
ThreadPoolExecutor
ThreadPoolExecutor
Executors 工厂生产的主要是 ThreadPoolExecutor, 例如 newCachedThreadPool, newFixedThreadPool, 以及 newScheduledThreadExecutor 方法返回的都是 ThreadPoolExecutor 实例。ThreadPoolExecutor 支持用户自定义。如果默认的 Executors 工厂默认生产的 ThreadPoolExecutor 的执行策略不能满足需求,则可以定制自己的策略。Executors 创建线程池方法本质上都是使用了 ThreadPoolExecutor,因为这些创建线程池的静态方法都是返回 ThreadPoolExecutor 对象,和我们手动创建 ThreadPoolExecutor 对象的区别就是我们不需要自己传构造函数的参数。ThreadPoolExecutor 的构造函数共有四个,但最终调用的都是同一个:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
构造函数参数说明:
- corePoolSize => 线程池核心线程数量
- maximumPoolSize => 线程池最大数量
- keepAliveTime => 空闲线程存活时间
- unit => 时间单位
- workQueue => 线程池所使用的缓冲队列
- threadFactory => 线程池创建线程使用的工厂
- handler => 线程池对拒绝任务的处理策略
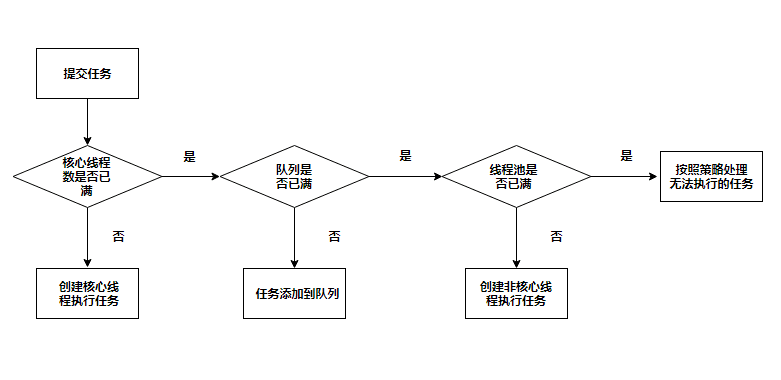
执行逻辑说明:
- 判断核心线程数是否已满,核心线程数大小和
corePoolSize参数有关,未满则创建线程执行任务 - 若核心线程池已满,判断队列是否满,队列是否满和
workQueue参数有关,若未满则加入队列中 - 若队列已满,判断线程池是否已满,线程池是否已满和
maximumPoolSize参数有关,若未满创建线程执行任务 - 若线程池已满,则采用拒绝策略处理无法执执行的任务,拒绝策略和
handler参数有关
ThreadPoolExecutor 最常用的构造方法如下:
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
线程数目的控制
其中 corePoolSize,maximumPoolSize 以及 KeepAliveTime 决定着线程池中线程的创建和消亡。
- corePoolSize 为正常情况下线程池中线程的数量。
- maximumPoolSize 为线程池线程数量的上限,当提交给线程池中得任务数量过多时线程池会临时创建新的工作线程来执行这些任务,但保证线程池中线程的总量不会超过 maximumPoolSize。
- keepAliveTime 表示当线程池中的线程数量超过了 corePoolSize 的时候,如果一个线程的闲置时间超过了 keepAliveTime 那么这个线程就有可能被消灭(TimeUnit 为 keepAliveTime 的单位)。
合理的配置这三个参数可以保证线程池“弹性”,当任务请求量大的时候线程池中的线程数量会扩大到 maximumPoolSize 来提高线程池的吞吐量。而当请求量不是很大的时候线程池大小有又可以减少到 corePoolSize 来保证不会有更多的空闲线程浪费系统资源。以 newFixedThreadPool 方法为例:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
Executors 中的 newCachedThreadPool 方法
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
可以看到 newCachedThreadPool 生成的线程池最大线程数量没有限制,默认线程池数量为 0,keepAliveTime 为 60 秒,并且任务队列采用的是 SynchronousQ(这个后面会讲),这样的配置使得线程池具有很大的伸缩性,当长时间没有任务请求的时候线程池中线程数量会逐步减少保证不会有多余的空闲线程存在,当任务请求频率急速增加时,线程池会创建更多的工作线程来保证线程池的吞吐量,对于混合任务的执行这种线程池有很大的优势。
任务队列
线程池基于生产消费者模式,提交任务的活动为生产者,处理任务的工作线程为消费者,实现这种工作模式就需要一个阻塞队列来承载提交执行的任务,工作线程从队列中获取提交的任务来执行。这种生产消费者模式可以保证如果线程池中工作线程的数量有限,那么可以保证并发执行任务的数量,相比于提交一个任务立马分配一个线程的模式,这种方式可以保证系统资源不会因为大量的请求而耗尽。
