
调度模型
Go 线程与调度模型
目前 Go 运行时的实现默认并不会并行执行代码,它只为用户层代码提供单一的处理核心。任意数量的协程都可能在系统调用中被阻塞,而在任意时刻默认只有一个会执行用户层代码。若你希望 CPU 并行执行,就必须告诉运行时你希望同时有多少协程能执行代码。有两种途径可意识形态,要么在运行你的工作时将 GOMAXPROCS 环境变量设为你要使用的核心数,要么导入 runtime 包并调用 runtime.GOMAXPROCS(NCPU)。runtime.NumCPU() 的值可能很有用,它会返回当前机器的逻辑 CPU 核心数。当然,随着调度算法和运行时的改进,将来会不再需要这种方法。
系统栈
每个系统级线程都会有一个固定大小的栈(一般默认可能是 2MB),这个栈主要用来保存函数递归调用时参数和局部变量。固定了栈的大小导致了两个问题:一是对于很多只需要很小的栈空间的线程来说是一个巨大的浪费,二是对于少数需要巨大栈空间的线程来说又面临栈溢出的风险。针对这两个问题的解决方案是:要么降低固定的栈大小,提升空间的利用率;要么增大栈的大小以允许更深的函数递归调用,但这两者是没法同时兼得的。
Go 的栈是动态分配大小的,随着存储数据的数量而增长和收缩。每个新建的 Goroutine 只有大约 4KB 的栈。每个栈只有 4KB,那么在一个 1GB 的 RAM 上,我们就可以有 256 万个 Goroutine 了,相对于 Java 中每个线程的 1MB,这是巨大的提升。Golang 实现了自己的调度器,允许众多的 Goroutines 运行在相同的 OS 线程上。就算 Go 会运行与内核相同的上下文切换,但是它能够避免切换至 ring-0 以运行内核,然后再切换回来,这样就会节省大量的时间。
调度模型
在 Go 中存在两级调度:
- 一级是操作系统的调度系统,该调度系统调度逻辑处理器占用 CPU 时间片运行;
- 一级是 Go 的运行时调度系统,该调度系统调度某个 Goroutine 在逻辑处理上运行。
使用 Go 语句创建一个 Goroutine 后,创建的 Goroutine 会被放入 Go 运行时调度器的全局运行队列中,然后 Go 运行时调度器会把全局队列中的 Goroutine 分配给不同的逻辑处理器(P),分配的 Goroutine 会被放到逻辑处理器(P)的本地队列中,当本地队列中某个 Goroutine 就绪后待分配到时间片后就可以在逻辑处理器上运行了。
