看下修改原有系统的核心是否可以满足新需求。与前文提到 Marketo 到 HubSpot 的迁移方案,短期可能会导致更长的(计划内)停机时间,但长期来看(计划外)停机时间会更少。