可以在构造 ThreadPoolExecutor 的时候向它的构造方法中传入一个阻塞 Q 来定制化持有任务的队列。如果使用 Executors 的 newFixedThreadPool 方法创建 ThreadPoolExecutor 默认传入是一个无界的 LinkedBlockingQ,使用一个无界限的任务队列会有一些风险,如果当工作线程很忙碌的时候,任务队列就会急速膨胀消耗系统资源。如果使用一个有界的阻塞 Q 可以防止资源被耗尽的风险,但也会因任务提交过与频繁而造成任务提交请求阻塞。
一个大的任务队列配合一个小的线程池可以有效的提高 CPU,内存的利用率以及减少上下文的切换,使得工作线程一直处于忙碌的状态。对于一个无界的线程池,可以使用 SynchronousQ 来代替一般的阻塞 Q,SynchronousQ 与一般的阻塞队列不大相同,SynchronousQ 是一种线程之间传递的机制,一个线向 SynchronousQ 中提交任务的前提是必须有一个线程已经等待好接受这个提交,即每个 put 必须等待一个 take,这个队列中并不会存储任务而是简单的做一个传递。这种机制适合于等待线程无限的情况,否则一旦没有工作线程在等待提交,向 SynchronousQ 放入数据就会触发饥饿策略-Saturation Policy(稍后会介绍)拒绝任务的提交。使用 SynchronousQ 的好处在于,它的响应及时,要么任务立即被工作线程执行,要么就抛出异常给生产者,不会出现阻塞的情况。
Executors 的 newCachedThreadPool 方法创建的线程池就是采用的 SynchronousQ 作为任务队列,SynchronousQ 的性能比普通的阻塞 Q 要好很多,所以 newCachedThreadPool 创建出的线程池的性能比 newFixedThreadPool 创建的线程池的性能更好。有界的线程池以及有界的工作队列适用于:
-
执行的任务为同一种类。
-
任务与任务之间不存在相互依赖。
对于上述两种情况有界的队列可能会产生饥饿死锁的情况,如果出现了这两种情况则可以使用 newCachedThreadPool 创建的线程池来防止饥饿死锁的情况发生。
饥饿策略
当线程池中的工作线程忙碌,且任务队列充满的时候,如果在有新的任务提交到线程池就会触发饥饿策略。与任务队列相似,ThreadPoolExecutors 的构造函数支持用户传入自定义的饥饿策略实现,JDK 提供的饥饿策略实现有 AbortPolicy,CallerRunsPolicy,DiscardPolicy 以及 DiscardOldestPolicy。ThreadPoolExecutor 默认使用的是 AbortPolicy。
AbortPolicy
当触发饥饿策略时候,AbortPolicy 会抛出一个 unchecked 异常 RejectedExecutionException,调用方可以捕获这个异常来进行定制化处理。
// 线程池默认使用的是abortPolicy, 现在将任务持有的Q大小设置为1,说明等待的任务最有只能有一个
// ,如果等待任务超过一个则会触发abortPolicy,abortPolicy会抛出异常
ExecutorService executorService =
new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(1));
executorService.submit(()-> {
SleepUtil.sleepSeconds(10);
System.out.println("task 1");
});
executorService.submit(()-> {
System.out.println("task 2");
});
executorService.submit(()-> {
System.out.println("task 3");
});
DiscardPolicy
DiscardPolicy 会放弃执行新提交的任务而不会抛出异常。DiscardOldestPolicy 会放弃下一个要执行的任务然后重新提交新任务,需要注意的是如果任务队列使用的是 priorityBlockingQ 那么就会将执行优先级最高的任务放弃,所以使用这种策略需要谨慎。
CallerRunsPolicy
CallerRunsPolicy 既不会放弃任务也不会抛出异常,而是将提交的任务的执行工作反推给提交的线程,这样可以减缓任务提交的速度,提交线程由于需要自己来执行任务而无法快速的将新的任务推送给线程池。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
可以看出当任务队列充满之后并有什么方法可以阻塞新任务的提交,如果想实现这种策略可以使用 Semaphore。将 permits 设置为与任务队列大小一致,提交任务之前先到 Semaphore 中获取 permit,任务执行完毕之后释放 permit,当 permits 数量为 0 时,阻塞任务提交等待任务执行完毕释放 permit。