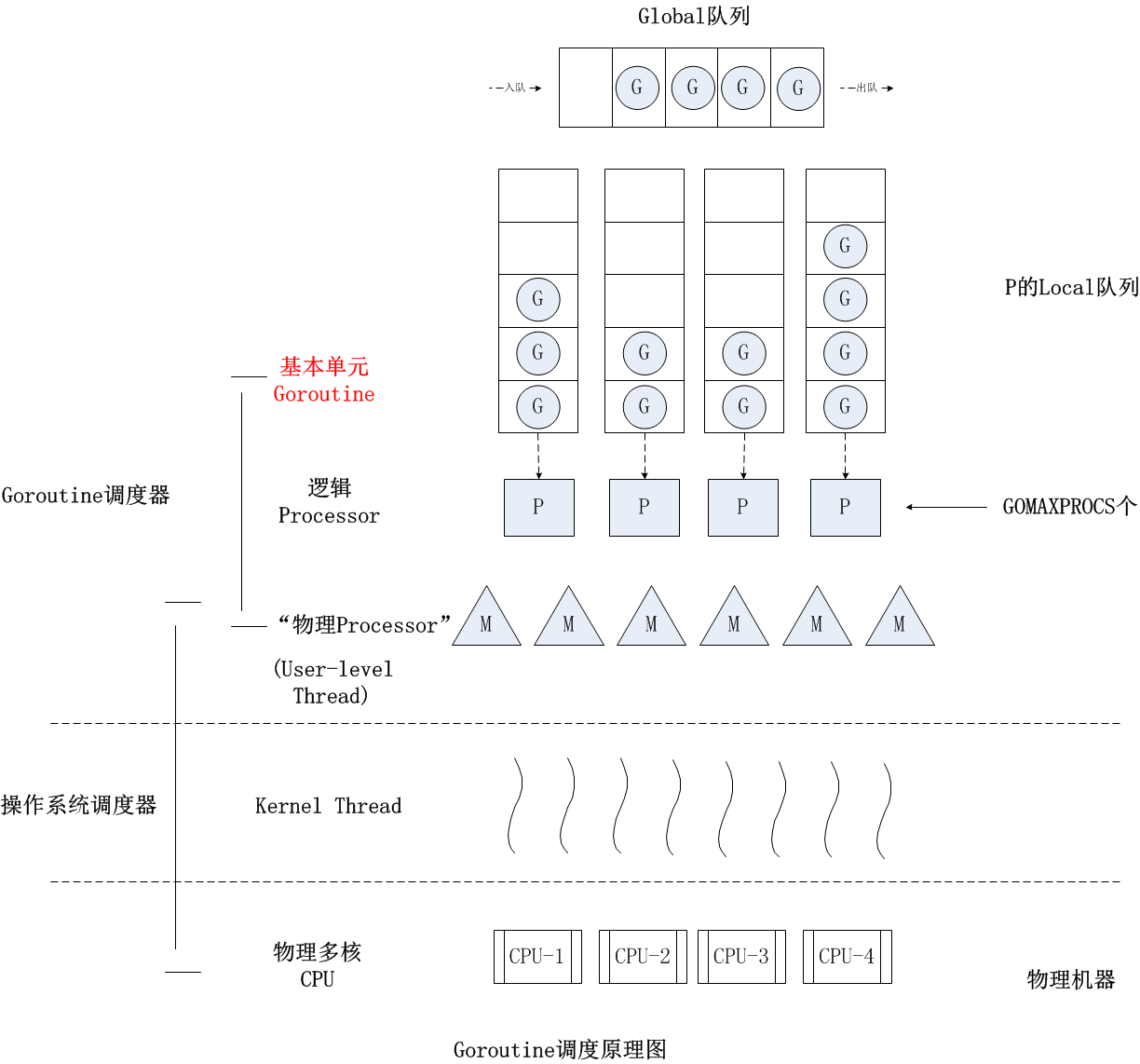
从 G-M 到 G-P-M
在 Go 1.0 发布的时候,它的调度器其实 G-M 模型,也就是没有 P 的,调度过程全由 G 和 M 完成,这个模型暴露出一些问题:
- 单一全局互斥锁(Sched.Lock)和集中状态存储的存在导致所有 goroutine 相关操作,比如:创建、重新调度等都要上锁;
- goroutine 传递问题:M 经常在 M 之间传递可运行的 goroutine,这导致调度延迟增大以及额外的性能损耗;
- 每个 M 做内存缓存,导致内存占用过高,数据局部性较差;
- 由于 syscall 调用而形成的剧烈的 worker thread 阻塞和解除阻塞,导致额外的性能损耗。
这些问题导致 Go1.0 虽然号称原生支持并发,却在并发性能上一直饱受诟病,然后,重新设计和实现了 Go 调度器(在原有的 G-M 模型中引入了 P)并且实现了一个叫做 work-stealing 的调度算法:
- 每个 P 维护一个 G 的本地队列;
- 当一个 G 被创建出来,或者变为可执行状态时,就把他放到 P 的可执行队列中;
- 当一个 G 在 M 里执行结束后,P 会从队列中把该 G 取出;如果此时 P 的队列为空,即没有其他 G 可以执行,M 就随机选择另外一个 P,从其可执行的 G 队列中取走一半。
G-P-M 调度模型
Go 线程模型属于多对多线程模型,在操作系统提供的内核线程之上,Go 搭建了一个特有的两级线程模型。Go 中使用使用 Go 语句创建的 Goroutine 可以认为是轻量级的用户线程,Go 线程模型包含三个概念:
-
G: 表示 Goroutine,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。G 并非执行体,每个 G 需要绑定到 P 才能被调度执行。
-
P: Processor,表示逻辑处理器,对 G 来说,P 相当于 CPU 核,G 只有绑定到 P(在 P 的 local runq 中)才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等,P 的数量决定了系统内最大可并行的 G 的数量(物理 CPU 核数 >= P 的数量),P 的数量由用户设置的 GOMAXPROCS 决定,但是不论 GOMAXPROCS 设置为多大,P 的数量最大为 256。
-
