
04.运行时
Java 程序执行
Java 遵循一次编写、到处运行的理念,即设计一个面向 Java 语言特性的虚拟机,并通过编译器将 Java 程序转换成该虚拟机所能识别的指令序列,也称 Java 字节码,使其可以在不同平台的虚拟机实现里运行。之所以取名字节码,也是因为 Java 字节码指令的操作码(opcode)被固定为一个字节。C 程序编译而成的机器码就是一个个的字节:
0x00: 55 push rbp
0x01: 48 89 e5 mov rbp,rsp
0x04: 48 83 ec 10 sub rsp,0x10
0x08: 48 8d 3d 3b 00 00 00 lea rdi,[rip+0x3b]
; 加载 "Hello, World!\n"
0x0f: c7 45 fc 00 00 00 00 mov DWORD PTR [rbp-0x4],0x0
0x16: b0 00 mov al,0x0
0x18: e8 0d 00 00 00 call 0x12
; 调用 printf 方法
0x1d: 31 c9 xor ecx,ecx
0x1f: 89 45 f8 mov DWORD PTR [rbp-0x8],eax
0x22: 89 c8 mov eax,ecx
0x24: 48 83 c4 10 add rsp,0x10
0x28: 5d pop rbp
0x29: c3 ret
最左列是偏移,中间列是给虚拟机读的机器码,最右列是给人读的代码。
0x00: b2 00 02 getstatic java.lang.System.out
0x03: 12 03 ldc "Hello, World!"
0x05: b6 00 04 invokevirtual java.io.PrintStream.println
0x08: b1 return
从虚拟机视角来看,执行 Java 代码首先需要将它编译而成的 class 文件加载到 Java 虚拟机中;加载后的 Java 类会被存放于方法区(Method Area)中。实际运行时,虚拟机会执行方法区内的代码。Java 虚拟机会将栈细分为面向 Java 方法的 Java 方法栈,面向本地方法(用 C++ 写的 native 方法)的本地方法栈,以及存放各个线程执行位置的 PC 寄存器。在运行过程中,每当调用进入一个 Java 方法,Java 虚拟机会在当前线程的 Java 方法栈中生成一个栈帧,用以存放局部变量以及字节码的操作数。这个栈帧的大小是提前计算好的,而且 Java 虚拟机不要求栈帧在内存空间里连续分布。当退出当前执行的方法时,不管是正常返回还是异常返回,Java 虚拟机均会弹出当前线程的当前栈帧,并将之舍弃。
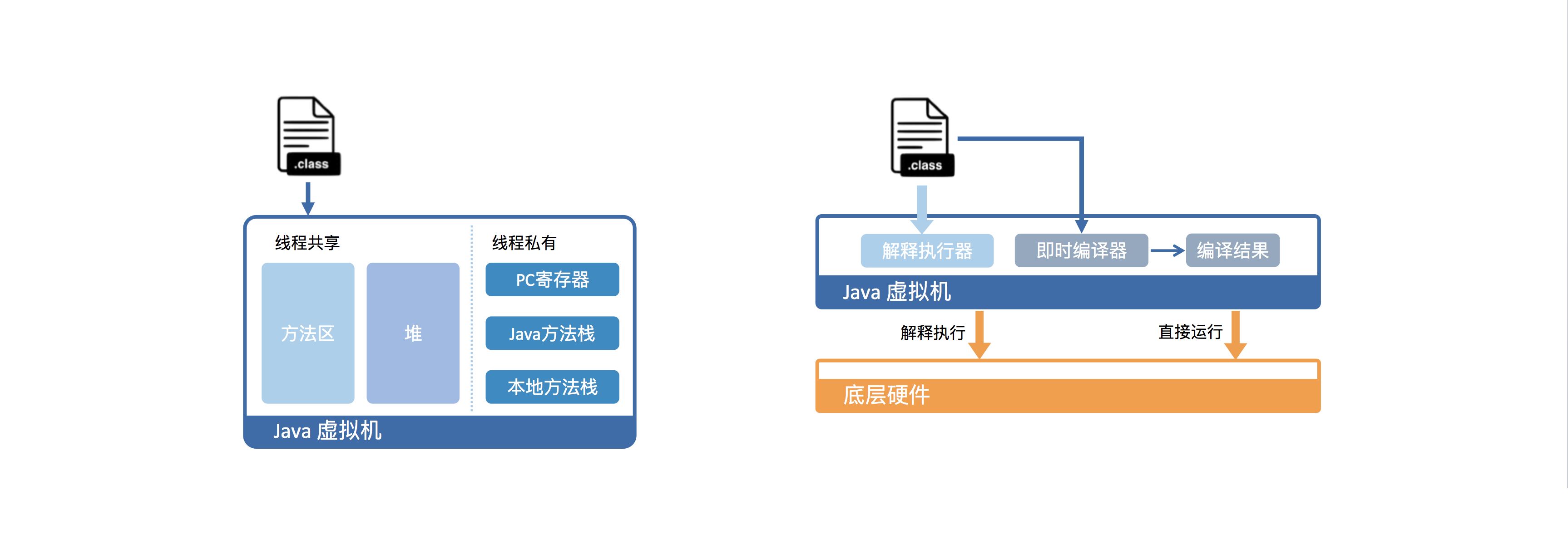
在字节码翻译的过程中,支持两种执行方式:解释执行与即时编译(Just-In-Time compilation,JIT),解释执行即逐条将字节码翻译成机器码并执行;即时编译即将一个方法中包含的所有字节码编译成机器码后再执行。即时编译建立在程序符合二八定律的假设上,也就是百分之二十的代码占据了百分之八十的计算资源。对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。
理论上讲,即时编译后的 Java 程序的执行效率,是可能超过 C++ 程序的。这是因为与静态编译相比,即时编译拥有程序的运行时信息,并且能够根据这个信息做出相应的优化。举个例子,我们知道虚方法是用来实现面向对象语言多态性的。对于一个虚方法调用,尽管它有很多个目标方法,但在实际运行过程中它可能只调用其中的一个。这个信息便可以被即时编译器所利用,来规避虚方法调用的开销,从而达到比静态编译的 C++ 程序更高的性能。