public class BoundedExecutor {
private final Executor executor;
private final Semaphore semaphore;
public BoundedExecutor(Executor executor, Semaphore semaphore) {
this.executor = executor;
this.semaphore = semaphore;
}
public void submitTask(final Runnable command) throws InterruptedException {
// 提交任务之前,先获取semaphore,当semaphore数量为0时,方法阻塞,等待任务执行结束释放,这样可以保证提交任务的数量
semaphore.acquire();
try {
executor.execute(
() -> {
try {
command.run();
} finally {
semaphore.release();
}
}
);
} catch (RejectedExecutionException e) {
semaphore.release();
}
}
}
ThreadPoolExecutor 扩展
生命周期
ThreadPoolExecutor 提供 beforeExecute,afterExecute 以及 terminated 三个方法以供子类扩展,beforeExecute 以及 afterExecute(无论任务是正常被执行完毕或是抛出异常)分别在工作线程执行任务前后被调用,这两个方法可以被用来添加统计任务执行时间。terminated 在线程池关闭时被调用,这个方法可以用来做一些资源的清理。
public class TimingThreadPool extends ThreadPoolExecutor {
private final ThreadLocal<Long> startTime = new ThreadLocal<>();
private final Logger logger = Logger.getLogger("TimingThreadPool");
private final AtomicLong numTasks = new AtomicLong();
private final AtomicLong totalTime = new AtomicLong();
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
logger.fine(String.format("Thread %s: start %s", t, r));
startTime.set(System.nanoTime());
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
try {
long end = System.nanoTime();
long taskTime = end - startTime.get();
// 记录任务的执行数量
numTasks.incrementAndGet();
// 记录任务的执行时间
totalTime.addAndGet(taskTime);
logger.fine(
String.format("Thread %s: end %s, time=%dns", t, r, taskTime)
);
} finally {
super.afterExecute(r, t);
}
}
@Override
protected void terminated() {
try {
// 打印每个任务执行的平均时间
logger.info(
String.format(
"Terminated: avg time=%dns",
totalTime.get() / numTasks.get()
)
);
} finally {
super.terminated();
}
}
}
线程工厂
线程池中的工作线程都是通过线程工厂来创建的,同样的 ThreadPoolExecutor 支持自定义线程工厂来创建定制化的线程。如果你想定制线程的 UncaughtExecptionHandler 或者想在线程中加入一些日志打印功能或者想定制化线程的名字让你在 dump 文件中可以更直观的找到这个线程,那么就可以定制线程工厂来实现你的需求。线程工厂接口中只有一个方法:
public interface ThreadFactory {
Thread newThread(Runnable r);
}
可以通过实现这个接口来定制线程工厂。