
BIO
BIO
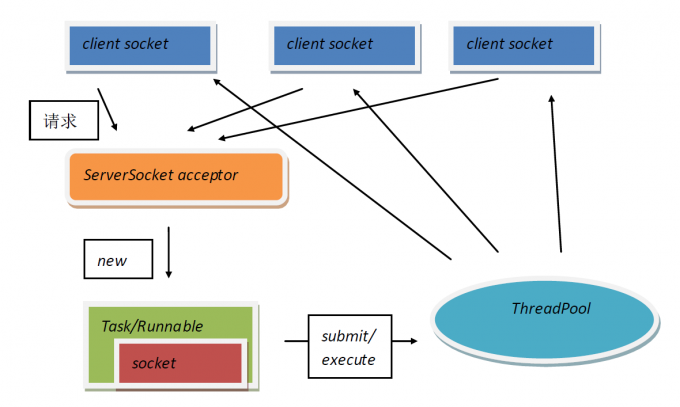
采用
还有一些并不是由于并发数增加而导致的系统负载增加:连接服务器的一些客户端,由于网络或者自身性能处理的问题,接收端从
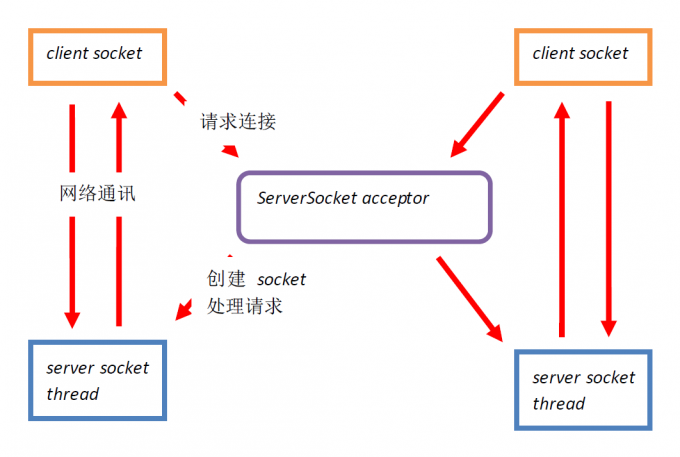
多进程/ 多线程模式

多线程模式出现要晚一些,线程与进程相比更轻量,而且线程之间是共享内存堆栈的,所以不同的线程之间交互非常容易实现。比如聊天室这样的程序,客户端连接之间可以交互,比聊天室中的玩家可以任意的其他人发消息。
用多线程模式实现非常简单,线程中可以直接读写某一个客户端连接。而多进程模式就要用到管道、消息队列、共享内存实现数据交互,统称进程间通信
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(9696);
Socket socket = serverSocket.accept();
new Thread(() -> {
try {
byte[] byteRead = new byte[1024];
socket.getInputStream().read(byteRead);
String req = new String(byteRead, StandardCharsets.UTF_8);//encode
// do something
byte[] byteWrite = "Hello".getBytes(StandardCharsets.UTF_8);//decode
socket.getOutputStream().write(byteWrite);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
} catch (IOException e) {
e.printStackTrace();
}
}
多进程
- 创建一个
socket ,绑定服务器端口(bind) ,监听端口(listen) ,在PHP 中用stream_socket_server 一个函数就能完成上面3 个步骤,当然也可以使用php sockets 扩展分别实现。 - 进入
while 循环,阻塞在accept 操作上,等待客户端连接进入。此时程序会进入随眠状态,直到有新的客户端发起connect 到服务器,操作系统会唤醒此进程。accept 函数返回客户端连接的socket - 主进程在多进程模型下通过
fork(php: pcntl_fork) 创建子进程,多线程模型下使用pthread_create(php: new Thread) 创建子线程。下文如无特殊声明将使用进程同时表示进程/ 线程。 - 子进程创建成功后进入
while 循环,阻塞在recv(php: fread) 调用上,等待客户端向服务器发送数据。收到数据后服务器程序进行处理然后使用send(php: fwrite) 向客户端发送响应。长连接的服务会持续与客户端交互,而短连接服务一般收到响应就会close 。 - 当客户端连接关闭时,子进程退出并销毁所有资源。主进程会回收掉此子进程。
Leader-Follow 模型
上文描述的多进程

它的特点是程序启动后就会创建
- 这种模型严重依赖进程的数量解决并发问题,一个客户端连接就需要占用一个进程,工作进程的数量有多少,并发处理能力就有多少。操作系统可以创建的进程数量是有限的。
- 启动大量进程会带来额外的进程调度消耗。数百个进程时可能进程上下文切换调度消耗占
CPU 不到1% 可以忽略不接,如果启动数千甚至数万个进程,消耗就会直线上升。调度消耗可能占到CPU 的百分之几十甚至100% 。
另外有一些场景多进程模型无法解决,比如即时聊天程序