
术语概念
Functional Programming
越靠下表示背离传统命令式语言更远
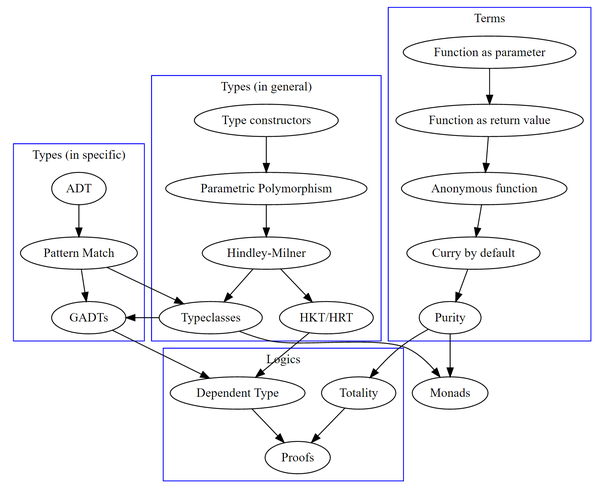
Functional Programming(函数式编程)
> 函数式编程初探——阮一峰 > > 函数式编程
诞生 50 多年之后,函数式编程(functional programming)开始获得越来越多的关注。不仅最古老的函数式语言 Lisp 重获青春,而且新的函数式语言层出不穷,比如 Erlang、clojure、Scala、F#等等。目前最当红的 Python、Ruby、Javascript、Java,对函数式编程的支持都很强,就连老牌的面向对象的 Java、面向过程的 PHP,都忙不迭地加入对匿名函数的支持。越来越多的迹象表明,函数式编程已经不再是学术界的最爱,开始大踏步地在业界投入实用。也许继"面向对象编程"之后,“函数式编程"会成为下一个编程的主流范式(paradigm)。未来的程序员恐怕或多或少都必须懂一点。
Terms
Side Effects
在计算机科学与技术中,一个函数或者一个表达式被称为有副作用,常常发生在如下几种情况:
- 修改了部分状态,譬如某个函数修改了全局变量、静态变量、某些传入的参数、引发了一个异常
- 返回了一个类似于 Observable 对象
- 与外部产生了交互,譬如读写文件、发起网络请求或者调用其他包含副作用的方程
在一个具有副作用的函数中,一个程序的行为往往依赖于上下文与历史记录。
Mutable VS Immutable(可变对象与不可变对象)
顾名思义,不可变对象就是在创建之后其状态不可以再被修改的对象。引用 Effective Java 这本书中的一句话:> Classes should be immutable unless there’s a very good reason to make them mutable….If a class cannot be made immutable, limit its mutability as much as possible.1. Immutable 降低了 Mutable 带来的复杂度可变(Mutable)数据耦合了 Time 和 Value 的概念,造成了数据很难被回溯。比如下面一段代码:function touchAndLog(touchFn) { let data = { key: 'value' }; touchFn(data); console.log(data.key); // 猜猜会打印什么?}在不查看 touchFn 的代码的情况下,因为不确定它对 data 做了什么,你是不可能知道会打印什么(这不是废话吗)。但如果 data 是 Immutable 的呢,你可以很肯定的知道打印的是 value。1. 节省内存 Immutable.js 使用了 Structure Sharing 会尽量复用内存,甚至以前使用的对象也可以再次被复用。没有被引用的对象会被垃圾回收。import { Map} from 'immutable';let a = Map({ select: 'users', filter: Map({ name: 'Cam' })})let b = a.set('select', 'people');a === b; // falsea.get('filter') === b.get('filter'); // true上面 a 和 b 共享了没有变化的 filter 节点。1. Undo/Redo,Copy/Paste,甚至时间旅行这些功能做起来小菜一碟因为每次数据都是不一样的,只要把这些数据放到一个数组里储存起来,想回退到哪里就拿出对应数据即可,很容易开发出撤销重做这种功能。后面我会提供 Flux 做 Undo 的示例。1. 并发安全传统的并发非常难做,因为要处理各种数据不一致问题,因此聪明人发明了各种锁来解决。但使用了 Immutable 之后,数据天生是不可变的,并发锁就不需要了。然而现在并没什么卵用,因为 JavaScript 还是单线程运行的啊。但未来可能会加入,提前解决未来的问题不也挺好吗?1. 拥抱函数式编程 Immutable 本身就是函数式编程中的概念,纯函数式编程比面向对象更适用于前端开发。因为只要输入一致,输出必然一致,这样开发的组件更易于调试和组装。像 ClojureScript,Elm 等函数式编程语言中的数据类型天生都是 Immutable 的,这也是为什么 ClojureScript 基于 React 的框架 — Om 性能比 React 还要好的原因。