HotSpot 内置了多个即时编译器:C1、C2 和 Graal,以满足不同用户场景的需要。C1 又叫做 Client 编译器,面向的是对启动性能有要求的客户端 GUI 程序,采用的优化手段相对简单,因此编译时间较短。C2 又叫做 Server 编译器,面向的是对峰值性能有要求的服务器端程序,采用的优化手段相对复杂,因此编译时间较长,但同时生成代码的执行效率较高。从 Java 7 开始,HotSpot 默认采用分层编译的方式:热点方法首先会被 C1 编译,而后热点方法中的热点会进一步被 C2 编译。
JVM 运行时
在 java -version 命令中,我们能够了解当前的 JVM 类型与工作模式:
第三行的输出中可以看到:JVM 的名字(HotSpot)、类型(Client)和 build ID(24.79-b02)。除此之外,我们还知道 JVM 以混合模式(mixed mode)在运行,这是 HotSpot 默认的运行模式,意味着 JVM 在运行时可以动态的把字节码编译为本地代码。我们也可以看到类数据共享(class data sharing)是开启(即第三行最后的 sharing)的。类数据共享(class data sharing)是一种在只读缓存(在 jsa 文件中,”Java Shared Archive”)中存储 JRE 的系统类,被所有 Java 进程的类加载器用来当做共享资源,它可能在经常从 jar 文档中读所有的类数据的情况下显示出性能优势。
-Xcomp 代表编译模式(compiled mode),与它(-Xint)正好相反,JVM 在第一次使用时会把所有的字节码编译成本地代码,从而带来最大程度的优化。这听起来不错,因为这完全绕开了缓慢的解释器。然而,很多应用在使用-Xcomp 也会有一些性能损失,但是这比使用-Xint 损失的少,原因是-Xcomp 没有让 JVM 启用 JIT 编译器的全部功能。因此在上图中,我们并没有看到-Xcomp 比-Xmixed 快多少。
-Xmixed 代表混合模式(mixed mode),前面也提到了,混合模式是 JVM 的默认工作模式。它会同时使用编译模式和解释模式。**对于字节码中多次被调用的部分,JVM 会将其编译成本地代码以提高执行效率;而被调用很少(甚至只有一次)的方法在解释模式下会继续执行,从而减少编译和优化成本。**JIT 编译器在运行时创建方法使用文件,然后一步一步的优化每一个方法,有时候会主动的优化应用的行为。这些优化技术,比如积极的分支预测(optimistic branch prediction),如果不先分析应用就不能有效的使用。这样将频繁调用的部分提取出来,编译成本地代码,也就是在应用中构建某种热点(**即 HotSpot,**这也是 HotSpot JVM 名字的由来)。**使用混合模式可以获得最好的执行效率**。
那么,Client JVM 和 Server JVM 到底在哪些方面不同呢?当虚拟机运行在-client 模式的时候,使用的是一个代号为 C1 的轻量级编译器, 而-server 模式启动的虚拟机采用相对重量级,代号为 C2 的编译器. C2 比 C1 编译器编译的相对彻底,服务起来之后,性能更高。-Server VM 启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升。
很明显,Client VM 的编译器没有像 Server VM 一样执行许多复杂的优化算法,因此,它在分析和编译代码片段的时候更快。而 Server VM 则包含了一个高级的编译器,该编译器支持许多和在 C++编译器上执行的一样的优化,同时还包括许多传统的编译器无法实现的优化。
从 J2SE 5.0 开始,当一个应用启动的时候,加载器会尝试去检测应用是否运行在 “server-class” 的机器上,如果是,则使用 Java HotSpot Server Virtual Machine (server VM)而不是 Java HotSpot Client Virtual Machine (client VM)。这样做的目的是提高执行效率,即使没有为应用显式配置 VM。下面这张图展示了各个平台的默认的 JVM(注意:—代表不提供该平台的 JVM ):