M: Machine,OS 线程抽象,代表着真正执行计算的资源,在绑定有效的 P 后,进入 schedule 循环;M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。
在 Go 中每个逻辑处理器(P)会绑定到某一个内核线程上,每个逻辑处理器(P)内有一个本地队列,用来存放 Go 运行时分配的 goroutine。多对多线程模型中是操作系统调度线程在物理 CPU 上运行,在 Go 中则是 Go 的运行时调度 Goroutine 在逻辑处理器(P)上运行。
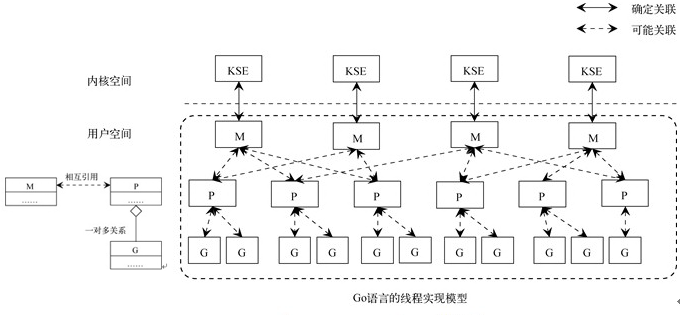
调度过程
需要注意的是为了避免某些 Goroutine 出现饥饿现象,被分配到某一个逻辑处理器(P)上的多个 Goroutine 是分时在该逻辑处理器运行的,而不是独占运行直到结束,比如每个 Goroutine 从开始到运行结束需要 10 分钟,那么当前逻辑处理器下的 goroutine1,goroutine2,goroutine3,并不是顺序执行,而是交叉并发运行的。
Goroutine 内部实现与在多个操作系统线程(OS 线程)之间复用的协程(coroutines)一样。如果一个 Goroutine 阻塞 OS 线程,例如等待输入,则该 OS 线程对应的逻辑处理器 P 中的其他 Goroutine 将迁移到其他 OS 线程,以便它们可以继续运行:
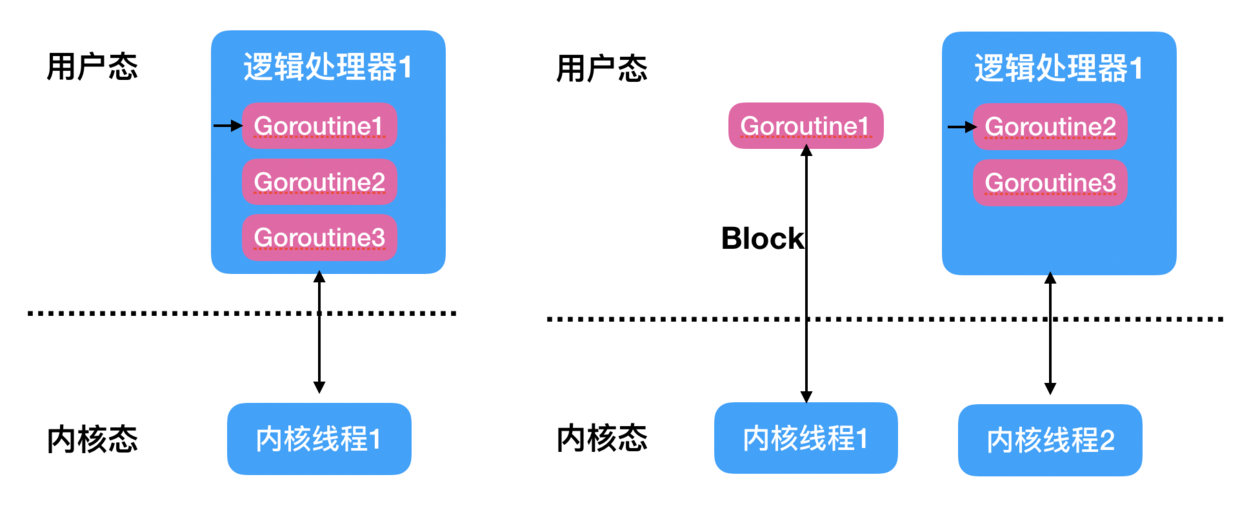
如上图左侧假设 goroutine1 在执行文件文件读取操作,则 goroutine1 会导致内核线程 1 阻塞,这时候 Go 运行时调度器会把 goroutine1 所在的逻辑处理器 1 迁移到其他的内核线程上(这里是内核线程 2 上),这时候逻辑处理器 1 上的 goroutine2 和 goroutine3 就不会受 goroutine1 的影响了。等 goroutine1 文件读取操作完成后 goroutine1 又会被 Go 运行时调度系统重新放入到逻辑处理器 1 的本地队列。
默认情况下,Go 默认是给每个可用的物理处理器都分配一个逻辑处理器(P),如果你需要修改逻辑处理器(P)个数可以使用 runtime 包的 runtime.GOMAXPROCS 函数设置。至于 goroutine(G)的数量则是由用户程序自己来确定,理论只要内存够大,可以无限制创建。