High-Order Function(高阶函数)
在数学和计算机科学中,高阶函数是至少满足下列一个条件的函数:
-
接受一个或多个函数作为输入
-
输出一个函数
在数学中它们也叫做算子(运算符)或泛函。微积分中的导数就是常见的例子,因为它映射一个函数到另一个函数。在无类型 lambda 演算,所有函数都是高阶的;在有类型 lambda 演算(大多数函数式编程语言都从中演化而来)中,高阶函数一般是那些函数型别包含多于一个箭头的函数。在函数式编程中,返回另一个函数的高阶函数被称为 Curry 化的函数。在很多函数式编程语言中能找到的 map 函数是高阶函数的一个例子。它接受一个函数 f 作为参数,并返回接受一个列表并应用 f 到它的每个元素的一个函数。
定义
简单说,“函数式编程"是一种“编程范式”(programming paradigm),也就是如何编写程序的方法论。它属于“结构化编程”的一种,主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式:> (1 + 2) _ 3 - 4 传统的过程式编程,可能这样写:> var a = 1 + 2;> > var b = a _ 3;> > var c = b - 4;函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:> var result = subtract(multiply(add(1,2), 3), 4);这就是函数式编程。
特点
函数式编程具有五个鲜明的特点。
1. 函数是"第一等公民”
所谓“第一等公民”(first class),指的是函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
举例来说,下面代码中的 print 变量就是一个函数,可以作为另一个函数的参数。
> var print = function(i){ console.log(i);}; > > [1,2,3].forEach(print);
2. 只用"表达式”,不用"语句"
“表达式”(expression)是一个单纯的运算过程,总是有返回值;“语句”(statement)是执行某种操作,没有返回值。函数式编程要求,只使用表达式,不使用语句。也就是说,每一步都是单纯的运算,而且都有返回值。
原因是函数式编程的开发动机,一开始就是为了处理运算(computation),不考虑系统的读写(IO)。“语句"属于对系统的读写操作,所以就被排斥在外。
当然,实际应用中,不做 IO 是不可能的。因此,编程过程中,函数式编程只要求把 IO 限制到最小,不要有不必要的读写行为,保持计算过程的单纯性。
3.函数是无状态、无副作用的
所谓“副作用”(side effect),指的是函数内部与外部互动(最典型的情况,就是修改全局变量的值),产生运算以外的其他结果。
函数式编程强调没有"副作用”,意味着函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其是不得修改外部变量的值。
而无状态性则主要依赖于递归,
上一点已经提到,函数式编程只是返回新的值,不修改系统变量。因此,不修改变量,也是它的一个重要特点。
在其他类型的语言中,变量往往用来保存"状态"(state)。不修改变量,意味着状态不能保存在变量中。函数式编程使用参数保存状态,最好的例子就是递归。下面的代码是一个将字符串逆序排列的函数,它演示了不同的参数如何决定了运算所处的"状态"。
> function reverse(string) { > > if(string.length == 0) { > > return string; > > } else { > > return reverse(string.substring(1, string.length)) + string.substring(0, 1); > > } > > }
由于使用了递归,函数式语言的运行速度比较慢,这是它长期不能在业界推广的主要原因。
5. 引用透明
引用透明(Referential transparency),指的是函数的运行不依赖于外部变量或"状态",只依赖于输入的参数,任何时候只要参数相同,引用函数所得到的返回值总是相同的。
有了前面的第三点和第四点,这点是很显然的。其他类型的语言,函数的返回值往往与系统状态有关,不同的状态之下,返回值是不一样的。这就叫"引用不透明",很不利于观察和理解程序的行为。
优点
1. 代码简洁,开发快速
函数式编程大量使用函数,减少了代码的重复,因此程序比较短,开发速度较快。
Paul Graham 在《黑客与画家》一书中写道:同样功能的程序,极端情况下,Lisp 代码的长度可能是 C 代码的二十分之一。
如果程序员每天所写的代码行数基本相同,这就意味着,“C 语言需要一年时间完成开发某个功能,Lisp 语言只需要不到三星期。反过来说,如果某个新功能,Lisp 语言完成开发需要三个月,C 语言需要写五年。“当然,这样的对比故意夸大了差异,但是"在一个高度竞争的市场中,即使开发速度只相差两三倍,也足以使得你永远处在落后的位置。”
2. 接近自然语言,易于理解
函数式编程的自由度很高,可以写出很接近自然语言的代码。
前文曾经将表达式(1 + 2) * 3 - 4,写成函数式语言:
> subtract(multiply(add(1,2), 3), 4)
对它进行变形,不难得到另一种写法:
> add(1,2).multiply(3).subtract(4)
这基本就是自然语言的表达了。再看下面的代码,大家应该一眼就能明白它的意思吧:
> merge([1,2],[3,4]).sort().search(“2”)
因此,函数式编程的代码更容易理解。
3. 更方便的代码管理与结果的可缓存
函数式编程不依赖、也不会改变外界的状态,只要给定输入参数,返回的结果必定相同。因此,每一个函数都可以被看做独立单元,很有利于进行单元测试(unit testing)和除错(debugging),以及模块化组合。
实际上,我们在函数式编程中进行构建的是实体与实体之间的关系。在这种意义上,lisp 虽然不是纯粹的函数式编程,但是也算是函数式编程一员。使用这种定
义,大多数提供了原生的 list 支持的脚本语言也可以算混合了函数式语言的功能,但是这不是函数式语言的精髓。知其然,还要知其所以然。我们既然已经有了
精确自然的命令式编程,又为什么还需要函数式编程呢?我们举个小例子。
int fab(int n) {
return n == 1 || n == 2 ? 1 : fab(n - 1) + fab(n - 2);
}
这是用 C 语言写的求斐波那契数列的第 N 项的程序,相应的 Haskell 代码是这样的:
fab::(Num a) => a -> a
fab n = if n == 1 || n == 2 then 1 else fab(n - 1) + fab(n - 2)
看
上去差不多对不对?但是这两个程序在执行的效率方面有着天差地别的差距。为什么呢?C 语言是标准的命令式编程语言。因此对于你写下的每一行语句,C 程序会
原封不动地机械地去执行。如果想效率提高,你必须自己去分析程序,去人工地减少程序中执行的语句的数量。具体到这个 C 程序,我们注意到在每次函数调用时,
都会产生两个新的函数调用。这时,实际产生的函数调用的数目是指数级别的!比方说,我们写 fab(5),实际的执行结果是:
fab(5)
fab(4)
fab(3)
fab(2)
fab(1)
fab(2)
fab(3)
fab(2)
fab(1)
我们看到,fab(3)被求值了两遍。为了计算 fab(5),我们实际执行了 8 次函数调用。
那么函数式语言呢?我们说过,函数式语言里面是没有变量的。换句话说,所有的东西都是不变的。因此在执行 fab(5)的时候,过程是这样的:
fab(5)
fab(4)
fab(3)
fab(2)
fab(1)
fab(3)
总
共只有五次应用。注意我说的是应用而不是调用。因为函数式语言里的函数本意并不是命令式语言里面的“调用”或者“执行子程序”的语义,而是“函数与函数之
间的关系”的意思。比如 fab 函数中出现的两次 fab 的应用,实际上说明要计算 fab 函数,必须先计算后续的两个 fab 函数。这并不存在调用的过程。因为
所有的计算都是静态的。haskell 可以认为所有的 fab 都是已知的。因此实际上所有遇到的 fab 函数,haskell 只是实际地计算一次,然后就缓存
了结果。
本质上,这代表了我们提供给函数式语言的程序其实并不是一行一行的“命令”,而只是对数据变换的说明。这样函数式语言可以深入这
些说明中,寻找这些说明中冗余的共性,从而进行优化。这就是函数式语言并不需要精心设计就会比命令式语言高效的秘密。命令式语言当然也可以进行这种优化,
但是因为命令式语言是有边界效应的。而且大部分情况下都是利用边界效应进行计算,因此很难推广这种优化,只有少数几种窥孔优化能取得效果。
放
到这个例子上,因为本质上我们两次的 fab 应用是重叠的。haskell 发现了这个特点,于是将两次 fab 的结果缓存下来(注意,能缓存结果的必要条件是
这个函数返回的值是不会变的!而这是函数式语言主要的特性)。如果后续的计算需要用到这两次 fab 的结果,就不需要再次重复计算,而只是直接提取结果就可
以了。这就是上面几乎完全一样的两个程序效率相差如此之大的主要原因。
4. 易于"并发编程”
函数式编程不需要考虑"死锁"(deadlock),因为它不修改变量,所以根本不存在"锁"线程的问题。不必担心一个线程的数据,被另一个线程修改,所以可以很放心地把工作分摊到多个线程,部署"并发编程"(concurrency)。
请看下面的代码:
> var s1 = Op1(); > > var s2 = Op2(); > > var s3 = concat(s1, s2);
由于 s1 和 s2 互不干扰,不会修改变量,谁先执行是无所谓的,所以可以放心地增加线程,把它们分配在两个线程上完成。其他类型的语言就做不到这一点,因为 s1 可能会修改系统状态,而 s2 可能会用到这些状态,所以必须保证 s2 在 s1 之后运行,自然也就不能部署到其他线程上了。
多核 CPU 是将来的潮流,所以函数式编程的这个特性非常重要。
5. 代码的热升级
函数式编程没有副作用,只要保证接口不变,内部实现是外部无关的。所以,可以在运行状态下直接升级代码,不需要重启,也不需要停机。Erlang语言早就证明了这一点,它是瑞典爱立信公司为了管理电话系统而开发的,电话系统的升级当然是不能停机的。
Reactive Programming(响应式编程)
> - Wiki-Reactive_programming > - The introduction to Reactive Programming you’ve been missing – 中文版 > - reactive-programming-using-rxjava-and-akka
从定义上来说,维基百科提供了如下的定义:
> Reactive programming is a programming paradigm oriented around data flows and the propagation of change
响应式编程式一种面向数据流与变化传播的编程范式。通俗来说,响应式编程就是面向异步数据流的一种编程方式。响应式编程的原则可以看做是并发编程原则以及异步系统原则的一种组合。响应式编程可以看做高级编程范式面向于需要处理分布式状态以及编排异步数据流的一种自然扩展。一般来说,响应式编程的原则如下:
- Responsive & Fault-tolerant: 应用程序应当能够快速地响应用户,即使在高负载以及存在错误的情况下。
- Resilient and Scalable: The application should be resilient, in order to stay responsive under various conditions. They also should react to changes in the input rate by increasing or decreasing the resources allocated to service these inputs. Today’s applications have more integration complexity, as they are composed of multiple applications.
- Message Driven: A message-drivenarchitecture is the foundation of scalable, resilient, and ultimately responsive systems.
响应式编程是一种面向异步数据流的编程模型。在实际的编程实现中,响应式编程往往有两种方式,一个是类似于 Scala 中提供的 Actor 模型,另一个就是基于扩展的函数式响应编程模型。
Functional Reactive Programming
> - functional-reactive-programming